多元Huffman树——对BMP灰度图像进行n元哈夫曼编码
在刚刚结束的信息论与编码的课程设计中,我选了对灰度图像进行N元哈夫曼编码这道题。一开始觉得不就是一个哈夫曼树的构建吗有什么难的,数据结构里早就学过了,应该一两个小时就可以写完,但是事实上遇到的问题远远超过我的想象,N元哈夫曼编码写了两天才勉勉强强实现了编码和译码的功能。嗯我知道如果搜博客搜到了我的博客,肯定是冲着代码去的,没错我自己 搜行博客的时候也是抱着这种心态,但是直接抄代码是不好的习惯,在贴代码之前我还是先把整体思路介绍一下。代码仅做参考。这个代码是有小问题的,没时间修了,但是基本的功能还是可以实现。
首先对信源进行N元哈夫曼编码。N哈夫曼编码肯定要构造哈夫曼树。哈夫曼树的构造方式如下:
(1)将所有结点放入一个集合T中
(2)将N个结点组合,变成一个新的结点,这N个结点接在新结点的孩子结点上,从集合中删除这N个结点,并将新结点加入集合T
(3)重复以上步骤直达T中只剩下一个结点,这个结点就是哈夫曼树的根节点
写好哈夫曼树的构造后,就是对信源进行编码了。但是对信源进行编码前还有一件事:哈夫曼编码要知道信源的概率并且从大到小排序。那么对图片进行编码也应当就是先读取图像的所有像素,然后每个像素作为一个信源符号,统计好每个像素(信源符号)的概率(频数),然后排好序,再对每个像素(信源符号)进行编码。读取BMP最开始我考虑了openCV库,但是这个库太大了,配置来配置去肯定又要消耗时间,而且我仅仅只用里面读取图像的像素并变成数组这一个功能,安装一个好几百兆的库肯定是大材小用。那有没有vs上可以直接调用的实现对图像进行读取的库呢?还真让我找到了,GUI+库,具体的代码实现参考别人的博客然后进行了一部分修改,原博客找不到了,实在实在不好意思,如果原作者看到这段代码记得和我联系。统计频率的方法为:先从图片读取像素,然后把每个像素输入到txt中,然后对txt进行遍历,每输入一个像素就查找这个像素是否被统计过,如果没有就新建一个用于统计此像素的结点,如果已经有了,那就把这个像素的频数+1.
概率统计好之后输出到文件,输出的格式为形如:
255(像素值) 1010(频数)
192 1239
然后在构建哈夫曼编码前将信源符号和频数一个个读入,存入集合T中。统计出信源的个数。记得进行N元哈夫曼编码时要满足一个公式:

如果信源个数少了就要生成空的信源。
对图片构造好哈夫曼编码后就可以进行编码了。方法是每读一个像素就查找这个像素的编码(在代码中coderules这个vector存储 了每个信源符号对应的编码),然后将编码输出。
解码的时候有两种方式,一种是匹配,每读入一个符号就放入一个string,然后查找整个编码表有没有这个string对应的信源符号,如果有的话就输出信源符号,并将string置空,如果没有就继续读入一个。
写BMP的方式也是借鉴的别人代码,同样我也找不到原作者了,非常非常抱歉。
有一个很重要的问题,GDI+读图像的时候似乎是从最后开始往前读的,所以读出来的像素顺序是反的,所以由像素矩阵写入的图片也会是反的(稍微修改过后是轴对称的,但是依然没有变成原本的样子)
计算信源熵和平均码长这些东西就不多介绍了,公式书上有,如果你弄懂了我的代码的话,也可以很容易写出来。
好的下面是重头戏了:
HuffmanTree.h
#pragma once
#ifndef _INC_HUFFMANTREE
#define _INC_HUFFMANTREE
/*n元霍夫曼编码,需要有的数据有:自身符号,自身的权值(概率),指向孩子的指针数组(如果是二元的话)直接左孩子右孩子就可以了,但是
由于是n元,无法确定n的大小,所以采用指针数组的方式,动态生成所需要的数组,在数组中由左至右依次是1孩子2孩子3孩子......
