机器学习算法
机器学习算法
1:线性回归的解释
线性回归是最简单的机器学习算法之一,但是非常常用。我们都知道给定(x,y)作为训练数据,使用如下的目标函数进行优化:
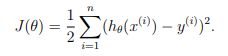
然后使用优化方法,比如说梯度下降算法(或者牛顿法等)对上面的目标进行优化:
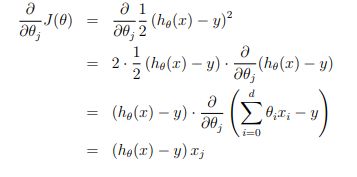
![]()
但是为什么直接使用平方差作为损失函数能够进行先行回归?下面的解释来自与Andrew Ng的机器学习课程:

假设回归结果与真实值之间的误差满足正太分布(为什么满足正态分布,因为根据中心极限定理可知,任意多的随机变量的和满足正太分布),因此,可以得到下面的公式:
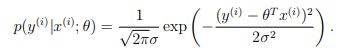
然后使用最大似然函数可以得到下面的结果:
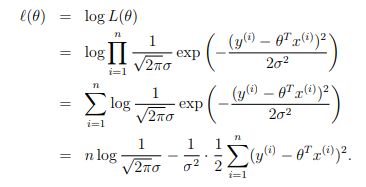
和KL散度与交叉熵的关系一样,从上面的式子可以得到,最大化似然函数等价于最小化平方差。但是为什么使用最大似然能够作为目标函数呢?从最上面的误差满足正态分布来说,我们希望误差尽可能的小,误差越小的话,对应的概率越大,因此最大化似然带来的结果就是误差最下。
很多人认为伯努利分布或者sofamax分布的负对数似然表示交叉熵,但是实际上,任意一个负对数似然组成的损失都是在训练集上经验分布和定义在模型上概率分布之间的交叉熵,比如说上面的均方误差实际上就是经验分布和高斯分布之间的交叉熵。最大似然估计被证明,当样本数目m区域无穷大的时候,最大似然估计就收敛率而言是最好的渐进估计(偏差趋于0),因此实际上好多损失函数都是通过最大似然推导而来的。
2:超参数优化方法
1)交叉验证
交叉验证可以帮助我们手动的选择超参数。https://scikit-learn.org/stable/modules/cross_validation.html#cross-validation介绍了交叉验证的一些算法,以及在scikit-learn中的实现。
2)网格搜索(grid search)
网格搜索就是将所有的超参数的组合进行验证,使用交叉验证的方法,看验证集上面的效果怎么样,然后选择效果最好的超参数组合最为最终的结果。https://scikit-learn.org/stable/modules/grid_search.html介绍了scikit-learn里面实现的网格搜索算法。
https://scikit-learn.org/stable/auto_examples/model_selection/plot_randomized_search.html#sphx-glr-auto-examples-model-selection-plot-randomized-search-py对比了传统网格搜索和随机搜索的性能差异。
3)贝叶斯优化
https://arxiv.org/pdf/1012.2599.pdf
http://krasserm.github.io/2018/03/21/bayesian-optimization/
3:推荐系统
推荐算法在各种平台上面都能看见,头条的推荐,腾讯的用户推荐等等,Netflix在推荐系统的构建上面比较领先,下面介绍几种常用的推荐系统算法:
1)SVD分解
下面的矩阵是一个常见的用户-商品打分矩阵,?代表值的缺失。

使用SVD进行分解之后,可以得到下面的形式:
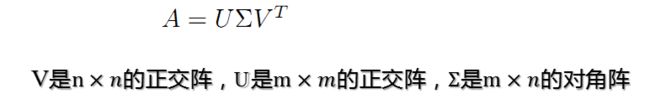
其中A代表需要被分解的矩阵。我们可以将右边被分解出来的三项进行合并,将前两项的矩阵乘积当做一项,因此可以写成A=XY'的形式。得到下面的形式:

实际上这样就是一个矩阵分解问题,很多问题都可以看成一个矩阵分解问题,推荐系统,超光谱分解等等。SVD推荐算法的出发点就是找到两个矩阵你P(用户矩阵),Q(商品矩阵),使得他们的乘积尽可能的符合打分矩阵R :
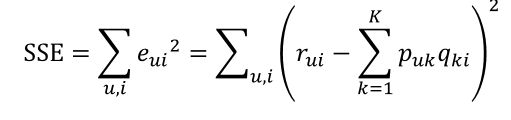
def sgd(data_matrix, user, item, alpha, lam, iter_num):
for j in range(iter_num):
for u in range(data_matrix.shape[0]):
for i in range(data_matrix.shape[1]):
if data_matrix[u][i] != 0:
e_ui = data_matrix[u][i] - sum(user[u,:] * item[i,:])
user[u,:] += alpha * (e_ui * item[i,:] - lam * user[u,:])
item[i,:] += alpha * (e_ui * user[u,:] - lam * item[i,:])
return user, item上面是最简单的目标函数,比较具体的介绍可以查看 参考文献第一篇。那么上面的基于矩阵分解的算法是没有用到SVD的,那么SVD什么时候被用到算法里面了呢?答案是,SVD在上面的推荐算法里面不会直接使用SVD分解,而是直接使用矩阵分解的思想,通过梯度下降算法优化目标函数(一般只使用存在打分的项,然后加入一些正则化项防止过拟合),surprise提供了SVD在推荐系统的一个实现,P,Q矩阵都是使用正太分布初始化,然后使用梯度下降进行优化的,详情可以查看https://surprise.readthedocs.io/en/stable/matrix_factorization.html#surprise.prediction_algorithms.matrix_factorization.SVD
因为一般打分矩阵是稀疏的,因此不能直接使用SVD分解,需要进行一些预处理,比如说缺失值填充等等,使用SVD分解同样可以得到上面的P,Q矩阵,然后被用到协同过滤算法里面,当做每个商品和用户的特征。
参考:
https://blog.csdn.net/zhongkejingwang/article/details/43083603
https://www.cnblogs.com/bjwu/p/9358777.html(*)
