《数据结构与算法之美》专栏阅读笔记3——排序算法
上周排计划,说花个一天的时间看完好了(藐视脸)~然后每天回家看一会,看了一个星期……做人,要多照镜子好嘛

文章目录
- 1、简单排序
- 1.1 如何分析排序算法
- 执行效率
- 内存消耗
- 稳定性
- 2、排序算法
- 2.1、冒泡
- 2.2、插入
- 2.3、选择排序
- 2.4、小结
- 3、分治思路的排序算法
- 3.1、归并排序
- 3.2、快速排序
- 4、线性排序
- 4.1、桶排序
- 4.2、计数排序
- 4.3、基数排序
- 5、排序算法的优化
- 5.1、快速排序中分区点选取的优化方向
- 三数取中法
- 随机法
- 5.2、递归优化
- 6、小结
1、简单排序
1.1 如何分析排序算法
从以下几个方方面入手。
执行效率
- 最好情况、最坏情况、平均情况时间复杂度
- 时间复杂度的系数、常数、低阶
时间复杂度反映的时数据规模较大的时候的增长趋势。但实际开发中,也存在很多小规模的数据,此事稀疏、常数和低阶的占比较大,需要进行考虑。 - 比较次数和交换次数
内存消耗
可以通过空间复杂度来衡量。新概念:原地排序。特指空间复杂度为O(1)的排序算法。
稳定性
对于同一序列,排序的结果相同。
因为实际比较中,更多的是对对象进行排序。
2、排序算法
2.1、冒泡
原理:重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序错误就把他们交换过来。重复地进行直到没有相邻元素需要交换,直到排序完成。

要点:
- 对N个待排序元素,要排序的序列是0 ~ (N-已排序个数)。
- 如果一次排序中没有进行任何元素交换,说明序列已经是有序的,可以停止比较。
分析:
顺便复习下均摊时间复杂度的使用场景:
- 大部分情况下,时间复杂度都很低,只有个别情况下,时间复杂度较高。
- 操作之间存在前后连贯的时序关系
对排序算法的平均复杂度分析,可以使用有序度和逆序度来进行分析。 - 有序度:数组中具有有序关系的元素对的个数。
- 满序度:完全有序的大小为n的数组的有序度,为n*(n-1)/2
- 逆序度:与有序度相反。
关键公式:逆序度 = 满有序度 - 有序度。
排序的过程就是达到满有序度的过程
结论:交换的次数等于逆序度。
平均交换次数 = [0(最好) + n*(n-1)/2(最坏)]/2 = n*(n-1)/4
在作者给的基础上再来一点优化:
public static > void BubbleSort(T[] values, int length) {
if (length <= 1)
return;
int flag = length;
while (flag > 0) {
int end = flag - 1;
flag = 0;
for (int j = 0; j < end; j++) {
if (values[j].compareTo(values[j+1]) > 0) {
T tmp = values[j];
values[j] = values[j+1];
values[j+1] = tmp;
flag = j + 1;
}
}
}
}
通过flag来缩短要排序序列。
2.2、插入
原理:取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。

要点:
插入是通过移动来达到满序度的,所以移动的次数等于逆序度。
public static > void InsSort(T[] values, int length) {
if (length <= 1)
return;
for (int i = 0; i < length; i++) {
T v = values[i];
int j = i - 1;
for (; j >= 0; --j) {
if (values[j].compareTo(v) > 0) {
values[j+1] = values[j];
} else {
break;
}
}
values[j+1] = v;
}
}
直接插入排序,因为是要在已排序的序列中找到插入位置,所以需要移动是主节奏。
2.3、选择排序
原理:每次选取未排序区间的最小值,放到已排序区间的末尾。

要点:相较于插入排序,不需要移动元素,交换次数为n,消耗在遍历比较上。
实现
public static > void SelSort(T[] values, int length) {
if (length <= 1)
return;
for (int i = 0; i < length; i++) {
T min = values[i];
int minIdx = i;
for (int j = i + 1; j < length; j++) {
if (values[j].compareTo(min) < 0) {
min = values[j];
minIdx = j;
}
}
if (minIdx != i) {
T tmp = values[i];
values[i] = values[minIdx];
values[minIdx] = tmp;
}
}
}
2.4、小结
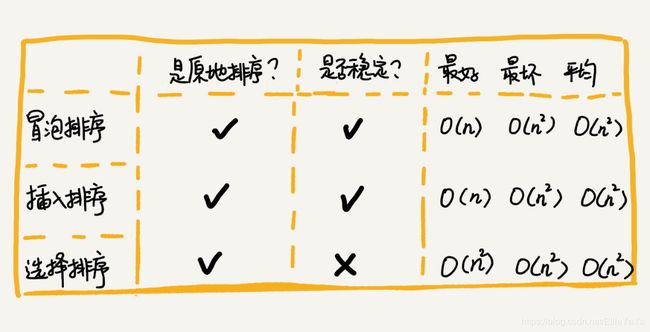 适合小规模数据的排序。
适合小规模数据的排序。
3、分治思路的排序算法
3.1、归并排序
原理:将大问题分解成小问题来进行排序,然后对排序后的结果进行合并。(妥妥地递归哦)