(是否需要一个往上指的指针?)还需要有自身的编码*/
#include
#include
#include
#include
#include
#include
#include
#pragma comment(lib, "gdiplus.lib")
using namespace std ;
using namespace Gdiplus;
struct MessageSource//用来表达信源符号的,第一个是信源符号,第二个是对应的频率
{
int symbol = 0;
unsigned int frequence = 0;
};
class Node
{
public:
Node(int c) {
n = c;
childs= new Node*[n];
for (int i = 0; i < n; i++)
{
childs[i] = nullptr;
}
}
Node() {
n = 2;
childs = new Node*[n];
for (int i = 0; i < n; i++)
{
childs[i] = nullptr;
}
}
string symbol;
unsigned long int weight = 0;//权值
Node** childs;
vector
void showChild() {
for (int i=0;i<4;i++)
{
childshow[i] = *(childs + i);//只是用来显示用
}
}
private:
int n=2;
Node* childshow[4];//只是用来显示用
};
//操作符重载,为了实现两个节点的比较
bool operator>(const Node &a, const Node &b);
bool operator<(const Node &a, Node &b);
/*如果是n元哈夫曼树,如果把这n个结点全部传入Add函数?如果用一个个传参的方法肯定不行,必须得重载两个Node相加直到n个Node相加的函数
可以把这些结点放入一个vector,然后依次把这些结点加起来,同时把孩子指针指向他们。为了方便孩子从左到右的顺序,在放入vector时就应该从
大到小的顺序排好,这里写一个降序排序的方法,将vector排序,这个函数用在sort中,使用方法sort(a.begin(),a.end(),Greatorsort)*/
bool Greatorsort(Node* a, Node* b);
class Code
{
public:
Code() {};
~Code() {};
int symbol;
string code;
unsigned long int weight = 0;
};
class HuffmanTree//n元霍夫曼编码,需要有的数据有:自身的权值(概率),指向孩子的指针数组(如果是二元的话)
{
public:
HuffmanTree(int c) {
n = c;
}
HuffmanTree() {
n = 2;
}
public:
/*一个集合T,用来存放结点,包括新组成的结点*/
vector
Node* root;//根节点
void init();
void buildHaffmanTree();
Node* Add(vector
void travel(Node* p);
void encode(Node* p);
vector
void setCodeRules(Node* pNode);
void readBMP();
void culculateFrequency();
vector
int find(int c);//用来查找c这个信源有没有统计过,如果有频率+1,如果没有就新建
void EncodeBMP();
string findCode(int c);
UINT height = 0;//图片高度和宽度
UINT width = 0;
int sourcecount = 0;
bool isLeaf(Node* p);//用来判断某个结点是不是叶子节点,如果是叶子结点则说明可以解码,如果不是则继续
void decode(Node* p);
void avglong();//平均码长
double avglength = 0;
void InformationEntropy();//求信息熵的函数
double Entropy = 0;
private:
int n=2;
int q;
int Q;
int θ;
};
#endif // !1
HuffmanTree.cpp
#include "HuffmanTree.h"
#include
#include
#include
#include
#include
bool operator>(const Node &a, const Node &b)
{
if (a.weight > b.weight) return true;
else
{
return false;
}
}
bool operator<(const Node &a, Node &b)
{
if (a.weight < b.weight)return true;
return false;
}
bool Greatorsort(Node* a, Node* b) {
return a->weight > b->weight;
}
void HuffmanTree::init()
{
//先完成需要进行哈夫曼树构造的结点的初始化
//cout << "请输入信源符号个数:";
//cin >> q;
q = sourcecount;
Q = q;
/*cout << "请输入n元霍夫曼编码的n:";
cin >> n;*/
//别忘了如果不符合公式,要添加空结点,
while ((q - n) % (n - 1) != 0) q++;