https://surprise.readthedocs.io/en/stable/matrix_factorization.html#surprise.prediction_algorithms.matrix_factorization.SVD
https://datajobs.com/data-science-repo/Recommender-Systems-[Netflix].pdf
2)RBM
SVD和RBM(受限制玻尔兹曼机)都是Netflix采用过的推荐算法。RBM是一个基于能量的算法,目的是使得从隐藏层重构回来的可见层数据能够和可见层数据的差异尽可能的小,实际上就是autoencoder的思想。但是RBM使用的是MLE(最大似然估计)作为目标,使用梯度下降来对参数进行优化的。
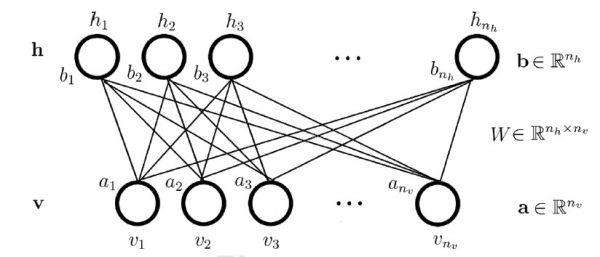
RBM之所以区别于BM的原因是隐藏层和课件层内部不存在连接,详情可查看https://www.cnblogs.com/pinard/p/6530523.html ,将RBM应用于推荐,可见层就是一个用户对所有商品的打分,需要进行如下的变种:
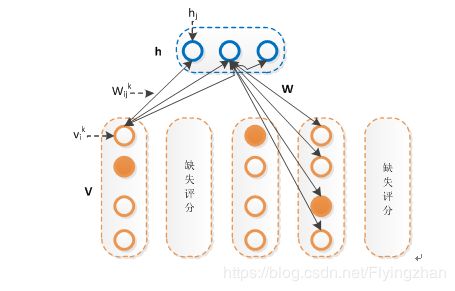
改进主要集中于可见层的输入,每个节点从二维的变为了一个k维的输入,如果对某些商品没有打分的话,节点的输入就都为0,相当于没有连接 ,使用最大似然作为目标函数进行优化。当训练好一个模型之后,我们输入一个用户的打分情况,会返回一个k维的实数向量,选择最大值,或者sofamax之后选择概率最大的一项,作为该商品的打分。对隐藏单元的先验概率的不同预测,存在伯努利RBM(下图2)和高斯RBM(下图1):
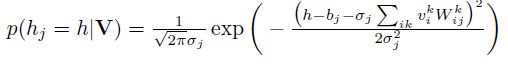
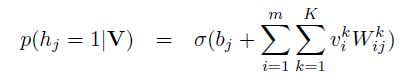
下面是RBM的python实现代码(转自https://zhuanlan.zhihu.com/p/23970608):
# coding:utf-8
import time
import numpy as np
import pandas as pd
class BRBM(object):
def __init__(self, n_visible, n_hiddens=2, learning_rate=0.1, batch_size=10, n_iter=300):
self.n_hiddens = n_hiddens
self.learning_rate = learning_rate
self.batch_size = batch_size
self.n_iter = n_iter
self.components_ = np.asarray(np.random.normal(0, 0.01, (n_hiddens, n_visible)), order='fortran')
self.intercept_hidden_ = np.zeros(n_hiddens, )
self.intercept_visible_ = np.zeros(n_visible, )
self.h_samples_ = np.zeros((batch_size, n_hiddens))
def transform(self, x):
h = self._mean_hiddens(x)
return h
def reconstruct(self, x):
h = self._mean_hiddens(x)
v = self._mean_visible(h)
return v
def gibbs(self, v):
h_ = self._sample_hiddens(v)
v_ = self._sample_visibles(h_)
return v_
def fit(self, x):
n_samples = x.shape[0]
n_batches = int(np.ceil(float(n_samples) / self.batch_size))
batch_slices = list(self._slices(n_batches * self.batch_size, n_batches, n_samples))
for iteration in xrange(self.n_iter):
for batch_slice in batch_slices:
self._fit(x[batch_slice])
return self
def _sigmoid(self, x):
return 1.0 / (1.0 + np.exp(-x))
def _mean_hiddens(self, v):
p = np.dot(v, self.components_.T)
p += self.intercept_hidden_
return self._sigmoid(p)
def _mean_visible(self, h):
p = np.dot(h, self.components_)
p += self.intercept_visible_
return self._sigmoid(p)
def _sample_hiddens(self, v):
p = self._mean_hiddens(v)
return np.random.random_sample(size=p.shape) < p
def _sample_visibles(self, h):
p = self._mean_visible(h)
return np.random.random_sample(size=p.shape) < p
def _free_energy(self, v):
return (- np.dot(v, self.intercept_visible_)
- np.logaddexp(0, np.dot(v, self.components_.T)
+ self.intercept_hidden_).sum(axis=1))
def _fit(self, v_pos):
h_pos = self._mean_hiddens(v_pos)
v_neg = self._sample_visibles(self.h_samples_)
h_neg = self._mean_hiddens(v_neg)
lr = float(self.learning_rate) / v_pos.shape[0]
