【学习排序】 Learning to Rank中Pointwise关于PRank算法源码实现
最近终于忙完了Learning to Rank的作业,同时也学到了很多东西.我准备写几篇相关的文章简单讲述自己对它的理解和认识.第一篇准备讲述的就是Learning to Rank中Pointwise的认识及PRank算法的实现.主要从以下四个方面进行讲述:
1.学习排序(Learning to Rank)概念
2.基于点的排序算法(Pointwise)介绍
3.基于顺序回归(Ordinal Regression-based)的PRank排序算法
4.PRank算法Java\C++实现及总结
一. 学习排序(Learning to Rank)概念
学习排序概念推荐转载的文章:机器学习排序之Learning to Rank简单介绍
1.首先,为什么会出现学习排序呢?
传统的排序方法是通过构造一个排序函数实现,在Information Retrieval领域一般按照相关度进行排序。比较典型的是搜索引擎中一条查询query,将返回一个相关的文档document,然后根据(query,document)之间的相关度进行排序,再返回给用户。
而随着影响相关度的因素(如PageRank)变多,Google目前排序方法考虑了200多种方法。这使得传统排序方法变得困难,人们就想到通过机器学习来解决这一问题,这就导致了Learning to Rank的诞生。
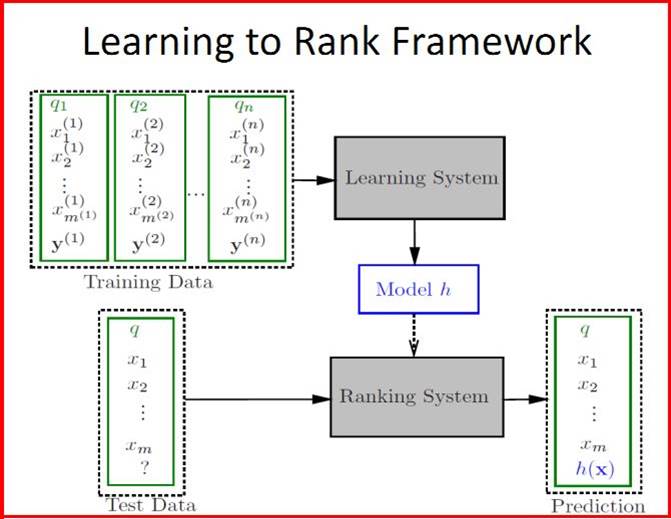
2.然后是学习排序的基本流程如下图所示.
很明显它就是基本步骤就是通过训练集数据(Train Set)学习得到模型h,然后通过该模型去对测试集数据(Test Set)进行计算和排序,最后得到一个预测的结果.
数据集可参考微软136维数据——MSLR-WEB10K 它是2010年的数据.形如:
=============================================================
0 qid:1 1:3 2:0 3:2 4:2 ... 135:0 136:0
2 qid:1 1:3 2:3 3:0 4:0 ... 135:0 136:0
=============================================================
其数据格式: label qid:id feaid:feavalue feaid:feavalue ...
每行表示一个样本,相同的查询请求的样本qid相同,上面就是两个对qid为“1”的查询;label表示该样本和该查询请求的相关程度,该label等级划分方式为 {Perfect, Excellent,Good, Fair, Bad} 共五个类别,后面对应的是特征和特征值,我们通常使用的
同样你也可以使用比较经典的2007的数据集——

4.如果你还是不清楚,我换成通俗的例子解释:
PS:这是我的个人理解,如果有错误或不足之处,欢迎提出!
二. 基于点的排序算法(Pointwise)介绍
机器学习解决排序学习问题可分为3类:
1.基于回归排序学习(regression-based algorithms):序列转为实数
2.基于分类排序学习(classification-based algorithms):二值分类
3.基于顺序回归排序学习(ordinal regression-based algorithms)
但是这里我想讲述的是最常见的分类,它们应该与上面是交叉的:
1.基于点的LTR算法——Pointwise Approach
2.基于对的LTR算法——Pairwise Approach
3.基于列的LTR算法——Listwise Approach
Pointwise处理对象是一篇文档,将文档转化为特征向量后,机器学习系统根据训练得出的模型对文档进行打分(注意:训练集学习出权重模型去给测试集文档打分是LTR中非常经典的用法),打分的顺序即为搜索排序的结果.
Score(x)=w1*F1+w2*F2+w3*F3+...+w136*F136
其中w1-w136为136维对应权重参数,由训练集训练得到;F1-F136为测试文档给出136个特征值.
原数据有5个类标(0-4代表相关程度:Perfect>Excellent>Good>Fair>Bad),则设置5个阈值来区分所得分数的分类.如果得分大于相关阈值,则划分为相应的类.常见算法包括:Prank、McRank
下面是我自己画的一张图,其中四根红线是四个阈值,它把这些文档集划分为了五个不同类.每当一个新的文档来测试,它都会根据已有模型计算出相应分数,再根据分数和阈值划分类即可.

