我遇到的字符编码的那些坑
我遇到的字符编码的那些坑
如图创建utf8.c源文件并以utf-8编码保存

编译运行后把文件拷到windows用UE打开并查看其16进制值
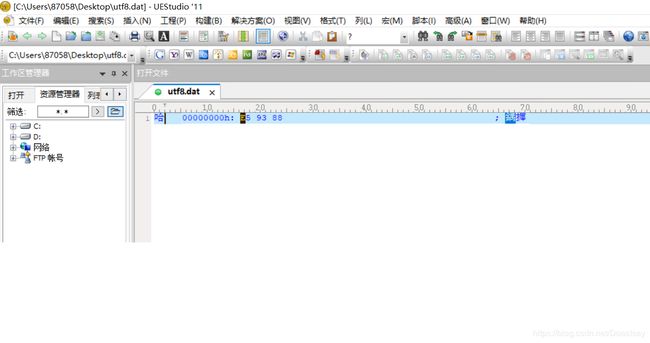
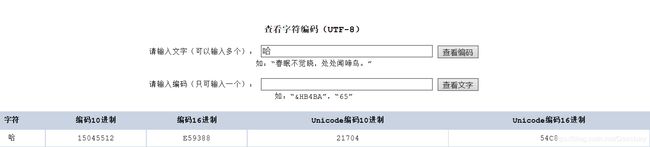
查看哈字的UTF-8 16进制编码值,可以看到,utf8.dat,中的哈字是以UTF-8编码保存的,占用了3个字节
如图创建gb18030.c源文件并以gb18030编码保存
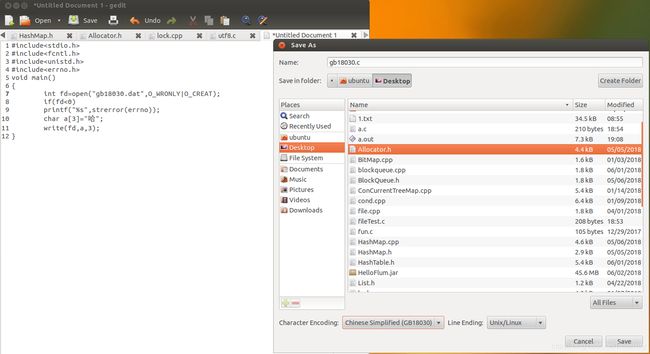
同样的套路
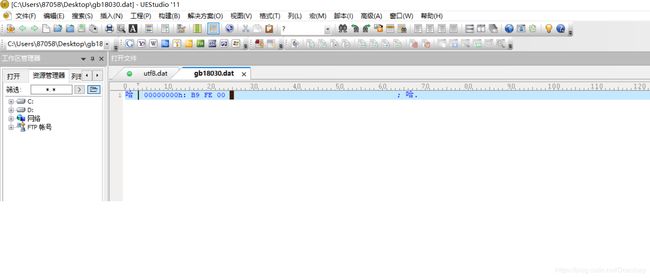
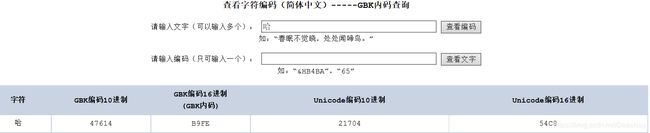
可以发现gbk18030.dat 中哈字是以gbk编码保存的,gbk编码只用了2个字节
我们可以简单粗爆的得出一个可能是错误但又可能是事实的一个结论,c语言中源文件中的字符串常量是以源文件的字符编码编码的(python,java也是的但是会解码成unicode再放到字节码中)这个结论可能看起来有点显而易见,但如果没思考过,没测试过,我还真tn不知道啊
测试代码中是直接使用linux系统调用来写文件的,没有标准IO库的,二进制模式打开,文本模式打开文件之分,无论那种方式实质都是调用write写的一个个字节。区别是你写一个int类型的1,要4字节,用文本编辑器打开,无法查看,需要去解析。一个char类型的‘1’,要1字节,只要你有正确的编码,最终,文本编辑器还是能识别出正确的字符编码并展示出来
在C语言中,你的源代码保存的什么字符编码,那么源代码中的字符串常量就是什么字符编码,你向文件写什么就是什么,你从文件读什么就是什么,,但在Python,java中读写文本就不同了 ,它经常会背着你搞些小动作,也不是背啦,如果你知道就是明目涨胆,只能说它们的函数封装的都太历害了,,,
以前搞c语言时,如果只在本机测试玩玩,那有什么字符编码问题啊,在我第一次用Python时遇到字符编码的问题时,我这样想
问题1:
我遇到的第一个问题当然是这样,在Python 2中我在py文件中写进了中文字符它就会报如下错误SyntaxError: Non-ASCII character '\xb9' in file gbk.py on line 4, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
然后我们会查下资料,在源文件中开头加入#coding:gbk 或#coding:utf-8告诉解释器我这个是xxx编码的,你用这个xxx字符编码去把字符串解码成unicode,这个xxx编码要设定成py文件保存时的字符编码
问题2
我遇到的第二个问题当然是这样,在处理字符串时有时会进行字符串拼接,当我不小心,(其实有时候我根本不知道我正在使用的串是str串还是unicode串),拼接了一个unicode串与str串时就遇到了如下错误,
UnicodeDecodeError: 'ascii' codec can't decode byte 0xb9 in position 0: ordinal not in range(128)
