大数据开发利器:Hadoop(5)-HBase第二讲
本节主要介绍HBase安装配置以及HBase shell基本使用。
属于HBase第二节讲解。
1. 预先准备
1.1 查看依赖关系
首先应该安装和配置完成Hadoop,这里不在过多描述。
其次,选择安装版本时,查看官方文档了解各个安装包的依赖关系。链接:官方文档
主要查看以下三个依赖关系:
① HBase与Hadoop版本兼容问题。(Ctrl+f搜索Hadoop Version)
② JDK与HBase的版本兼容问题。(搜索`Basic Preerequisites)
③ HBase与Zookeeper关系(搜索Zookeeper Requirements)
另外,HBase和Hive可能会产生兼容问题,这个之后遇到时候,再进行解决。
1.2 HBase预备知识
① HBase由三种运行模式,单机模式、伪分布式模式、分布式模式。
② 需要以下三个条件:
- JDK
- Hadoop(单机模式不需要,伪分布式模式和分布式模式需要)
- SSH
③ 启动关闭Hadoop和HBase的顺序一定是:启动Hadoop -> 启动HBase -> 关闭HBase-> 关闭Hadoop
④ 配置HBase时,HBASE_MANAGES_ZK=true,则HBase自己管理Zookeeper,否则,启动独立的Zookeeper。(所以,单机版的HBase,使用自带Zookeeper,集群安装的HBase则采用HBase单独Zookeeper集群)
2. 安装和配置HBase
2.1 安装Zookeeper
由于我们采用集群安装的方式,所以另外安装Zookeeper,不使用HBase自带的Zookeeper。
① 首先到官网(Zookeeper下载地址)上下载zookeeper-3.4.9.tar.gz。
② 将下载好的包放置再/usr/local目录下。命令如下:
cd ~/Desktop
tar -xvzf zookeeper-3.4.9.tar.gz
sudo cp -r zookeeper-3.4.9 /usr/local
rm -r -f zoo* # 删除文件夹和包
cd /usr/local
sudo chown -R hadoop:hadoop zookeeper-3.4.9 修改文件夹权限③ 配置zoo.cfg文件
cd zookeeper-3.4.9/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg# 编辑zoo.cfg文件
tickTime=2000 # 是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔
initLimit=10 # follower和leader之间最长心跳时间,设置为10倍tickTime
syncLimit=5 #配置leader和follower之间发送消息,请求和应答的最大时间,设置为5倍tickTime
clientPort=2181 # 这个端口是客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求
# 以上都为默认
dataDir=/usr/local/zookeeper-3.4.9/zookeeperLog/ # 保存数据的目录,默认情况下写数据的日志文件也保存在这个目录里面
④ 配置环境变量并使其生效
vim ~/.bashrc
# 修改如下
# export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.9
# export PATH=$PATH:$ZOOKEEPER_HOME/bin
source ~/. bashrc⑤ 启动Zookeeper
# 启动前准备
netstat -at | grep 2181 # 查看tcp端口是否被占用
# 如果没有该命令,尝试yum install net-tools
echo ruok | nc localhost 2180 #测试是否启动了Server,回复imok则表示已经启动
# 如果没有nc命令,yum install nc#启动Zookeeper服务
zkServer.sh start
echo ruok | nc localhost 2181 # 如果回复imok则表示启动成功
jps #查看多了QuorumPeerMain进程
可以看到第二行多了imok,表明已经启动成功。
同时多了QuorumPeerMain服务。
zkCli.sh -server localhost:2181 #启动client连接server
[zk: localhost:2181(CONNECTED) 1] quit # 退出
zkServer.sh stop #关闭Server
2.2 安装HBase
① 首先下载hbase-1.2.3-bin.tar.gz(HBase下载地址)
② 解压到/usr/local目录下
cd ~/Desktop
sudo tar -xvzf hbase-1.2.3.tar.gz -C /usr/local
rm -r -f hbase*
cd /usr/local
sudo chown -R hadoop:hadoop hbase-1.2.3/③ 配置HBase
- 修改hbase-env.sh