cout << "请输入信源符号和对应的概率:" << endl;
cout << "从文件读取:";
ifstream fin("e:/frequence.txt");
for (int i = 0; i < Q; i++)
{
Node* newNode = new Node(n);
fin >> newNode->symbol >> newNode->weight;
nodeset.push_back(newNode);
}
if (Q != q)//添加空结点
{
for (int i = Q; i
string t = "null" + std::to_string(i + 1);//因为书上是从s1开始的,下标从0开始
Node* nullNode = new Node(n);
nullNode->symbol = t; nullNode->weight = 0;
nodeset.push_back(nullNode);
}
}
sort(nodeset.begin(), nodeset.end(), Greatorsort);
}
Node* HuffmanTree::Add(vector
{
Node* newNode = new Node(n);
//因为是n元哈夫曼树,所以应该是n个结点组成一个新结点,即新结点的孩子有n个
newNode->symbol = "tNode";
for (int i = 0; i < n; i++)
{
newNode->weight += t[i]->weight;
}
//下一步要把孩子指针数组构建好,在构建之前vector必须已经排好序了,为了防止没有排序再排序一次
sort(t.begin(), t.end(), Greatorsort);
for (int i = 0; i < n; i++)
{
newNode->childs[i] = t[i];
}
newNode->showChild();
return newNode;
}
void HuffmanTree::buildHaffmanTree()
{
//从集合中选取n个权值(概率)最小的结点,然后将他们组成新的结点,随后将这n个结点删除,并将新结点添加进集合,直到只剩下最后一个,这个就是根节点
while (nodeset.size() != 1)
{
vector
for (int i = 0; i
int j = nodeset.size() - n + i;//选中后n个中的第一个
tempvector.push_back(nodeset[j]);
}
//然后删掉后n个
for (int i = 0; i
nodeset.pop_back();
}
Node* newNode = Add(tempvector);
//插入指定的位置
/*int weight = newNode->weight;*/
int i = 0;
/*bool tag = nodeset[i] > newNode;
bool tag1 = i < nodeset.size();*/
while (nodeset.size()>0 && nodeset[i]->weight>newNode->weight && (i
i++;
}
if (i == nodeset.size() - 1)
{
nodeset.push_back(newNode);//如果是要插入在最后面,应该用push_back,因为instert()是插入第i个下标前面,如果是最后一个i就会越界
}
else
{
nodeset.insert(nodeset.begin() + i, newNode);
}//0的时候会不会出问题?要试一下--嗯0出问题了
}
root = nodeset[0];
}
void HuffmanTree::travel(Node* pNode)
{
stack
stack.push(pNode);
Node *lpNode;
while (!stack.empty())
{
lpNode = stack.top();
stack.pop();
//Deal();
//处理遍历输出的函数
cout.setf(ios::left);
cout <
for (int i = 0; i < lpNode->encode.size(); i++)
{
cout <
}
cout << endl;
for (int i = n-1; i >=0; i--)
{
if(lpNode->childs[i])
stack.push(lpNode->childs[i]);
}
}
}
void HuffmanTree::encode(Node* pNode)
{
stack
stack
nodestack.push(pNode);
Node *lpNode;
while (!nodestack.empty())
{
lpNode = nodestack.top();
nodestack.pop();
//Deal();
//处理的函数
int j = 0;
for (int i = n - 1; i >= 0; i--)
{
if (lpNode->childs[i]) {
//要先把父节点的编码拷进去
for (int k=0;k
{
//lpNode->childs[i]->encode[k].append(lpNode->encode[k]);
lpNode->childs[i]->encode.push_back(lpNode->encode[k]);
}
lpNode->childs[i]->encode.push_back(std::to_string(i));
nodestack.push(lpNode->childs[i]);
}
j++;
}
}
}
void HuffmanTree::setCodeRules(Node* pNode)