三. PRank算法介绍
PRank算法是基于点的排序学习,顺序回归学习问题.其算法主要参考Kolby Crammer & Yoram Singer(From:The HeBrew University,以色列希伯来大学)论文《Pranking with Ranking》.网址如下:
http://papers.nips.cc/paper/2023-pranking-with-ranking.pdf
算法过程如下:

对于46维数据而言,它存在3个类标(0-2).故上述算法中初始阈值b[0]=b[1]=b[2]=0,b[3]=正无穷.
注意它只有一层循环For(1...T)表示样本集的总行数,而没有进行迭代(CSDN三国那个例子含迭代错误);它主要是通过预测标号y~和实际标号y进行对比,来更新权重和阈值.
在H排序决策函数
推荐中文资料:南开大学论文《基于PRank算法的主动排序学习算法》
四. PRank算法Java\C++实现及总结
1.Java代码实现
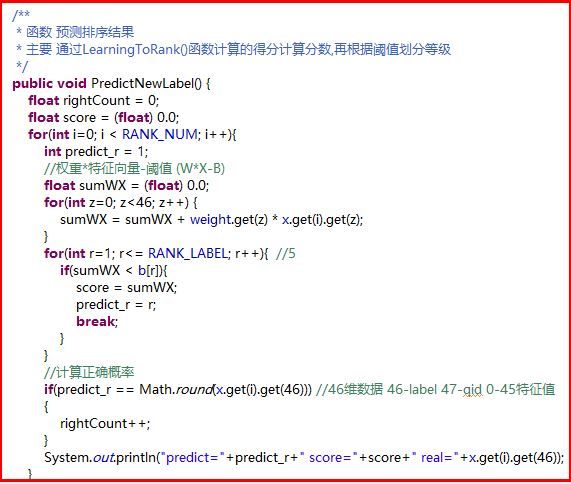
代码中有详细注释,每个步骤都是按照上面的算法进行设计的.左图是主函数,它主要包括:读取文件并解析数据、写数据(该函数可注释掉,它是我用于验证读取是否正确时写的)、学习排序模型和打分预测.右图是预测排序结果的算法.

package com.example.pointwise;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
/**
* Pointwise基于点学习排序(Learning to Rank)的Prank算法
* @author Eastmount YXZ
* 参考资料
* 该算法从136维数据集改成46维数据集,中间可能有注释不一致现象
* (原始论文) http://papers.nips.cc/paper/2023-pranking-with-ranking.pdf
* (新浪) http://blog.sina.com.cn/s/blog_4c98b960010008xn.html
* (CSDN)http://blog.csdn.net/pennyliang/article/details/17333373
*/
public class Prank {
public int RANK_NUM = 10000; //记录总样本数 (总行数)
public int RANK_CATA = 46; //排序的特征维数 (数据集136维 后改为46维)
public int RANK_ITER = 1; //排序的迭代次数 (原文迭代1次)
public int RANK_LABEL= 3; //排序划分的阈值 (微软数据集划分5类 0-4) 3维全相关,部分相关,不相关
//采用该方法实现动态数组添加数据
List weight = null; //特征值的权重向量 (46个 136个)
//训练集数据 每行共48个数据 (46个特征值 二维数组-feature[行号][46] + 真实Label值0-2 + qid值)
List> x = null;
Float [] b = null; //阈值数 K+1个(RANK_LABEL+1)
public int sumLabel = 0; //文件总行数 (标记数)
/**
* 函数功能 读取文件
* 参数 String filePath 文件路径
*/
public void ReadTxtFile(String filePath) throws IOException {
String encoding="GBK";
File file = new File(filePath); //文件
BufferedReader bufferedReader = null;
try {
//判断文件是否存在
if(file.isFile() && file.exists()) {
//输入流
InputStreamReader read = new InputStreamReader(new FileInputStream(file), encoding);
bufferedReader = new BufferedReader(read);
String lineTxt = null;
sumLabel =0; //记录总样本数
x = new ArrayList> ();
//按行读取数据并分解数据
while((lineTxt = bufferedReader.readLine()) != null) {
String str = null;
int lengthLine = lineTxt.length();
List subList=new ArrayList();
x.add(subList);
//获取数据 字符串空格分隔
String arrays[] = lineTxt.split(" ");
for(int i=2; i=48) { //#号后跳出 后面注释不进行读取
continue;
}
//获取特征:特征值 如1:0.0004
String subArrays[] = arrays[i].split(":");
int number = Integer.parseInt(subArrays[0]); //判断特征
float value = Float.parseFloat(subArrays[1]);
subList.add(value);
}
//获取每行样本的Label值 i=0 (五个等级0-4)
subList.add(Float.parseFloat(arrays[0]));
//获取qid值 i=1
String subArrays[] = arrays[1].split(":");
subList.add(Float.parseFloat(subArrays[1]));
//总行数+1
sumLabel++;
} //End 按行读取
read.close();
} else {
System.out.println("找不到指定的文件\n");
}
} catch (Exception e) {
System.out.println("读取文件内容出错");
e.printStackTrace();
} finally {
bufferedReader.close();
}
}
/**
* 函数 写文件
* 参数 String filePath 文件路径
* 注意 该函数还是136维数据,但算法该成46维 故不使用该函数
*/
public void WriteTxtFile(String filePath) {
try {
System.out.println("文件输出");
String encoding = "GBK";
FileWriter fileWriter = new FileWriter(filePath);
//按行写文件
for(int i=0; i();
for(int i=0; i< RANK_CATA; i++){ //特征向量的维数
weight.add((float) 0.0);
}
//初始化阈值 b[0]=b[1]=[2]=0 b[3]=正无穷大
b=new Float[RANK_LABEL+1];
for(int i=0; i 
该部分代码参考自新浪播客:
http://blog.sina.com.cn/s/blog_4c98b960010008xn.html
运行结果过程如下图所示,通过train.txt数据集得到model.txt,里面存储的是46个权重.如:
-0.052744 1.886342 1.002179 -6.400005 -1.824795 0.000000 0.000000 ..
然后通过该模型对test.txt进行打分预测,同时计算正确率(已标注Label=预测Label).

