Hadoop MR InputFormat/OutputFormat
常见的InputFormat&OutputFormat
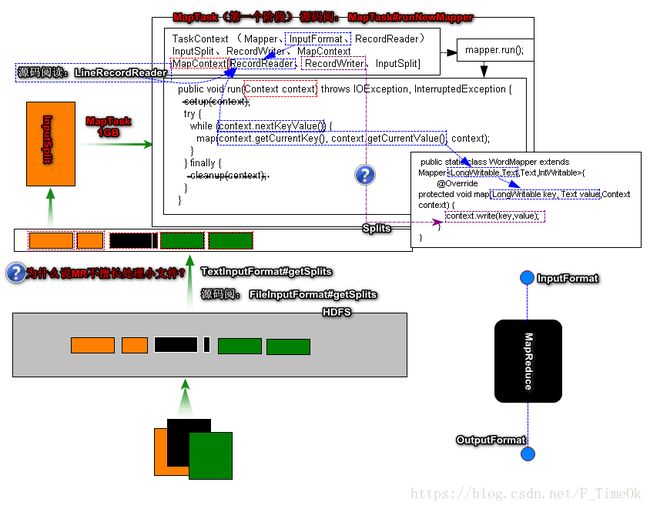
InputFormat作用是为MapTask任务(第一阶段 归类/分析)阶段准备需要分类的数据信息。
InputFormat的核心作用1、计算任务切片2、读取切片数据RecordReader。
InputForamt:
① FileIputFormat (负责读取HDFS数据)
a)TextInputForamt (处理文本文件)
★ 切片计算方式 文件单位 按照splitSize
★ RecordReader读取方式 - LongWritable、Text
b)CombineTextInputFormat(处理小文件)
★ 切片计算方式 按照splitSize
★ RecordReader读取方式 - LongWritable、Text
c)MultipleInputs(处理不同格式类型文件)
d)NLineInputFormat (处理不同格式类型文件) (处理不同格式类型文件)
★ 切片方式 文件单位,按照N行Split
★ RecordReader读取方式 - LongWritable、Text
e)KeyValueTextInputFormat (处理不同格式类型文件) (处理不同格式类型文件)
② DBInputForamt (负责读取RDBMS 数据,不常用!)
③ CompositeInputFormat
OutputFormat作为ReduceTask任务(第二阶段 汇总)阶段,主要对Reducer的输出结果写入到目标文件系统或者数据库!
OutputFormat::
① FileoutputFormat (负责将结果写入HDFS中)
a)TextInputForamt (处理文本文件)
★ TextOutputFormat (将结果以文本的形式写入HDFS中)
② DBOutputFormat (负责将数据写入到RDBMS数据库)
③ Multipleoutputs
以下案例均基于本地仿真
案例1:现有文本数据分别代表订单项编号,商品名称,商品价格,商品数量,购买的用户id
001,香蕉,1.5,10,10001
002,苹果,1.2,5,10001
003,西瓜,2,5,10002
004,葡萄,3,10,10002
005,橘子,1,3,10002需要统计出每个用户购买的商品列表和花费的总价钱并写入数据库中。
示意结果:如下所示
mysql> select * from t_total;
+---------+--------------------+-------+
| user_id | items | total |
+---------+--------------------+-------+
| 10001 | [苹果, 香蕉] | 21 |
| 10002 | [橘子, 葡萄, 西瓜] | 43 |
+---------+--------------------+-------+import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class TestToDBCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//通过conf创建数据库配置信息
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://localhost:3306/test?characterEncoding=UTF-8","root","root");
//1.创建job
Job job = Job.getInstance(conf);
//2.设置数据的格式类型 决定读入和写出的数据的方式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(DBOutputFormat.class);
TextInputFormat.addInputPath(job, new Path("file:///E:\\hadoop_test\\db\\dbs"));
DBOutputFormat.setOutput(job, "t_total", "user_id","items","total");
//4.设置数据的处理规则
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
//5.设置Mapper和Reducer的key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(MyDBOutputWritable.class);
job.setOutputValueClass(NullWritable.class);
//6.提交任务job
job.waitForCompletion(true);
}
static class MyMapper extends Mapper {
@Override
protected void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
String[] split = values.toString().split(",");
String name = split[1];
double price = Double.parseDouble(split[2]);
int count = Integer.parseInt(split[3]);
String user_id = split[4];
context.write(new Text(user_id), new Text(name+","+price+","+count));
}
}
static class MyReduce extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
double total =0;
List items = new ArrayList();
for (Text value : values) {
String[] split = value.toString().split(",");
total += Double.parseDouble(split[1]) * Integer.parseInt(split[2]);
items.add(split[0]);
}
MyDBOutputWritable myOutputWritable = new MyDBOutputWritable();
myOutputWritable.setUser_id(key.toString());
myOutputWritable.setItems(items.toString());
System.out.println(items);
myOutputWritable.setTotal(total);
context.write(myOutputWritable, NullWritable.get());
}
}
}
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class MyDBOutputWritable implements DBWritable {
private String user_id;
private String items;
private Double total;
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1, user_id);
statement.setString(2, items);