图片链接
时间复杂度分析
T(1) = C;
T(n) = 2*T(n/2) + n;
= 2^k * T(n/2^k) + k*n
另外一个分析思路就是:
拆分和合并的结构可以看作一棵二叉树,拆分部分和合并部分的深度都是logn,每个元素要找到自己的最终位置都要在树里跑一遍呢~所以复杂度为n*logn
实现:
private static > void SortC(T[] values, int left, int right, T[] tmp) {
if (left >= right)
return;
int mid = (left + right)/2;
for (int i = left; i <= right; i++) {
if (i == mid + 1)
System.out.print(" + ");
System.out.print(values[i] + " ");
}
System.out.println("");
SortC(values, left, mid, tmp);
SortC(values, mid + 1, right, tmp);
MergeC(values, left, mid, right, tmp);
}
private static > void MergeC(T[] values, int left, int mid, int right, T[] tmp) {
int i = left;
int j = mid + 1;
int tmpIdx = 0;
while (i <= mid && j <= right) {
if (values[i].compareTo(values[j]) < 1) {
tmp[tmpIdx++] = values[i++];
} else {
tmp[tmpIdx++] = values[j++];
}
}
while (i <= mid) {
tmp[tmpIdx++] = values[i++];
}
while (j <= right) {
tmp[tmpIdx++] = values[j++];
}
tmpIdx = 0;
for (i = left; i <= right; i++) {
values[i] = tmp[tmpIdx++];
}
}
利用哨兵简化编程的思路是:
MERGE(A, p, q, r)
n1 ← q-p+1; //计算左半部分已排序序列的长度
n2 2 ← r-q; //计算右半部分已排序序列的长度
create arrays L[1..n1+1] and R[1..n2+1] //新建两个数组临时存储两个已排序序列,长度+1是因为最后有一个标志位
for i ← 1 to n1
do L[i] ← A[p + i-1] //copy左半部分已排序序列到L中
for j ← 1 to n2
do R[j] ← A[q + j] //copy右半部分已排序序列到R中
L[n1+1] ← ∞ //L、R最后一位设置一个极大值作为标志位
R[n2+1] ← ∞
i ← 1
j ← 1
for k ← p to r //进行合并
do if L[i] < R[j]
then A[k] ← L[i]
i ← i + 1
else A[k] ← R[j]
j ← j + 1
使用极大值作为哨兵。
代码实现:
void Merge(int A[],int p,int q,int r)
{
int i,j,k;
int n1=q-p+1;
int n2=r-q;
int *L=new int[n1+1]; //开辟临时存储空间
int *R=new int[n2+1];
for(i=0;i3.2、快速排序
原理:也是利用分治的思想。先找到待排序序列中任意一点作为基准点,将小于基准点的放到基准点左边,大于的放到右边,并以基准点进行分区,递归到最小区间为1则所有数据完成排序。

小技巧:为了实现原地排序,在分区函数中使用数据交换而不是搬移。
性能分析
- 分区极其均衡时,比如两个大小相同的区间,则跟合并排序性能差不多,O(nlogn)。
- 分区极其不均衡时,取决于分区函数的实现,类似于冒泡+选择混合体了,退化到O(n^2)。
虽然均摊分析并不适用于此场景,分析思路可以借鉴,极其不均衡是要求每次分区都达到最不均衡的情况,概率比较小,所以平均时间复杂度还是O(nlogn)。
(作者没有继续分析,我只好挥发聪明才智瞎猜咯~)
实现
private static > int partition(T[] values, int left, int right) {
T pivot = values[right];
int i = left;
for (int j = left; j < right; j++) {
if (values[j].compareTo(pivot) < 0) {
T tmp = values[i];
values[i] = values[j];
values[j] = tmp;
i++;
}
}
T tmp = values[right];
values[right] = values[i];
values[i] = tmp;
return i;
}
private static > void QuickSortC(T[] values, int left, int right) {
if (left >= right)
return;
int partIdx = partition(values, left, right);
QuickSortC(values, left, partIdx - 1);
QuickSortC(values, partIdx + 1, right);
}
public static > void QuickSort(T[] values, int length) {
QuickSortC(values, 0, length - 1);
}
4、线性排序
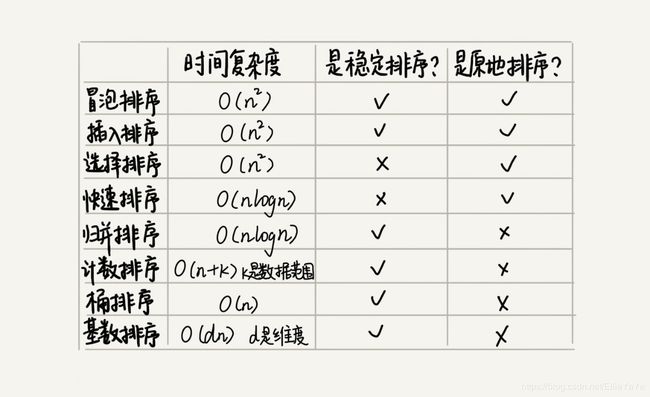
桶排序、计数排序和基数排序都不是基于比较的排序算法,都不涉及元素之间的比较操作,时间复杂度可以达到O(n),也就是线性的。
4.1、桶排序
原理:将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序,排序完之后按照顺序依次取出。