cd hbase-1.2.3/conf
vim hbase-env.sh# hbase-env.sh 文件
export JAVA_HOME=/usr/local/jdk1.7.0_25
export PATH=$PAHT:$JAVA_HOME/bin
export HBASE_MANAGES_ZK=false
export HBASE_PID_DIR=/var/hadoop/pids# 创建pid目录,不然默认是在tmp目录下,重启之后就不存在了
cd /var/
sudo mkdir hadoop
sudo chown -R hadoop:hadoop hadoop/- hbase-site.xml
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://localhost:9000/hbasevalue>
property>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/usr/local/hbase-1.2.3/hbase_dataDirvalue>
property>
<property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>localhostvalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.master.portname>
<value>16000value>
property>
<property>
<name>hbase.master.info.portname>
<value>16010value>
property>
configuration>-
③ 启动Hbase
start-dfs.sh
start-yarn.sh
zkServer.sh start
cd /usr/local/hbase-1.2.3
bin/start-hbase.sh # 启动HBase的守护进程
jps
可以发现,多了HMaster、HRegionServer两个进程。
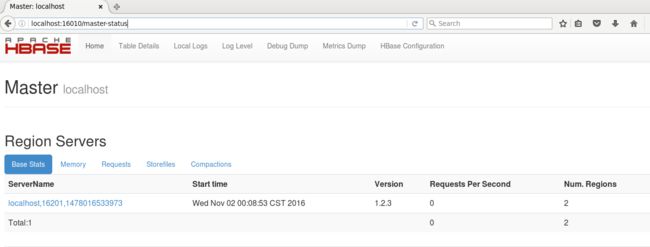
可以访问http://localhost:16010查看网络接口。如下图:
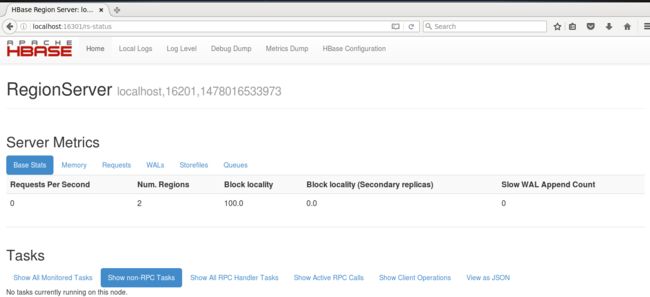
访问http://localhost:16301查看区域服务器。如下图:
启动和关闭顺序:
启动Hadoop -> 启动HBase -> 启动Zookeeper -> 关闭HBase -> 关闭Zookeeper -> 关闭Hadoop
2.3 HBase应用
2.3.1 HBase简单介绍
为了接下来讲解例子方便,这里简单介绍一下HBase,详细介绍请看上一节。
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。
HBase的数据模型有以下几个概念:表、行、列族、行限定符、单元格、时间戳。
如下图:

HBase需要根据行键、列族、行限定符和时间戳来确定一个单元格。
2.3.2 HBase命令行实例
注意,如果允许时显示无法连接Zookeeper,可能是防火墙未关闭。或者是以上的.xml文件配置错误。
假设有一个学生信息表的逻辑视图如下:
| name | grad | score | ||
| English | Math | Computer | ||
| Zhangsan | B | 80 | 85 | 95 |
| Lisi | C | 65 | 74 | 88 |
接下来做如下几个操作:
① 启动Hadoop、Zookeeper、HBase,以及hbase shell
start-dfs.sh
start-yarn.sh
zkServer.sh start
cd /usr/local/hbase-1.2.3/
bin/start-hbase.sh
bin/hbase shell ② 创建表
create 'studentInfo', 'grad', 'score'
list
describe 'studentInfo' # 查看表的结构
③ 插入数据
由于Hbase是一个列数据库,所以插入数据比较繁琐。
# put 't1', 'r1', 'c1', 'value', ts1
# t1指的表名,r1是行键名,c1是列名,value是单元格值,ts1是时间戳(可省略)put 'studentInfo', 'Zhangsan', 'grad', 'B'
put 'studentInfo', 'Zhangsan', 'score:English', '80'
put 'studentInfo', 'Zhangsan', 'score:Math', '85'
put 'studentInfo', 'Zhangsan', 'score:Computer', '95'
put 'studentInfo', 'Lisi', 'grad:', 'C'
put 'studentInfo', 'Lisi', 'score:English', '65'
put 'studentInfo', 'Lisi', 'score:Math', '74'