{
stack
stack.push(pNode);
Node *lpNode;
while (!stack.empty())
{
lpNode = stack.top();
stack.pop();
//Deal();
//处理遍历输出的函数
//cout << setw(10) << lpNode->symbol << " " << setw(10) << lpNode->weight << " " << "编码:";
Code *code = new Code();
if (lpNode->symbol!="tNode")//如果是tNode就不需要添加进去
{
code->symbol = atoi(lpNode->symbol.c_str());//将string转成int,因为在Code中符号是int,也是为了在解码的时候可以直接从int转化
for (int i = 0; i < lpNode->encode.size(); i++)
{
code->code.append(lpNode->encode[i]);
}
code->weight = lpNode->weight;
coderule.push_back(code);
}
for (int i = n - 1; i >= 0; i--)
{
if (lpNode->childs[i])
stack.push(lpNode->childs[i]);
}
}
cout << "编码构造成功!" << endl;
}
void HuffmanTree::readBMP()
{
cout << "正在读取图片......"<
ULONG_PTR gdiplustoken;
GdiplusStartup(&gdiplustoken, &gdiplusstartupinput, nullptr);
wstring infilename(L"e:/xxl/read.bmp");
string outfilename("e:/xxl/color.txt");
//读图片
Bitmap* bmp = new Bitmap(infilename.c_str());
height = bmp->GetHeight();
width = bmp->GetWidth();
cout << "width " << width << ", height " << height << endl;
Color color;
ofstream fout(outfilename.c_str());
for (int y = 0; y < height; y++)
for (int x = 0; x < width; x++)
{
bmp->GetPixel(x, y, &color);
fout << x << " " << y << " "
<< (int)color.GetRed() <<
/*<< (int)color.GetGreen() << ";"
<< (int)color.GetBlue() << */endl;//因为读取的时候灰度图像,所以RGB三个分量是一样的
}
string outfilename1("e:/xxl/pixel.txt");
ofstream fout1(outfilename1.c_str());
for (int y = 0; y < height; y++)
for (int x = 0; x < width; x++)
{
bmp->GetPixel(x, y, &color);
fout1 << (int)color.GetRed() << " ";//直接写进像素
}
fout.close();
fout1.close();
delete bmp;
GdiplusShutdown(gdiplustoken);
cout << "图片像素输出完成!" << endl;
return ;
}
int HuffmanTree::find(int c)
{
for (int i = 0; i < List.size(); i++)
{
if (c == List[i]->symbol)
{
return i;
}
}
return -1;
}
void HuffmanTree::culculateFrequency()
{
ifstream fin;
ofstream fout;
string temp = "e:/xxl/pixel.txt";
fin.open(temp.c_str(), ios::in);
fout.open("e:/xxl/frequence.txt");
int c = 0;
cout << "开始统计频率......" << endl;
while (!fin.eof())
{
fin >> c;
int t = find(c);
if (t != -1)
{
List[t]->frequence++;
}
else
{
MessageSource *msgs = new MessageSource;
msgs->frequence = 1;
msgs->symbol = c;
List.push_back(msgs);
sourcecount++;
}
}
for (int i = 0; i < List.size(); i++)
{
fout << List[i]->symbol << " " << List[i]->frequence << endl;
}
fin.close();
fout.close();
cout << "频率统计完成!" << endl;
}
string HuffmanTree::findCode(int c)
{
for (int i = 0; i < coderule.size(); i++)
{