statement.setDouble(3, total);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
}
public String getUser_id() {
return user_id;
}
public void setUser_id(String user_id) {
this.user_id = user_id;
}
public String getItems() {
return items;
}
public void setItems(String items) {
this.items = items;
}
public Double getTotal() {
return total;
}
public void setTotal(Double total) {
this.total = total;
}
}
案例2:现有数据库数据分别代表订单项编号,商品名称,商品价格,商品数量,购买的用户id
mysql> select * from t_item;
+-----+------+-------+-------+---------+
| id | name | price | count | user_id |
+-----+------+-------+-------+---------+
| 001 | 香蕉 | 1.50 | 10 | 10001 |
| 002 | 苹果 | 1.20 | 5 | 10001 |
| 003 | 西瓜 | 2.00 | 5 | 10002 |
| 004 | 葡萄 | 3.00 | 10 | 10002 |
| 005 | 橘子 | 1.00 | 3 | 10002 |
+-----+------+-------+-------+---------+需要统计出每个用户购买的商品列表和花费的总价钱并写入本地文件中。
示意图如下:
10001 [苹果, 香蕉] 21.0
10002 [橘子, 葡萄, 西瓜] 43.0import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class FromDBDatas {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//通过conf创建数据库配置信息
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://localhost:3306/test?characterEncoding=UTF-8","root","root");
//1.创建job
Job job = Job.getInstance(conf);
//2.设置数据的格式类型 决定读入和写出的数据的方式
job.setInputFormatClass(DBInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//3.指定数据的读入和写入位置
String query = "select name,price,count,user_id from t_item";
String countQuery = "select count(*) from t_item";
DBInputFormat.setInput(job, MyDBInputWritable.class, query, countQuery);
Path path = new Path("file:///E:\\hadoop_test\\db\\res");
//如果生成结果文件的目录存在则删除
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(path)){
fileSystem.delete(path, true);
}
TextOutputFormat.setOutputPath(job, path);
//4.设置数据的处理规则
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
//5.设置Mapper和Reducer的key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(MyDBInputWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//6.提交任务job
job.waitForCompletion(true);
}
static class MyMapper extends Mapper {
@Override
protected void map(LongWritable key, MyDBInputWritable value, Context context) throws IOException, InterruptedException {
context.write(new Text(value.getUser_id()), value);
}
}
static class MyReduce extends Reducer{
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
double total=0;
List items=new ArrayList();
for (MyDBInputWritable value : values) {
total+=value.getTotal();
items.add(value.getName());
}
context.write(key,new Text(items+"\t"+total));
}
}
} import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class MyDBInputWritable implements DBWritable,Writable{
//从数据库读属性
private String user_id;
private String name;
private double total;
@Override
public void write(PreparedStatement statement) throws SQLException {
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
user_id = resultSet.getString("user_id");
name = resultSet.getString("name");
total = resultSet.getDouble("price")*resultSet.getInt("count");
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeDouble(total);
}
@Override
public void readFields(DataInput in) throws IOException {
name = in.readUTF();
total = in.readDouble();
}
public String getUser_id() {
return user_id;
}
public void setUser_id(String user_id) {
this.user_id = user_id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getTotal() {
return total;
}
public void setTotal(double total) {
this.total = total;
}
}