桶排序对数据的要求比较严格:
- 要排序的数据需要很容易就能划分成m个桶
- 桶与桶之间有着天然的大小顺序(桶内排序完成后,桶之间不需要进行排序)
- 数据在桶之间的分布比较均匀。
适用场景:外部排序。数据存储在外部磁盘中,因为内存有限。
4.2、计数排序
看了一下作者给的示意图,然后还让集中精神,就一脸懵逼。
其实好像可以小小总结下更简单呢:
- step1:根据数值范围,按数值单位划分成K个桶。(这样可以不用进行桶内排序)
- step2:每个桶记录的是下表对应数值的个数。(啥也不做的话我们已经知道每个数值有多少个重复的啦)
- step3:从左到右累加。(因为要知道排序后的位置,就需要知道前面有多少个数据,累加完就晓得啦)
数据源:2,5,3,0,2,3,0,3。

|

|
- step4:遍历原始数组,根据“桶”组可以算出数据在排序后的数组中的下标。注意:因为重复的数据是挨着存的,对一个数据排序完毕后,需要对桶存储的值减一。

适用场景:数据范围不大的非负整数。
实现
public static void CountingSort(Integer[] values, int length) {
if (length <= 1)
return;
int max = values[0];
for (int i = 0; i < length; i++) {
if (max < values[i]) {
max = values[i];
}
}
// 构造索引数组并初始化
int[] c = new int[max + 1];
for (int i = 0; i <= max; i++) {
c[i] = 0;
}
// 统计
for (int i = 0; i < length; i++) {
c[values[i]]++;
}
// 累加得到索引值
for (int i = 1; i <= max; i++) {
c[i] += c[i-1];
}
int r[] = new int[length];
for (int i = length - 1; i >= 0; --i) {
int index = c[values[i]] - 1;
r[index] = values[i];
c[values[i]]--;
}
for (int i = 0; i < length; i++) {
values[i] = r[i];
}
}
4.3、基数排序
原理:将待比较的数值分割成位,如果低位能够确定大小则无须继续比较高位。
按照低位优先比较和高位优先比较有两种写法,思路都是一致的。

适用场景:需要可以分割出独立的“位”来比较,而且位之间有递进的关系。
注意:用来比较位的算法必须是稳定的,否则低位的比较结果没有意义。对于非等长的情况可以使用0来补齐。
5、排序算法的优化
一个通用的排序算法需要兼顾性能和适用的数据规模。
5.1、快速排序中分区点选取的优化方向
最坏情况下的快速排序的时间复杂度是O(n^2),主要是分区点的选择影响的。
最理想的分区点是可以对半分。关于采样点的选取,作者给了两条思路(网友给了千千万万个<可能不太靠谱>的思路)
三数取中法
从区间的首、中、尾各取一个元素,选大小为中间值的那个作为分区点。
看上去就是采样的嘛(采样啥的当然是信号处理专业的强项丫~对不起!我给本专业丢脸了!)
随机法
从待排序区间中随机选取一个元素作为分区点。
看上去就像是掷色子(相信科学喵~)
引入随机化快速排序的作用,就是当该序列趋于有序时,能够让效率提高,大量的测试结果证明,该方法确实能够提高效率。但在整个序列数全部相等的时候,随机快排的效率依然很低,它的时间复杂度为O(N^2)。
5.2、递归优化
快速排序跟合并排序最大的不同就是它是先分区排序再进行递归。如果待排序的序列划分极端不平衡,递归的深度将趋近于n,而栈的大小是很有限的,每次递归调用都会耗费一定的栈空间,函数的参数越多,每次递归耗费的空间也越多。优化后,可以缩减堆栈深度。俩思路:
- 限制递归深度
- 通过再堆上模拟一个函数调用栈,手动模拟递归压栈、出栈的过程,来消除系统栈大小的限制。(啥意思?黑人问号)
大概说的是下面这个意思?
private static > void QuickSortC(T[] values, int left, int right) {
if (left >= right)
return;
// int partIdx = partition(values, left, right);
// QuickSortC(values, left, partIdx - 1);
// QuickSortC(values, partIdx + 1, right);
LinkedListStack stack = new LinkedListStack<>();
int partIdx = partition(values, left, right);
if (left < partIdx - 1) {
stack.push(left);
stack.push(partIdx);
}
if (partIdx + 1 < right) {
stack.push(partIdx + 1);
stack.push(right);
}
while(!stack.empty()) {
right = stack.pop();
left = stack.pop();
partIdx = partition(values, left, right);
if (partIdx == left || partIdx == right)
continue;
if (left < partIdx - 1) {
stack.push(left);
stack.push(partIdx);
}
if (partIdx + 1 < right) {
stack.push(partIdx + 1);
stack.push(right);
}
}
}
6、小结
没有小结,谢谢。