if (coderule[i]->symbol == c)
return coderule[i]->code;
else if (c==-1)
{
return "";
}
}
return "";
}
void HuffmanTree::EncodeBMP()
{
cout << "正在进行编码......" << endl;
ifstream fin("e:/xxl/pixel.txt");
ofstream fout("e:/xxl/encode.txt");
while (!fin.eof())
{
int c = -1;
fin >> c;
string s = findCode(c);
fout << s;
}
cout << "编码完成!" << endl;
}
bool HuffmanTree::isLeaf(Node* p)
{
bool flag = true;
for (int i = 0; i < n; i++)
{
if (p->childs[i]!=NULL)
{
flag = false;
}
}
return flag;
}
void HuffmanTree::decode(Node* p)
{
cout << "开始解码......";
ifstream fin("e:/xxl/encode.txt");
ofstream fout("e:/xxl/decode.txt");
string temp;//这个string用来存放还没有解码之前扫描过的字符串
int i = 0;
//int j = 0;
while (!fin.eof() && i < height*width)
{
char s;
fin >> s;
temp += s;
int t = (int)(s - 0x30);//码元不能超过9,不然就会出错
p = p->childs[t];
if (isLeaf(p))
{
fout << p->symbol<<" ";
temp = "";
i++; //j++;
/*if (j==width)
{
fout << "\n";
j = 0;
}*/
p = root;
}
}cout << i;
cout << "解码完成!";
fin.close();
fout.close();
}
void HuffmanTree::avglong()
{
unsigned long int sum = root->weight;
for (int i=0;i
double gailv = ((double)coderule[i]->weight) / (double)sum;
avglength += gailv * coderule[i]->code.size();
}
cout << "平均码长为:" << avglength << endl;
}
void HuffmanTree::InformationEntropy()
{
unsigned long int sum = root->weight;
for (int i=0;i
Entropy +=-((double)coderule[i]->weight / (double)sum)*(log10((double)coderule[i]->weight / (double)sum)/log10((double)2));//-p(ai)*(logp(ai))
}
cout << "信源熵为:" << Entropy << endl;
cout << "编码效率=" << Entropy / avglength*100 << '%' << endl;
}
writeBMP.h
#pragma once
#include
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include
#include
using namespace std;
//typedef long BOOL;
typedef long LONG;
typedef unsigned char BYTE;
typedef unsigned long DWORD;
typedef unsigned short WORD;
//位图文件头文件定义
//其中不包括文件类型信息(由于结构体的内存结构决定,要是加了的话将不能正确的读取文件信息)
typedef struct {
WORD bfType;//文件类型,必须是0x424D,即字符“BM”
DWORD bfSize;//文件大小
WORD bfReserved1;//保留字
WORD bfReserved2;//保留字
DWORD bfOffBits;//从文件头到实际位图数据的偏移字节数
} BMPFILEHEADER_T;
struct BMPFILEHEADER_S {
WORD bfType;
DWORD bfSize;
WORD bfReserved1;
WORD bfReserved2;
DWORD bfOffBits;
};
typedef struct {
DWORD biSize;//信息头大小
LONG biWidth;//图像宽度
LONG biHeight;//图像高度
WORD biPlanes;//位平面数,必须为1
WORD biBitCount;//每像素位数
DWORD biCompression;//压缩类型
DWORD biSizeImage;//压缩图像大小字节数
LONG biXPelsPerMeter;//水平分辨率
LONG biYPelsPerMeter;//垂直分辨率
DWORD biClrUsed;//位图实际用到的色彩数
DWORD biClrImportant;//本位图中重要的色彩数
} BMPINFOHEADER_T;//位图信息头定义