put 'studentInfo', 'Lisi', 'score:Computer', '88'④ 查看数据
get 't1'[, 'r1', 'c1', {其他条件}]# 扫描全部数据
scan 'stduentInfo'
# 扫描指定行
get 'studentInfo', 'Zhangsan'
# 扫描指定行的指定列族
get 'studentInfo', 'Zhangsan', 'score'
# 指定行,指定列族的单个列 1
get 'studentInfo', 'Zhangsan', 'score:English'
# 指定行,指定列族的单个列 2
get 'studentInfo', 'Zhangsan', {COLUMN => 'score:English'}
# 指定行,指定列族的多个列
get 'studentInfo', 'Zhangsan', {'COLUMN' => ['score:English', 'score:Math', 'score:Computer']}
# 指定行,指定的多个列族
get 'studentInfo', 'Zhangsan', 'grad', 'score'

# 扫描特定间隔的时间戳
get 't1', 'r1', {TIMERANGE => [ts1, ts2]}
# 扫描特定版本
get 't1', 'r1', {VERSIONS => 4}
# 一些过滤器的操作
hbase> scan ‘.META.', {COLUMNS => ‘info:regioninfo'}
hbase> scan ‘t1′, {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => ‘xyz'}
hbase> scan ‘t1′, {COLUMNS => ‘c1′, TIMERANGE => [1303668804, 1303668904]}
hbase> scan ‘t1′, {FILTER => “(PrefixFilter (‘row2′) AND (QualifierFilter (>=, ‘binary:xyz'))) AND (TimestampsFilter ( 123, 456))”}
hbase> scan ‘t1′, {FILTER => org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1, 0)} ⑤ 修改和删除指定数据
# 修改Zhangsan的grad为A
put 'studentInfo', 'Zhangsan', 'grad', 'A'
scan 'studentInfo', {COLUMNS => 'grad'}
# 删除指定数据
delete 't1', 'r1', 'c1', ts1
# 删除zhangsan的grad
delete 'studentInfo', 'Zhangsan', 'grad'⑥ 添加和删除一个列族
HBase修改表名查询后好像没有api直接调用,据说可以使用快照的方式。没有尝试过,读者可以自己尝试一下,地址如下:HBase修改表名
# 添加一个列族info
disable 'studentInfo' #需要先禁用该表
alter 'studentInfo' , NAME => 'info'
enable 'studentInfo'
describe 'studentInfo' # 查看表的结构
# 删除列族
disable 'studentInfo'
alter 'studentInfo', {METHOD => 'delete', NAME => 'info'} # 方法一
alter 'studentInfo', 'delete' => 'info' # 方法二
enable 'studentInfo'
describe 'studentInfo'⑦ 统计行数
count 'studentInfo'
count 'studentInfo', CACHE => 1000, INTERVAL => 10
# 统计结果会缓存,默认是10行,统计间隔默认是1000行,这里修改CACHE为10,INTERVAL为10⑧ 删除表
disable 'studentInfo' # 屏蔽该表
drop 'studentInfo' # 执行删除操作
list # 查看结果⑨ 执行hbase shell脚本
同样,可以将命令保存为.hbaseshell的脚本进行执行。
bin/hbase shell 脚本名
# 举例
bin/hbase shell test.hbaseshell3. 总结
通过上面我们可以发现,
① HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、行限定符和时间戳
② 每个值是一个未经解释的字符串,没有数据类型
③ 用户在表中存储数据,每一行都有一个可排序的行键和任意多的列,所以每一个列族可以包含任意多个列,同行列族支持动态扩展,可以添加列族和列。
④ HBase执行更新操作时候,并不会删除数据旧的版本,而是生成一个新的版本。(这是和HDFS只允许追加而不允许修改的特性相关)所以,修改表名和列族名是比较困难的,同时也促使了时间戳的存在。
参考内容
HBase官方文档
林子雨-大数据技术原理与应用
网易微专业 大数据工程师