当在Python2中str串与unicode串拼接时会把str串按defaultencoding去解码成unicode串,而在python2中defaultencoding是ascii,要避免出现这种解码错误我们要在与unicode串拼接时先把str串按正确的编码解码成unicode串,或把unicode串编码成str串再拼接,或者使用sys.setdefaultencoding,把默认字符编码设成你处理的str的编码,就可以随便拼接字符串了
问题3
我遇到的第三个问题当然是这样,在Python2中用open打开文件,read读出来的就是str,write写str写进去的也是str,这点和C语言倒一样,但如果你要写unicode串,那么报歉不行,它会把unicode串编码成defaultencoding,再写进去。这时如果你写的有中文,如果你没把defaultencoding设成你想要输出文件的字符编码,就又会出现这个异常
UnicodeEncodeError: 'ascii' codec can't encode character u'\u54c8' in position 0: ordinal not in range(128)
问题4
我遇到的第四个问题当然是这样,在,Python2中你用code.open以指定的字符编码打开文件,read读出来的就是解码后的unicode,write unicode时会把unicode编码成打开文件时指定的编码,write str时可能又会遇到问题2,此时str会以defa ultencoding被解码成unicode,再把unicode编码成打开文件时指定的编码。这时如果你写的有中文,如果你没把defaultencoding设成你想要输出文件的字符编码,就会又出现问题2这个异常UnicodeDecodeError: 'ascii' codec can't decode byte 0xb9 in position 0: ordinal not in range(128)
这几个问题对于一个python新手来说,时常让人摸不到头脑,就字符串操作这点java比python好多了,至少java不会背着你搞太多解码编码的的操作,你要搞,你就光明正大,堂堂正正的搞啊
问题5
我遇到的第五个问题当然是这样
Windows BOM头的坑
用java在windows写了一个小工具,这个小工具,会读取一个配置,把配置解析成String的key ,value放到map中,测试中怎么搞都有这样一个问题,有一个key找不到,但遍历map又能遍历到这个key,value,开始以为是java的HashMap有问题,测啊测,最后把key一个字节一个字节的print出来发现第一个key多了3个字节,EF BB BF,用UE打开配置文件16进制查看,看到文件开头也有这3个字节,百度一下这3个字节原来是BOM头,用记事本打开另存为无BOM UTF8搞定,哈哈。或者修改代码,打开文件后先读取3字节,如果是EFBBBF则丢弃,正常情况下这3个字节不会对程序造成影响,这3个字节是不会被展示出来的,我们用文本编辑器是看不到这3个字节的,但是一旦涉及到字符串比较就会有问题,,,
问题6
我遇到的第六个问题当然是这样,
我们使用过一个叫Ambari的东西,这个玩意中有很多脚本是用Python2写的,即然是用Python2写的怎么会没有字符编码的问题?
