kotlin学习日记(七)函数式编程
函数式编程(FP)
啥是函数式编程?
函数式编程是种编程方式,它将电脑运算视为函数的计算。函数编程语言最重要的基础是λ演算(lambda calculus),而且λ演算的函数可以接受函数当作输入(参数)和输出(返回值)。这是百度百科的解释。
和指令式编程相比,函数式编程的思维方式更加注重函数的计算。它的主要思想是把问题的解决方案写成一系列嵌套的函数调用。
详细的资料这些都不介绍了,网上一搜一大堆,可以看看函数式编程的历史,背景和详细的定义。
这东西不少Kotlin特有的,例如,
特性:
(直接抄百度百科)这个需要了解
[1,2,3].forEach(print);
面向函数编程(FOP)
在面向函数编程里面,一切皆是函数。
函数式编程(FP)是关于不变性和函数组合的一种编程范式。
函数式编程语言实现重用的思路很不一样。函数式语言提倡在有限的几种关键数据结构(如list、set、map)上 , 运用函数的组合 ( 高阶函数) 操作,自底向上地来构建世界。
当然,我们在工程实践中,是不能极端地追求纯函数式的编程的。一个简单的原因就是:性能和效率。例如:对于有状态的操作,命令式操作通常会比声明式操作更有效率。纯函数式编程是解决某些问题的伟大工具,但是在另外的一些问题场景中,并不适用。因为副作用总是真实存在。
OOP喜欢自顶向下架构层层分解(解构),FP喜欢自底向上层层组合(复合)。 而实际上,编程的本质就是次化分解与复合的过程。通过这样的过程,创造一个美妙的逻辑之塔世界。
我们经常说一些代码片段是优雅的或美观的,实际上意味着它们更容易被人类有限的思维所处理。
对于程序的复合而言,好的代码是它的表面积要比体积增长的慢。 代码块的“表面积”是是我们复合代码块时所需要的信息(接口API协议定义)。代码块的“体积”就是接口内部的实现逻辑(API内部的实现代码)。
在OOP中,一个理想的对象应该是只暴露它的抽象接口(纯表面, 无体积),其方法则扮演箭头的角色。如果为了理解一个对象如何与其他对象进行复合,当你发现不得不深入挖掘对象的实现之时,此时你所用的编程范式的原本优势就荡然无存了。
FP通过函数组合来构造其逻辑系统。FP倾向于把软件分解为其需要执行的行为或操作,而且通常采用自底向上的方法。函数式编程也提供了非常强大的对事物进行抽象和组合的能力。
在FP里面,函数是“一类公民”(first-class)。它们可以像1, 2, "hello",true,对象…… 之类的“值”一样,在任意位置诞生,通过变量,参数和数据结构传递到其它地方,可以在任何位置被调用。
而在OOP中,很多所谓面向对象设计模式(design pattern),都是因为面向对象语言没有first-class function(对应的是多态性),所以导致了每个函数必须被包在一个对象里面(受约束的函数指针)才能传递到其它地方。
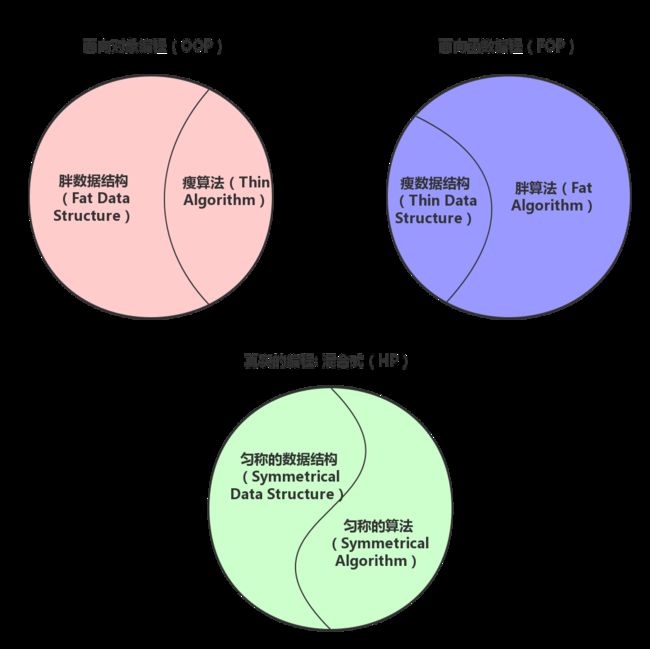
匀称的数据结构 + 匀称的算法
在面向对象式的编程中,一切皆是对象(偏重数据结构、数据抽象,轻算法)。我们把它叫做:胖数据结构-瘦算法(FDS-TA)。
在面向函数式的编程中,一切皆是函数(偏重算法,轻数据结构)。我们把它叫做:瘦数据结构-胖算法(TDS-FA)。
可是,这个世界很复杂,你怎么能说一切皆是啥呢?真实的编程世界,自然是匀称的数据结构结合匀称的算法(SDS-SA)来创造的。
我们在编程中,不可能使用纯的对象(对象的行为方法其实就是函数),或者纯的函数(调用函数的对象、函数操作的数据其实就是数据结构)来创造一个完整的世界。如果数据结构是阴,算法是阳,那么在解决实际问题中,往往是阴阳交合而成世界。还是那句经典的:
程序 = 匀称的数据结构 + 匀称的算法
我们用一幅图来简单说明:
 函数与映射
函数与映射
一切皆是映射。函数式编程的代码主要就是“对映射的描述”。我们说组合是编程的本质,其实,组合就是建立映射关系。
一个函数无非就是从输入到输出的映射,写成数学表达式就是:
f: X -> Y p:Y -> Z p(f) : X ->Z
用编程语言表达就是:
fun f(x:X) : Y{}
fun p(y:Y) : Z{}
fun fp(f: (X)->Y, p: (Y)->Z) : Z {
return {x -> p(f(x))}
}(来源:Kotlin极简教程)
高阶函数
高阶函数用另一个函数作为其输入参数,也可以返回一个函数作为输出。
f(g(x))
lambda表达式
“Lambda 表达式”(lambda expression)是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象(lambda abstraction),是一个匿名函数,即没有函数名的函数。Lambda表达式可以表示闭包(注意和数学传统意义上的不同)。
lambda表达式很简洁而且可读。