#include
#include
#include
#include
using namespace std;
#define K 3 //排序的序数,即如排成全相关,部分相关,不相关,序数就是3
#define N 46 //特征的维数
double *w; //权值
int *b; //偏置项
int *y;
int *t;
//从文件中获得特征值 X 存储特征向量 yt 存储标签
bool getData(double *x,int &yt,ifstream &fin)
{
if (fin.eof())
return false;
char data[1024];
int index = 1;
fin.getline(data,1024);
char *p = data;
char q[100];
q[0] = p[0];
q[1] = '\0';
yt = atoi(q) + 1; // 标签
p = p+8;//跳过qid:xx的冒号
for( ; *p != '\0'; ++p)
{
if(*p == ':')
{
++p;
int i = 0;
for(i=0; *p != ' '; i++, p++)
{
q[i] = *p;
}
q[i] = '\0';
x[index ++] = atof(q);
}
}
return true;
}
//各变量进行初始化
void Initialize()
{
w = new double[N+1];
b = new int[K+1];
y = new int[K+1];
t = new int[K+1];
int i;
int r;
for(i=1; i<=N;i++)
w[i] = 0 ;
for(r=1;r<=K-1;r++)
b[r] = 0;
b[K] = std::numeric_limits::max();//无穷大
}
//利用Prank算法进行训练
void PrankTraining(double *x,int yt)
{
int i;
int r;
double wx = 0; //存储 W*X 的计算结果
for(i =1; i<=N; i++) //计算 W*X
wx += w[i] * x[i];
for(r =1; r<=K; r++) //找到满足 W*X-b<0 的最小 r
{
if(wx - b[r] <0 )
break;
}
int yy = r ; //预测值
if (yy == yt) //预测正确,直接返回
{
return;
}
else //预测错误,权值更新
{
for(r=1; r 五. 总结与问题
最后讲述在该算法中你可能遇到的问题和我的体会:
1.由于它是读取文件,可能文件很大(几百兆或上G).最初我设计的数组是double feature[10000][136],用来存储每行特征值,但是如果行数太大时,What can do?此时我们应该设置动态数组
3.为什么我从136维数据转变成了46维数据?
你打开136维特征值数据时,你会发现它的值特别大,不论是Pointwise,还是Pairwise和Listwise都可能出现越界,一次内积求和可能就10的7次方数据了.但是46维数据,每个特征值都是非常小的,所以如果用136维数据,你需要对数据进行归一化处理,即数据缩小至-1到1之间.
4.评价Pointwise、Pairwise和Listwise指标通常是MAP和NDCG@k,后面讲述基于对的学习排序和基于列的学习排序会具体介绍.
5.你可能会发现数据集中存在vail验证集,以及交叉验证、交叉熵、梯度下降后面都会讲述.但由于相对于算法,我对开发更感兴趣,很多东西也是一知半解的.
6.最后要求该算法到Hadoop或Spark实现并行化处理,但算法的机制是串行化.有一定的方法,但我没有实现.我们做的是一种伪并行化处理,即模型得到权重后进行并行化计算分数排序.
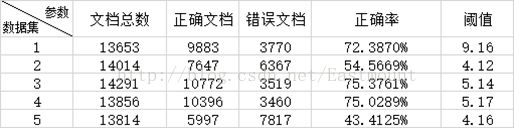
最后简单附上我们的实验结果,后面的算法实验结果是基于MAP和NDCG@k

(By:Eastmount 2015-01-28 夜5点半 http://blog.csdn.net/eastmount/)