使用卷积神经网络对CIFAR-10数据集进行预测
摘要:本文基于Yann Lecun的论文“Gradient-Based Learning Applied to Document Recognition”中提出的LeNet-5卷积神经网络模型,结合Alex Krizhevsky所描述的架构并使用谷歌的机器智能开源软件库TensorFlow中示例程序构建了带有归一化层的多层卷积神经网络模型。该模型是一个由交替卷积和非线性组成的多层体系结构,最后使用多层全连接网络与softmax分类器连接。模型使用交叉熵损失函数对预测结果进行评价并在训练过程中使用Adma优化算法代替传统的梯度下降算法,使得算法收敛速度得以加快。本文所使用的数据集为Cifar-10官网中二进制文件数据集,使用Cifar-10的5个batch进行训练和其所提供的测试数据集进行模型检验,模型在使用单个CPU进行10000次迭代大约训练90分钟的情况下预测正确率达到76%的精度。本文记录每10次迭代后的损失函数值并绘图进行讨论,同时比较了不同迭代次数下的预测正确率关系,对于在训练时间和预测正确率的权衡上有一定的指导意义。
关键词:卷积神经网络、TensorFlow、CIFAR-10、LenNet-5
1. 卷积神经网络
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,[1]对于大型图像处理有出色表现。
卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构[2]。
一种卷积神经网络各个层级结构,如下图所示:

图1.1 一种CNN的结构
1.1. 卷积层
卷积层(Convolutional layer),卷积神经网络中每层卷积层由若干卷积单元组成。卷积层是卷积核在上一级输入层上通过逐一滑动窗口计算而得,将卷积核的各个参数与对应的局部像素值相乘之和,(通常还要再加上一个偏置参数),得到卷积层上的结果。图1.1.1表示了一次卷积运算的例子。

图1.1.1 卷积核大小为3*3的一次卷积运算
卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
1.2. 线性整流层
线性整流层(Rectified Linear Units layer, ReLU layer)使用线性整流(Rectified Linear Units, ReLU)作为这一层神经的激励函数(Activation function),其函数图像图如图所示。它可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层。
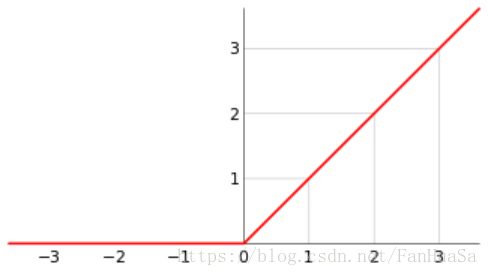
图1.2.1 ReLU函数图
1.3. 池化层
池化(Pooling)是卷积神经网络中另一个重要的概念,它实际上是一种形式的降采样。有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见的,如图1.3.1所示。