案例3:现有数据库数据分别代表订单项编号,商品名称,商品价格,商品数量,购买的用户id
mysql> select * from t_item;
+-----+------+-------+-------+---------+
| id | name | price | count | user_id |
+-----+------+-------+-------+---------+
| 001 | 香蕉 | 1.50 | 10 | 10001 |
| 002 | 苹果 | 1.20 | 5 | 10001 |
| 003 | 西瓜 | 2.00 | 5 | 10002 |
| 004 | 葡萄 | 3.00 | 10 | 10002 |
| 005 | 橘子 | 1.00 | 3 | 10002 |
+-----+------+-------+-------+---------+
需要统计出每个用户购买的商品列表和花费的总价钱并写入数据库中。
示意结果:如下所示
mysql> select * from t_total;
+---------+--------------------+-------+
| user_id | items | total |
+---------+--------------------+-------+
| 10001 | [苹果, 香蕉] | 21 |
| 10002 | [橘子, 葡萄, 西瓜] | 43 |
+---------+--------------------+-------+import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class TestFromDBToDBCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//通过conf创建数据库配置信息
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://localhost:3306/test?characterEncoding=UTF-8","root","root");
//1.创建job
Job job = Job.getInstance(conf);
//2.设置数据的格式类型 决定读入和写出的数据的方式
job.setInputFormatClass(DBInputFormat.class);
job.setOutputFormatClass(DBOutputFormat.class);
String query = "select name,price,count,user_id from t_item";
String countQuery = "select count(*) from t_item";
DBInputFormat.setInput(job, MyDBWritable.class, query, countQuery);
DBOutputFormat.setOutput(job, "t_total", "user_id","items","total");
//4.设置数据的处理规则
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
//5.设置Mapper和Reducer的key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(MyDBWritable.class);
job.setOutputKeyClass(MyDBWritable.class);
job.setOutputValueClass(NullWritable.class);
//6.提交任务job
job.waitForCompletion(true);
}
static class MyMapper extends Mapper {
@Override
protected void map(LongWritable key, MyDBWritable value, Context context) throws IOException, InterruptedException {
context.write(new Text(value.getUser_id()), value);
}
}
static class MyReduce extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
double total = 0;
List items = new ArrayList();
for (MyDBWritable value : values) {
total += value.getTotal();
items.add(value.getName());
}
MyDBWritable myDBWritable = new MyDBWritable();
myDBWritable.setUser_id(key.toString());
myDBWritable.setItems(items.toString());
myDBWritable.setTotal(total);
context.write(myDBWritable, NullWritable.get());
}
}
} import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class MyDBWritable implements DBWritable,Writable{
private String user_id;
private String name;
private double total;
private String items;
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1, user_id);
statement.setString(2, items);
statement.setDouble(3, total);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
user_id = resultSet.getString("user_id");
name = resultSet.getString("name");
total = resultSet.getDouble("price")*resultSet.getInt("count");
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeDouble(total);
}
@Override
public void readFields(DataInput in) throws IOException {
name = in.readUTF();
total = in.readDouble();
}
public String getUser_id() {
return user_id;
}
public void setUser_id(String user_id) {
this.user_id = user_id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getTotal() {
return total;
}
public void setTotal(double total) {
this.total = total;
}
public String getItems() {
return items;
}
public void setItems(String items) {
this.items = items;
}
}