Faster R-CNN学习(原理篇)
基本概念
IOU是什么
The bounding boxes for the training and testing sets are hand labeled, hence why we call them the “ground-truth”. Your goal is to take the training images + bounding boxes, construct an object detector, and then evaluate its performance on the testing set. An IoU score > 0.5 is normally considereda“good”prediction.

mAP
In the context of machine learning, precision typically refers to accuracy — but in the context of object detection, IoU is our precision. However, we need to define a method to compute accuracy per class and across all classes in dataset. To accomplish this goal, we need mean Average Precision(mAP)
To compute average precision for a single class, we determine the IoU of all data points for a particular class. Once we have the IoU we divide by the total class labels for that specific class, yielding the average precision. To compute the mean average precision, we compute the average IoU for all N classes — then we take the average of these N averages, hence the term mean average precision.也就是说,对总的IoU取平均值。这也可以说就是mAP的意思。
0.5是一个基准值。大多数目标检测算法都应该在0.5这个值以上,否则,这个目标检测算法就没有什么意义。
Fast R-CNN
相比较于R-CNN而言,Fast R-CNN最大的不同在于Fast R-CNN会对整个图片进行特征提取,之后用一个ROI(rear of interest)pooling layer来对候选区域进行提取。而R-CNN上来就要进行候选区域(数千个)提取,之后再放入CNN网络进行训练,Fast R-CNN改进了这一点便大大加快了训练速度。
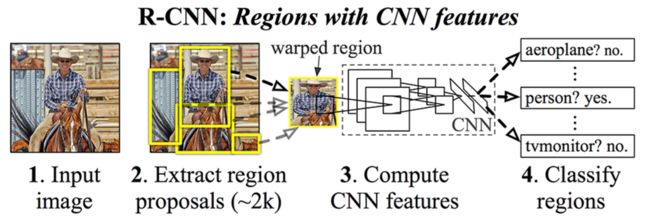

具体来说,Fast R-CNN是这样做的:
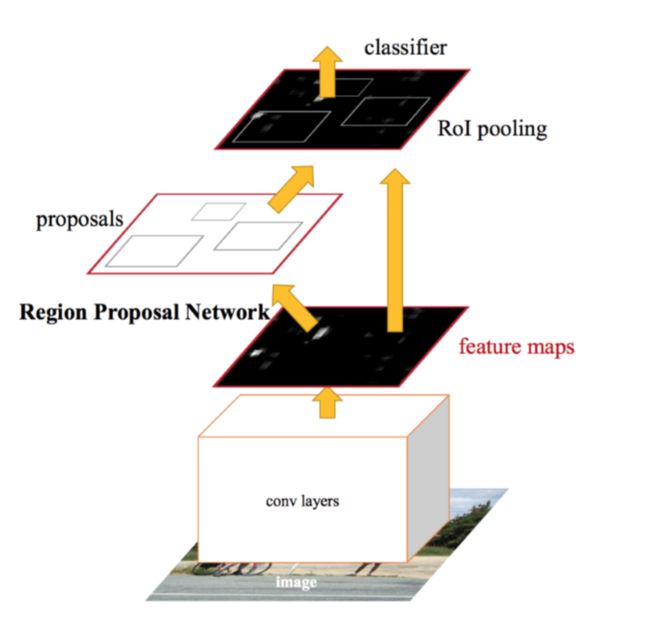
RPN
从前面的两张图中我们可以看到,它是做了两个分类预测问题。一个是对分类标签的预测,另一个是对候选区域位置的一个预测。注意到最后一张图片我们使用了一个新的概念RPN(Region Proposal Network),从这个网络中直接提取候选区域,减少使用候选区域搜索算法。
RPN通常用来对图像的潜在候选区域进行识别,这时候我们并不知道具体候选区域是哪一个,只是对其潜在的候选区域进行识别。
Fast R-CNN基本网络

一个基本的Fast R-CNN网络如图所示。我们这里可以看到,最后一部分我们删除了全连接层,而是使用了卷积层和池化层。这项操作允许我们的网络处理输入的任意空间维度的图片,这些处理过的特征之后被喂给了RPN和ROI Pooling模型。
Anchor
传统的目标检测算法,我们对于我们的分类器主要使用两种方法:
(1)滑动窗口 + 图像金字塔, (2)候选区域选择算法。然而我们的目标是使用一种端到端的深度学习方法来生成候选区域模型,因此我们需要一种全新的方法来找到我们的ROI。
Regin of Interest(ROI)Pooling

ROI池化层的目的是提取N个候选区域的ROI特征,之后ROI池化模型会对维度重新编码,并将维度下降至77D(D是特征图的深度),这些准备好的特征是为接下来的全连接层做准备。
ROI池化层提取的这些候选区域由RPN模型来提供。
Region-based Convolutional Neural Network
最后一步是使用Region-based Convolutional Neural Network,这个模型有两个主要目的,一个是预测ROI的分类标签,一个是精练候选区域位置,使得可以有一个更好的精度。
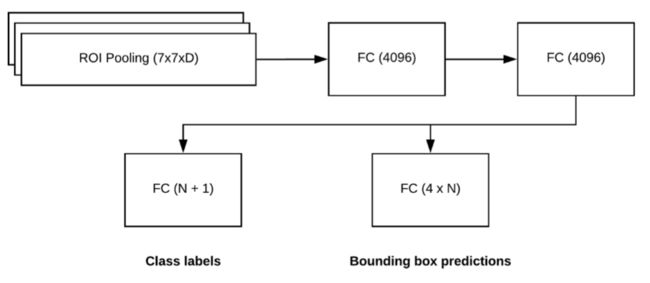
Class labels之所以是N+1是因为有N个类别标记,另外一个类别是背景类别,所以加1。Bounding box predictions之所以是4*N是因为,每一个类别有四个坐标位置要求( Δ x − c e n t e r \Delta x-center Δx−center, Δ y − c e n t e r \Delta y-center Δy−center, Δ w i d i t h \Delta widith Δwidith, Δ h e i g h t \Delta height Δheight)。
对于这两种输出,我们将会使用两种损失函数:
(1)对于分类会使用分类交叉熵损失函数,(2)对于边界框的回归问题我们将会使用平滑L1损失函数,我们这里使用categorical cross-entropy 而不是binary cross-entropy的主要原因是 (we are computing probabilities for each of our N classes versus the binary case (background vs. foreground) in the RPN module )我们在RPN模型中计算的是每一个类别的N分类问题,而不是前景和后景的二分类情况。
最后一步是使用非最大化抑制( non-maxima suppression class-wise )对于我们的bounding-box。这些边界框加上分类标签就会是最终的预测输出。
关于计算的选择
关于计算完整的Faster R-CNN网络有两个选择。一个选择是计算RPN模型,获取满足的结果,然后计算R-CNN模型。第二个选择是is to combine the four loss functions (two for the RPN module, two for the R-CNN module) via weighted sum and then jointly train all four. Which one is better?
In nearly all situations you’ll find that jointly training the entire network end-to-end by minimizing the weighted sum of the four loss functions not only takes less time but also obtains higher accuracy as well.