那天我们在文德路6号大院,下班了,我看小F还没有想走的意思,我就跑过去
我:老铁还不走?
F:你不是搞过Python?来看看我这是怎么了。
我:略懂,略懂,,,
哎哟,字符编码的问题,我想,TMD。
嗯嗯,看看日志,系统重启,加载配置时出问题了,哈哈,解码异常,
你做了什么操作?
F:改了下配置,重启了下Ambari
我:哦,这样啊,(这句台词是跟我大H哥学的,每当我不想理别人的时候,或听不懂别人在说什么的时候,我就会说,这样啊),
两个人79=86 37=21,瞎j8乱搞一通,这样,这样,不对,是那样那样,最后发现通过Ambari管理界面,修改完配置后,配置会在Ambari管理节点生成而后上传到被管理集群的各个节点上去(是这样?记不清了)
问题来了,一个文件从一个服务器跑到另一个服务器,基于我遇到的以上四种Python编码问题,我当时就觉得,服务器间操作系统的字符编码可能不一样
我:你看下管理节点也就是生成配置文件的服务器与启动失败报错的服务器的操作系统的字符编码是不是一样的
F:不是一样的
我:哦,那你把管理节点服务器操作系统的字符编码改成启动失败报错的服务器的操作系统的字符编码,重新改下配置,当他在改字符编码期间,我开始洋洋得意的开始猜测,肯定是这样纸的啦,有人在Ambari服务启动后修改了管理节点服务器操作系统的字符编码,所以修改了配置后配置文件的字符编码就变了,当你再次重启Ambari服务并重启整个集群时,就出现了字符编码问题
F:改好了集群还是启不来呀,还报这个错
我:什马,这样啊,那你继续加班吧,弟弟我先退下了
哈,哈,哈,哈,啪,啪,啪,分分钟打脸
第二天
我:老铁,那个问题解决了?
F:什么问题?
我:就是那个字符编码的问题
F:好了
我:什马?怎么搞的
F:重启了下Ambari服务
我:哦,这样啊,原来是这样啊,我开启事后小诸葛模式,已经启动的进程,在启动时已经把,操作系统的环境变量拷贝到,自己的进程空间了,我们修改完操作系统的环境变量后,是需要重启进程才能获取最新的环境变量,哎,F这点常识你都不懂,搞什么啊。
问题7
我遇到的第七个问题当然是这样,
一天维护的同事电我,说什么,分隔符中的$符号被吃了,入库失败,文件大量积压,我一看,你,你,你去找协议解析的,肯定是它们那边数据有问题,给了我们乱码的数据,导致文件乱码,我的程序没问题,我们的程序怎么会有问题?我的程序什么都没做呀,对这个字段,我的程序怎么会把这个$符号吃掉?
事情是这样的
我们有个C++程序,这个程序负责把一个结构体中的各个字段取出来,格式化成一个以$[sb]为分隔符的C字符串,然后把这个字符串写到kafka。这个结构体中有一个字段是一个char数组,里面存放的是以gb18030编码的中文字符串,所以最后拼出来的这个字符串就是一个以gb18030编码的字符串。。。???
因为gbk编码是兼容ascii编码的,所以我们敢号称我们写进kafka的这条数据是以gb18030编码的字符串,或叫它字节数组。
然后,我们有很多Java程序会从kafka中拉这条数据,获取到这条数据后它们都二话不说,new String(byte[],”gb18030”) 去解码,生成一个unicode编码的String对象,然后以$[sb]为分隔符分隔字符串,然后进行相应业务处理。这没问题啊,这。这是没问题,但是,当这条数据不是以gb18030编码的字符串或者说C语言结构体中那个char数组中保存的不是以gb18030编码的字符串,它就是一坨二进制的东西,会出现什么问题?一般情况也不会出问题,但小概率事件,总还是会发生的。由于这个字符串本身不是以gb18030编码的,所以当解码成unicode时,char数组中的最后一个字节就与分隔符中的$做为一个gbk字符编码组成两个字节去转换成unicode字符编码了,
为啥唯独char数组中的最后一个字节与分隔符中的$符号会被当成一个2字节的gbk编码?