图1.3.1 进行2*2最大池化操作
除了最大池化之外,池化层也可以使用其他池化函数,例如“平均池化”甚至“L2-范数池化”等。过去,平均池化的使用曾经较为广泛,但是最近由于最大池化在实践中的表现更好,平均池化已经不太常用。[3]
每一个卷积核可以看做一个特征提取器,不同的卷积核负责提取不同的特征,那么我们对其进行池化操作后,提取出的是真正能够识别特征的数值,其余被舍弃的数值,对于我提取特定的特征并没有特别大的帮助。从而减少了参数,达到减小计算量且不损失效果的情况。
1.4. 损失函数层
损失函数层(loss layer)用于决定训练过程如何来“惩罚”网络的预测结果和真实结果之间的差异,它通常是网络的最后一层。本文使用Softmax交叉熵损失函数,被用于在10个类别中选出一个。
Softmax函数为 ,其中ai为第i个输入,T为输入总数,Si为第i个输入的概率。交叉熵损失函数为
,其中ai为第i个输入,T为输入总数,Si为第i个输入的概率。交叉熵损失函数为![]() ,yi是概率分布,Si预测概率。其中c越小预测越准确。
,yi是概率分布,Si预测概率。其中c越小预测越准确。
2. LeNet-5模型[4]
Yann Lecun等人所提出的LeNet-5卷积神经网络模型如下所示:
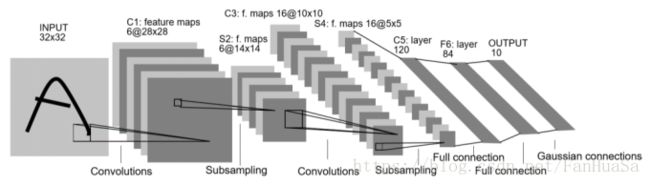
图2.1.1 LeNet-5模型
C1层为带6个5*5卷积核的卷积层,由于输入层为32*32的单层图像,故该层运算后将得到6个28*28的特征图。S2层为2*2的这下采样层,使用2*2最大池化进行下采样得到14*14的像素图。C3使用16组、每组6个5*5的卷积核进行特征提取,每组6个卷积核对S2层结果操作并求和的到一张5*5的特征图。S4为2*2最大池化层。C5与C3相似,使用120*16个5*5卷积核进行操作。F6为全连接层,最后输出预测结果。
3. 本文模型
本文构建了带有归一化层的多层卷积神经网络模型。该模型是一个由交替卷积和非线性组成的多层体系结构,最后使用多层全连接网络与softmax分类器连接。模型遵循Alex Krizhevsky所描述的架构, 在前几层中有一些差异。[5]模型使用交叉熵损失函数对预测结果进行评价并在训练过程中使用Adma优化算法代替传统的梯度下降算法,使得算法收敛速度得以加快。其模型结构如图所示:
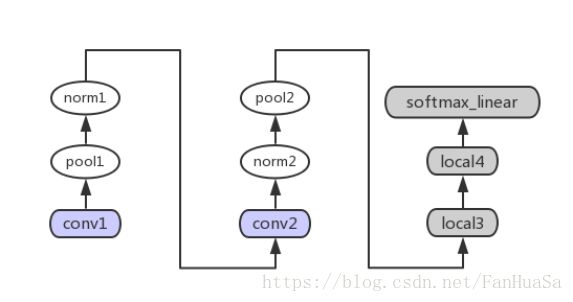
图3.1.1 模型结构
每层对应功能如下表所示:
表3.1.1 每层功能
conv1 |
卷积和线性整流 |
pool1 |
最大池化 |
norm1 |
局部响应归一化 |
conv2 |
卷积和线性整流 |
pool2 |
最大池化 |
norm2 |
局部响应归一化 |
local3 |
带线性整流的全连接层 |
local4 |
带线性整流的全连接层 |
softmax_linear |
使用线性转换产生logits |
4. CIFAR-10数据集
4.1. Cifar-10概况
Cifar-10是由Hinton的两个学生Alex Krizhevsky、Ilya Sutskever收集的一个用于普适物体识别的数据集。Cifar是加拿大政府牵头投资的一个先进科学项目研究所。Hinton、Bengio和他的学生在2004年拿到了Cifar投资的少量资金,建立了神经计算和自适应感知项目。这个项目结集了不少计算机科学家、生物学家、电气工程师、神经科学家、物理学家、心理学家,加速推动了Deep Learning的进程。从这个阵容来看,DL已经和ML系的数据挖掘分的很远了。Deep Learning强调的是自适应感知和人工智能,是计算机与神经科学交叉;Data Mining强调的是高速、大数据、统计数学分析,是计算机和数学的交叉。
Cifar-10由60000张32*32的RGB彩色图片构成,共10个分类。50000张训练,10000张测试(交叉验证)。这个数据集最大的特点在于将识别迁移到了普适物体,而且应用于多分类(姊妹数据集Cifar-100达到100类,ILSVRC比赛则是1000类)。

图4.1.1 部分Cifar-10数据集
可以看到,同已经成熟的人脸识别相比,普适物体识别挑战巨大,数据中含有大量特征、噪声,识别物体比例不一。因而,Cifar-10相对于传统图像识别数据集是相当有挑战的。[6]
4.2. Cifar-10数据集数据结构
Cifar-10提供了多种开发平台下的数据集,本文使用其提供的二进制文件数据集,大约175MB。其中有6个子文件,每个文件大小约为29.3MB,含有10000条图片像素信息和其所对应的标签,其数据结构如表3.2.1所示。
表4.2.1 Cifar-10二进制数据集数据结构
1字节标签 |
1024字节红色像素点 |
1024字节绿色像素点 |
1024字节蓝色像素点 |
…… |
…… |
…… |
…… |
1字节标签 |
1024字节红色像素点 |
1024字节绿色像素点 |
1024字节蓝色像素点 |
本文使用其中5个文件作为训练数据集、1个文件作为测试数据集,每次训练时选取100条数据进行批处理。其中每个颜色空间像素按行排列,即前32字节为图片第一行,最后32自己为图片最后一行。
5. 模型结果
本文使用TensorFlow官方教程中提供的对Cifar-10二进制文件的读取脚本cifar10_input.py文件对数据集进行读取,使用TensorFlow提供的框架对CNN模型进行运算节点构建和数据流向的规划。
其中训练数据50000条,测试数据10000条,在训练和测试中均每次读取100条数据进行批处理。在每10次迭代时记录迭代次数和损失函数值,得到了不同迭代次数下迭代次数和损失函数值之间的关系图,如图5.1.1所示:

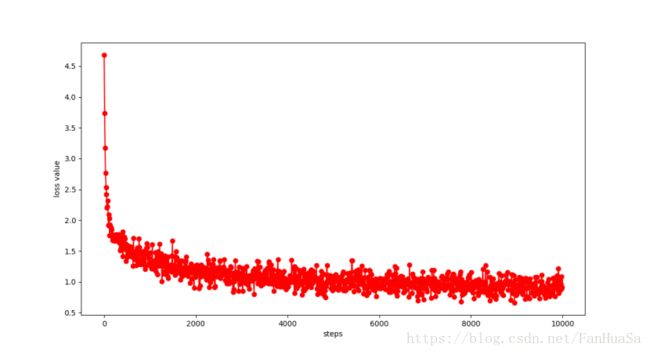
图5.1.1 迭代次数与损失函数值关系图
第一幅图为1000次迭代的情况,第二幅图迭代次数为10000次。可以看出损失函数值整体呈收敛趋势,在前期1000次迭代中收敛极快,后期趋于稳定,故迭代步数的增加在后期对该网络整体性能提升的影响会逐渐减弱。为进一步说明问题,本文选取一些特定的迭代步数训练并绘制需测准确率图,如图所示:
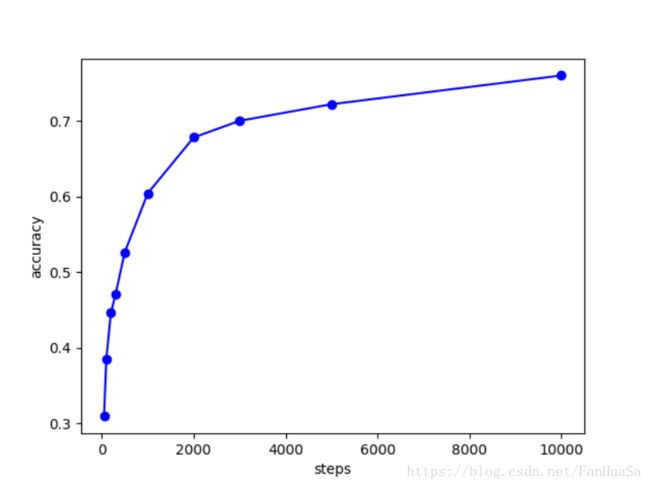
图5.1.2 准确率与部分迭代步数关系
结合损失函数图可以得出,该模型对迭代步数的敏感性主要集中在前期少量迭代次数中。这是由网络权重优化过程中在接近最优解时出现的收敛速度变慢的情况所导致的,若要改变这一情况,需提出一种新的优化算法,其优化效果不随时间呈指数下降。
由于迭代次数与模型训练时间呈正相关,而预测效果并非与迭代次数线性相关,故在时间要求比较高的情况下可选取适当的迭代次数进行训练。当然,在时间要求不严格时,应尽量选择大规模的训练方式。
6. 参考
[1]. Convolutional Neural Networks (LeNet) - DeepLearning 0.1 documentation. DeepLearning 0.1. LISA Lab. [31 August 2013].
[2]. Convolutional Neural Network. [2014-09-16].PROC of the IEEE.[November 1998].
[3]. https://en.wikipedia.org/wiki/CNN.
[4]. Yann Lecun.Gradient-Based Learning Applied to Document Recognition.
[5]. https://www.tensorflow.org/tutorials/deep_cnn.
[6]. https://blog.csdn.net/zeuseign/article/details/72773342.