void generateBmp(BYTE * pData, int width, int height, char * filename);
int writebmp(int height, int width);
writeBMP.cpp
#include "writebmp.h"
void generateBmp(BYTE * pData, int width, int height, char * filename)//生成Bmp图片,传递RGB值,传递图片像素大小,传递图片存储路径
{
int size = width * height * 3; // 每个像素点3个字节
// 位图第一部分,文件信息
BMPFILEHEADER_T bfh;
bfh.bfType = 0X4d42; //bm
bfh.bfSize = size // data size
+ sizeof(BMPFILEHEADER_T) // first section size
+ sizeof(BMPINFOHEADER_T) // second section size
;
bfh.bfReserved1 = 0; // reserved
bfh.bfReserved2 = 0; // reserved
bfh.bfOffBits = bfh.bfSize - size;
// 位图第二部分,数据信息
BMPINFOHEADER_T bih;
bih.biSize = sizeof(BMPINFOHEADER_T);
bih.biWidth = width;
bih.biHeight = height;
bih.biPlanes = 1;
bih.biBitCount = 24;
bih.biCompression = 0;
bih.biSizeImage = size;
bih.biXPelsPerMeter = 0;
bih.biYPelsPerMeter = 0;
bih.biClrUsed = 0;
bih.biClrImportant = 0;
FILE * fp = fopen(filename, "wb");
if (!fp) return;
fwrite(&bfh, 1, sizeof(BMPFILEHEADER_T), fp);
fwrite(&bih, 1, sizeof(BMPINFOHEADER_T), fp);
fwrite(pData, 1, size, fp);
fclose(fp);
}
int writebmp(int height, int width)
{
std::cout << "正在写入图片......";
int i = 0, j = 0;
struct pRGB {
BYTE b;
BYTE g;
BYTE r;
}; // 定义位图数据
pRGB *p = new pRGB[height*width];
ifstream fin("e:/xxl/decode.txt");
const char* decodebmp = "e:/xxl/write.bmp";
memset(p, 0, height*width); // 设置背景为黑色
// 在中间画一个100*100的矩形
for (i = height - 1; i >= 0; i--) {
for (j = width-1; j >= 0; j--) {
// pRGB[i][j].r = 0xff;
int t; fin >> t;
p[i*width + j].r = t;
p[i*width + j].g = t;
p[i*width + j].b = t;
}
}
// 生成BMP图片
generateBmp((BYTE*)p, width, height, (char*)decodebmp);
cout << "写入图片完成!";
return 0;
}
main.cpp
#include
#include "HuffmanTree.h"
#include "writebmp.h"
using namespace std;
int main()
{
cout << "请输入是多少元哈夫曼编码:";
int c = 0;
cin >> c;
HuffmanTree *hfmtree = new HuffmanTree(c);
hfmtree->readBMP();
hfmtree->culculateFrequency();
hfmtree->init();
hfmtree->buildHaffmanTree();
hfmtree->encode(hfmtree->root);
hfmtree->travel(hfmtree->root);
hfmtree->setCodeRules(hfmtree->root);
hfmtree->EncodeBMP();
hfmtree->decode(hfmtree->root);
hfmtree->avglong();
hfmtree->InformationEntropy();
cout << "是否解码讲解码的文件写入图片?Y或y确定:";
char y; cin >> y;
if (y=='y'||y=='Y')
{
writebmp(hfmtree->height, hfmtree->width);
}
system("pause");
return 0;
}
我也不知道怎么设置代码高亮,就将就看看吧先。
最后的结果:
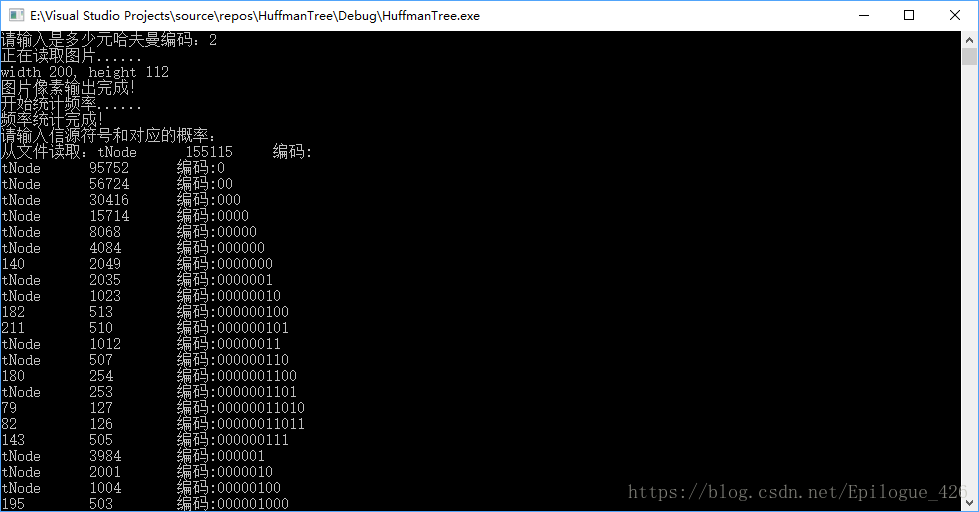
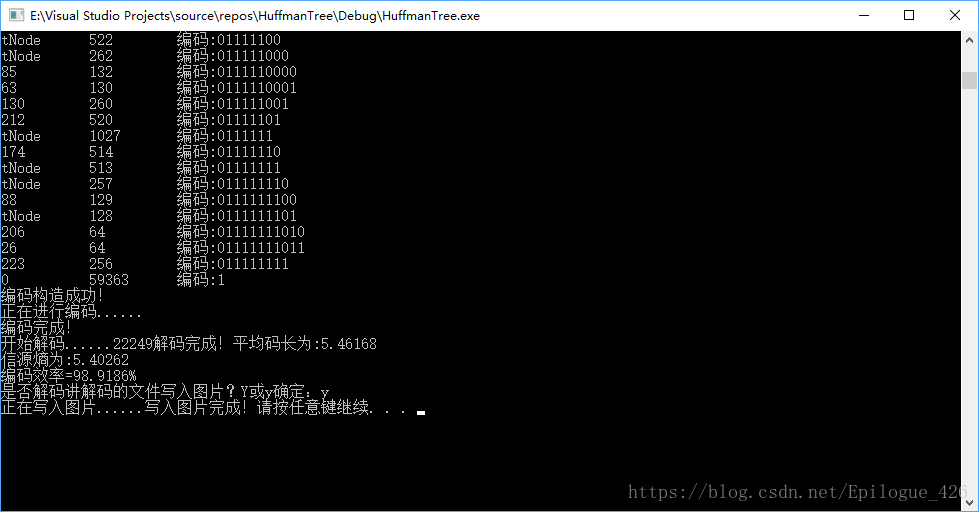
也可以进行n元的,不过虽然可以进行多元哈夫曼树的构造,却不能进行超过十元以上的哈夫曼编码,因为10和1,0会产生奇异码
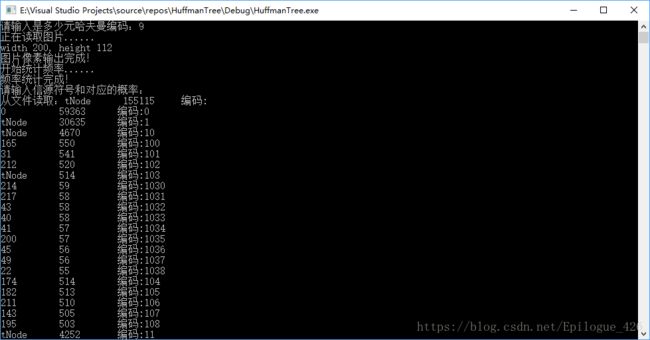
我的博客:why426.top