update = np.dot(v_pos.T, h_pos).T
update -= np.dot(h_neg.T, v_neg)
self.components_ += lr * update
self.intercept_hidden_ += lr * (h_pos.sum(axis=0) - h_neg.sum(axis=0))
self.intercept_visible_ += lr * (np.asarray(v_pos.sum(axis=0)).squeeze() - v_neg.sum(axis=0))
h_neg[np.random.uniform(size=h_neg.shape) < h_neg] = 1.0 # sample binomial
self.h_samples_ = np.floor(h_neg, h_neg)
def _slices(self, n, n_packs, n_samples=None):
start = 0
for pack_num in range(n_packs):
this_n = n // n_packs
if pack_num < n % n_packs:
this_n += 1
if this_n > 0:
end = start + this_n
if n_samples is not None:
end = min(n_samples, end)
yield slice(start, end, None)
start = end参考:
https://github.com/meownoid/tensorfow-rbm(tensorflow构建rbm作为一个特征学习模型)
https://blog.csdn.net/u013414741/article/details/47151059
https://www.cnblogs.com/pinard/p/6530523.html
https://zhuanlan.zhihu.com/p/40120848
3)协同过滤算法
协同过滤算法是最早的推荐算法之一,分为基于用户和基于商品的协同过滤,主要是根据用户或者商品的相似度,对未知的商品得到一个打分的算法,可以查看https://blog.csdn.net/yimingsilence/article/details/54934302。
4:svd分解
奇异值分解是一个有着很明显的物理意义的一种方法,它可以将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性。对于奇异值,它跟我们特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵。
特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一组特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。 当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。也就是之前说的:提取这个矩阵最重要的特征。
PCA的实现一般有两种,一种是用特征值分解去实现的,一种是用奇异值分解去实现的。SVD一般用于降维,生成一个矩阵减少计算量(比如说在PCA中使用SVD的一些trick可以避免求协方差矩阵)。
参考:
https://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
https://www.cnblogs.com/pinard/p/6251584.html
5:lstm
由于最近有点忙,暂时没有时间整理LSTM,下面的文章很好。
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
https://towardsdatascience.com/recurrent-neural-networks-by-example-in-python-ffd204f99470
6:bagging
As they provide a way to reduce overfitting, bagging methods work best with strong and complex models (e.g., fully developed decision trees), in contrast with boosting methods which usually work best with weak models (e.g., shallow decision trees).
https://scikit-learn.org/stable/modules/ensemble.html#gradient-boosting
https://zh.wikipedia.org/wiki/AdaBoost
随机森林:
https://blog.csdn.net/cg896406166/article/details/83796557
https://blog.csdn.net/bbbeoy/article/details/73548448
https://blog.csdn.net/zjuPeco/article/details/77371645
回归树:
https://blog.csdn.net/weixin_36586536/article/details/80468426
Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。
对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差(variance) ,因为采用了相互独立的基分类器多了以后,h的值自然就会靠近.所以对于每个基分类器来说,目标就是如何降低这个偏差(bias),所以我们会采用深度很深甚至不剪枝的决策树。
对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
从传统机器学习模型向深度学习模型的转变,不是一种潮流,是一次次优化改进后累积的结果
早期的机器学习主要精力花费在特征工程上,转移到深度学习后,特征组合的计算交给神经网络隐层来处理