再啰嗦一下哈,因为gbk与ascii 是兼容的,从char数组中的第一个字节,直致char数组的到数第二个字节,都能以一字节,或两字节组合转换成unicode,又刚好char数组中的最后一个字节大于127,所以解码时会再取一个字节,把这两个字节当作一个gbk编码,去转换成unicode,,接下来的字节又都是小于127的ascii字符了,所以,最后这条数据少了一个分隔符导致数据错位了
这种问题怎么处理?
这种问题在c,python,中很好办,处理它不必把它转换成unicode再去处理(python是个神奇的语言,无论是unicode串,还是gbk串你都可以‘’.split(‘$[sb]’)去分隔它,所以有时候你根本不知道你正在操作的字符串是以什么编码的,接下来又会变成什么),因为字节数组不会被重新解析组合生成新的unicode字节数组,所以分隔符不会被吃掉。C++程序格式化出的这个字符串,处理时只要不去转码,以ascii码的方式去处理它,直接按$[sb]还是可以正确分隔字符串的,除非你运气差到了极点,刚好这个char数组中有四个字节,刚好是$ [ s b ] 而它们又恰好在一起组成了我们的分隔符,如果运气真被到了这个点,那么我们还是可以转义的。如果要转码只需转char数组中的内容就可以了,然后再把各个字段以$[sb]为分隔符拼到一起,你就可以对别人说我这是以XXX编码的字符串了,在Java 中你可能要搞个分隔byte数组的函数了,,,,
问题8
这个问题来自一个已经运行了很多年的C++程序,当我第一次遇到这个问题时,我对别人说那你就不要在配置文件中配中文路径啊
然后我第二次遇到这个问题,我又对别人说,
我:那你就不要在配置文件中配中文路径啊,
他:这个文件夹我们无权修改,只能这样,
我:嗯,嗯,那,那,好,好,我这边看一下吧,
我就想为啥英文路径就没问题?
然后我在配置文件中配入中文路径,把配置文件保存成操作系统的字符编码,试了下,唉,成功了,,,
在配置英文路径时我从来没关注过,操作系统是什么字符编码,配置文件是什么字符编码
我去查找gbk,gb2312,gb18030,utf8,ascii的相关资料,并测试。原来,gbk,utf8都是兼容ascii的,当在gbk编码中一个字节大于127,才会用2字节去表示一个gbk字符,在utf8中当字节的第一个bit是0时表示是ascii字符,当第一个bit为1时,后面有几个bit是1,就代表,接下来将要读取几个字节去表示一个字符,因此当配置文件中只有键盘上的那些字符时,无论它的字符编码是什么,都是小于127的一个字节一个字节的ascii字符
然后我就想为在什么配置文件配中文时会出现这个问题?
其实对于C语言我们从文本配置文件中读一行数据,这一行到底是个什么?
C字符串,对,就是一个以‘/0’结尾的char数组,你写进去什么,读出来就是什么,我们写一个gbk编码的有中文的字符串写的是什么?其实就是把char数组中的字节从用户空间拷到内核空间文件系统的缓冲区再拷到磁盘,那么读出来的也是从磁盘拷到文件系统的缓冲区,再拷到用户空间我们的char数组中,此间操作系统老老实实的,对于那串gbk编码的字节数组一点操作都没有,仅仅只是拷贝,拷贝。那为何拿一个有中文的gbk编码的字节数组当做参数,传给一个linux 的系统调用,会出现找不到文件路径的错误?然后我又把配置文件改成操作系统的字符编码utf8,又完全没问题了,,,?????
