tensorflow 使用笔记
解决window下 tensorboard不是内部或外部命令的问题
将 C:\Users\用户名\AppData\Local\Programs\Python\Python35\Scripts 下的 tensorboard.exe 拷贝到 C:\Users\用户名\AppData\Local\Programs\Python\Python35\Scripts 下就好了。
其他类似的问题基本都可以这样解决。
简单的二分类示例
图片分类参考:https://github.com/LeifPeng/VehicleClassify
# -*- coding:utf-8 -*-
"""
@Author : Peng
@Time : 2018/4/11
info : 使用TensorFlow建立简单的模型
"""
import tensorflow as tf
import numpy as np
import os
def add_layer(inputs, in_size, out_size, activation_function=None, layer_index='1'):
"""
设置便捷的添加模型方式
:param inputs: 输入,原始数据或者上一层的输出
:param in_size: 输入的列数或者上一层神经元的数目
:param out_size: 输出大小,本层神经元数量
:param activation_function: 激活函数
:param layer_index: 本层索引
:return: 本层输出
"""
# 定义命名空间,会自动添加到 tensorboard 的图层 Graphs
with tf.name_scope('layer' + layer_index):
with tf.name_scope('weights'):
# X[m, nx] * W[nx, layer_size] = Z[m, layer_size],故取 inputs.shape[1]
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W')
with tf.name_scope('biases'):
# A = g(Z + b), 利用广播机制 b.shape = [1, Z.shape[1]]
biases = tf.Variable(tf.zeros([1, out_size]), name='b')
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
def model(x_input, nclass=2):
"""
建立模型,样本数为 m
:param x_input: shape[m, nx]
:param nclass:
:return:
"""
l1 = add_layer(x_input, in_size=6, out_size=20, activation_function=tf.nn.relu, layer_index='1')
l2 = add_layer(l1, in_size=20, out_size=15, activation_function=tf.nn.relu, layer_index='2')
# 注意最后一层不要激活函数,因为后面计算交叉熵损失函数的时候会再用一次
outputs = add_layer(l2, in_size=15, out_size=nclass, activation_function=None, layer_index='FC')
return outputs
def train(x_train, y_train, epochs=1000, learning_rate=0.1, log_dir="logs/", log_frequency=50, save_frequency=200):
"""
定义训练函数
:param x_train:
:param y_train:
:param epochs: 迭代次数
:param learning_rate:学习率
:param log_dir: 保存路径
:param log_frequency: 输出频率
:param save_frequency: 保存频率
:return:
"""
# 使用占位符,后面使用 feed_dict 赋值
x_plc = tf.placeholder(tf.float32, [None, 6], name='x_input')
y_plc = tf.placeholder(tf.float32, [None, 2], name='y_input')
# 使用模型进行计算
logist = model(x_plc, nclass=2)
with tf.name_scope('loss'):
# 定义平方差损失函数,reduce_mean 表示求均值
# loss = tf.reduce_mean(tf.reduce_sum(tf.square(y_train - y_pre), reduction_indices=[1]))
# 交叉熵损失函数,注意是使用 softmax 之前的值
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_plc, logits=logist))
# 计算准确率
with tf.name_scope('acc'):
correct_predictions = tf.equal(tf.argmax(y_train, 1), tf.argmax(y_plc, 1))
acc = tf.reduce_mean(tf.cast(correct_predictions, tf.float32))
# 定义训练目标 minimize(loss)
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# 添加 loss 节点
tf.summary.scalar('loss', loss)
# 添加 acc 节点
tf.summary.scalar('acc', acc)
# 总的数据节点
summary_op = tf.summary.merge_all()
saver = tf.train.Saver()
with tf.Session() as session:
# 设置 tensorboard 保存目录
summary_writer = tf.summary.FileWriter(log_dir, session.graph)
session.run(tf.global_variables_initializer())
# 迭代 epochs 次学习
for step in range(epochs):
# 执行训练目标 train_step
# training train_step 和 loss 都是由 placeholder 定义的运算,所以这里要用 feed 传入参数
session.run(train_step, feed_dict={x_plc: x_train, y_plc: y_train})
if step % log_frequency == 0:
loss_step, acc_step, summary_step = session.run([loss, acc, summary_op],
feed_dict={x_plc: x_train, y_plc: y_train})
# 添加具体数据
summary_writer.add_summary(summary_step, step)
print('step loss is {} and acc is {}'.format(loss_step, acc_step))
if step > epochs/2 and step % save_frequency == 0:
# 保存参数
checkpoint_path = os.path.join(log_dir, 'model.ckpt')
saver.save(session, checkpoint_path, global_step=step)
if __name__ == '__main__':
np.random.seed(1)
x_train = np.random.randn(300, 6)
# 归一化
x_train = (x_train - np.min(x_train)) / (np.max(x_train) - np.min(x_train))
y_train = np.zeros((300, 2))
for i in range(300):
if i < 100:
y_train[i][0] = 1 # 归为第一类
else:
y_train[i][1] = 1 # 归为第二类
print('data : ', x_train.shape, y_train.shape)
print(x_train[:2], y_train[:2])
train(x_train, y_train, learning_rate=0.0005)
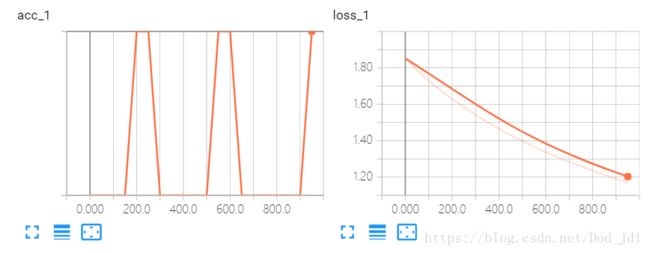
使用 tensorboard --logdir logs路径 命令打开 tensorboard:
当 acc=1 时 loss 未必为 0,因为 1 和 0.99 认为是相等的,但 loss 从概率上说虽然相差很小但仍然是不等的。
step 0 loss is 1.8520101308822632 and acc is 1.0
step 50 loss is 1.7855623960494995 and acc is 1.0
step 100 loss is 1.7295210361480713 and acc is 1.0