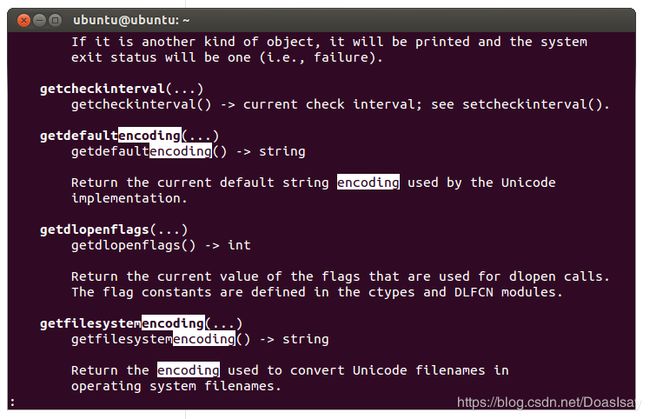
从Python的两个关于字符编码的接口先来看一下,python的sys模块中有一个方法getfilesystemencoding()当你在python中用unicode的文件名做参数去调用如:open,write,listdir,walk,这种与操作文件相关的方法时,python会用这个编码把unicode编码成str串,再把这个str传递给操作系统的open,write等接口,但是如果你在代码中用一个gbk编码的中文串做文件名,在一个以utf8为系统字符编码的操作系统创建一个文件,那么你在另一块代码中用一个utf8编码的中文串做文件名去访问这个文件,是找不到这个文件的,java中你基本上都是用一个unicode编码的String去操作,当然不会有这种问题,在c语言中如果你喜欢,你可以随时随地轻而易举的,从图片,视频中扣几个字节,然后在结尾加个‘\0’,以此为文件名去创建一个文件
像python,java这种以unicode做为中间编码去保存字节码的语言都会在把unicode编码的字符串编码为操作系统默认的字符编码的字符串后再把这个字符串传递给操作系统的接口
另一个方法getdefaultencoding(),如果在python中打开文件写文件,如果没如果没指定字符编码的话,写unicode到文件中就会保存为这个字符编码
在操作系统中编辑保存文件,会默认保存为LANG设定的字符编码

然后,然后
看下linux-0.96内核源码,从open系统调用开始,ctrl+左键,一路走到文件系统,发现,从open到文件系统通过路径查找到文件的inode,是把那个char数组拷贝到内核,然后用”/”把路径分隔开,从根目录开始一级一级搜索匹配,怎么匹配的?一个字节一个字节对比
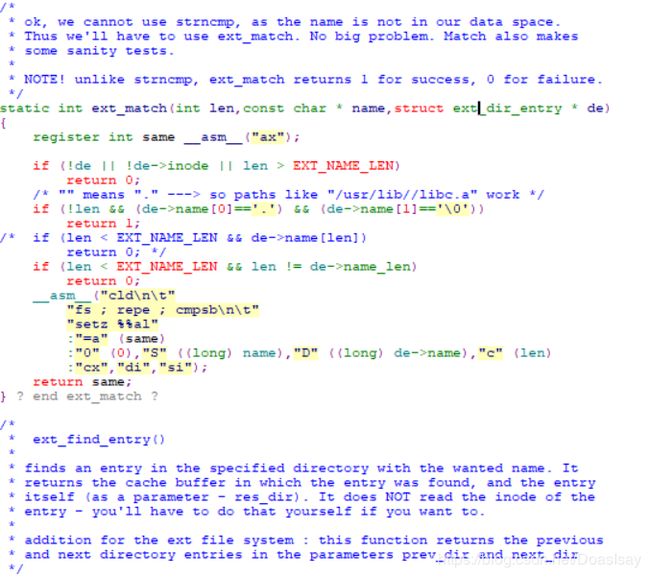
ext_match这个函数的,第2个参数name就是路径中的一段,第3 个参数
是struct ext_dir_entry ,这个结构体用来表明这个name在当前路径下对应的文件的inode是什么
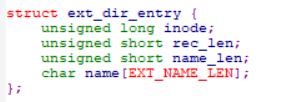
ext_match中的asm汇编代码就是把第2个参数name与de中的name一个字节一个字节做对比,如果对比上就使用inode编号去磁盘上读取这个inode,读出来的inode是个哈玩意?

磁盘上的每一个文件对应一个inode,用来描述文件存在何处,及什么时候创建,文件类型等信息,inode是格式化磁盘时分配的,可以通过df -i 查看磁盘的inode使用情况,i_dev设备编号用于表明文件保存在那个磁盘设备上

我们平常stat 一个文件是这样的

基本上stat的输出linux-0.96的inode 中都是有的
Inode中的i_data存放的是文件存在磁盘上的那些block的编号,i_mode用来标识是目录还是文件,如果是目录就会从i_data取出block编号从磁盘读出这个block(1kb,2个扇区),把这个从磁盘读出block强转成struct ext_dir_entry,如果i_mode是文件此block就是文件中的内容
如果有这样一个场景,一个路径要有三部分组成且都是中文,一部分来自网络,一部分来自配置,一部分是在代码中写死的,那么这样拼接成的一个完整的路径,如果各个部分的字符编码都不一样(事实是有极大的可能是不一样),那么你的程序将会报在找不到这个路径的异常,事实上这个路径是存在的,你还可以cd进去more一下文件,但程序就是报,No such file or directory,你百思不得其解吧
在Python2中模拟一个路径由两种字符编码组成,py文件用gb18030编码保存,系统默认字符编码为utf-8
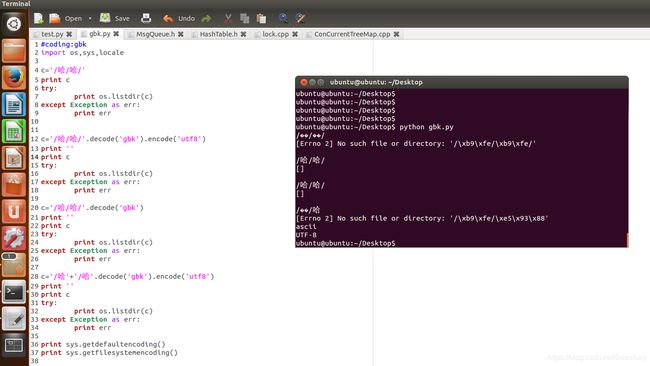
可见只有路径完全是utf-8编码时才能找到路径,虽然你看到的都是/哈/哈/,文件系统查找这个文件夹的inode也是通过你给的路径从根目录开始,一级一级,拿一个字节一个字节去对比的
‘/哈/哈/’ 路径是一个gbk编码组成的路径 /\xb9\xfe/\xb9\xfe/,用这个gbk编码组成的路径,不能与文件系统中的目录匹配上
'/哈/哈/'.decode('gbk').encode('utf8')是一个utf-8编码组成的路径,可以与文件系统中的目录匹配上
'/哈/哈/'.decode('gbk')是一个unicode编码组成的路径,/\xe5\x93\x88/\xe5\x93\x88/只有用这个路径去listdir才不报错,才能与文件系统中的目录匹配上
'/哈'+'/哈'.decode('gbk').encode('utf8')这个路径是一个gbk和utf-8两种编码组成的一个路径其16进制值为/\xb9\xfe/\xe5\x93\x88 b9 fe是哈的gbk编码,e5 93 88 是哈的utf-8编码
所以当你在配置文件中配了中文路径,而此配置文件的字符编码又与操作系统的字符编码不一致,就会出现找不到文件的异常
而当只有ascii字符时,无论你的配置文件是什么字符编码,操作系统是什么字符编码,都不会出现这种问题,至少gbk,utf-8是兼容ascii码的,utf-16是不兼容的
如果是字符串就一定会有个字符编码吧,如果解码,编码老是出问题,我就怀疑这个字符串中混进了一坨二进制的东东,而这种问题很有可能会出现