销售预测该怎么做?
产销协调计划(Sales&OperationsPlaning),是供应链的优化的核心,现在大多数企业采用的是S&OP概念创始人OliverWight提出的执行模式以及其升级模式——IBP(IntegratedBusiness Planning),该模式核心在于将需求和供应分别计划然后统一协调,基于需求预测,需求计划与供应计划进行协调指导采购、备料与生产。
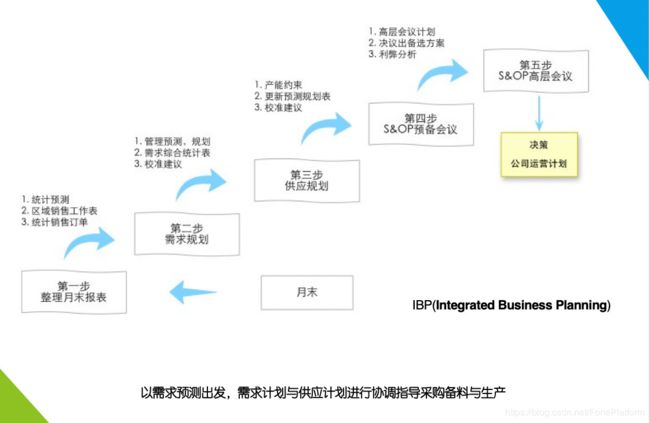
按照传统计划模式,企业通过五个步骤来解决销售的需求供应之间的关系,在S&OP标准的解决方案里面分为五个步骤,即企业的供应链生产部门他一个月会开5次会议来解决产销问题。
- 第一步,了解历史数据,整理细化销售数据,到品类的、到区域的、到经销商的、到终端的、到pos的;
- 第二步,做需求计划,基于历史数据做预测,预测到底未来的一段时间,会收到什么样的需求;
- 第三步,后台要求,如何供应,如何匹配;
- 第四步,S&OP的预备会议,进行方案设计;
- 第五步,高层会议,做出决策。
一般情况下,现在的国内外企业,是按照这个标准模式去执行我们的产销协调,绝大部分的IBP系统解决工具,也是基于这五步来进行产销协调的。遭遇的问题也是明显的:过分依赖预测准确性、变化越来越快越来越大的市场情况下实际的需求永远是波动的,背后生产模式与市场反馈的对接效率、管理能力都存在很多问题。
销售预测的重要性
从数据角度来看,从需求预测到原材料供应的产销协调的数据逻辑基本分为5个步骤。
- 第一,收集长周期的销售数据。至少会收集5到6个月的数据,并且从不同角度:渠道、品类、SKU、数量、金额以及缺货数量。尤其缺货量,这一点很重要,很多企业的销售人员先看库存,在跟客户协调的过程当中会隐没客户的真实需求,比如,客户的实际需求是想买A买5000,销售告诉客户的是我只能卖给你B卖3000,这些信息对未来供应链计划就会有影响。
- 第二,销售预测。掌握历史数据后,按照总量、渠道、品类、SKU去预测。在预测的过程当中有一些技术性的处理,比如要考虑外部因素,像是促销、节日,甚至是竞争对手的促销,外部事件对销售本身预测的准确度有非常大的影响。销售预测的重要之处在于,它是外部实际需求和背后产能之间的一个衔接点。
- 第三,产能平衡。必须将波动放平缓,不能让背后的供应链、生产、采购跟我们的市场需求一样波动起来,那企业就乱了套了;所以需要产能平衡,通过主计划再去核算产线能力,再去做产线上的参数调整。比如,本来我预测未来5个月的某一天,产量可能因为促销激增,那就要产能平衡到提前4个月或3个月的时间来生产,平衡到前面的几个月分别去生产。
- 第四,MRP备料计划。一般在这环节,企业都有专业的系统。
- 第五,排产计划。
数据在整个供应链的管理逻辑当中起到非常重要的作用,它并不是一个IT系统,也不是一个流程或者制度,它就是一个数据逻辑串起来的一条链。

销售预测准确率提升的重要意义不言而喻:能够实现库存成本降低、资金成本降低、采购成本降低、物流成本降低、生产效率提升、订单交付率提升等,最终实现企业利润的提升。
导致销售预测不准的原因
销售预测不准几乎是所有企业都面临的问题,我们总结出来主要有以下原因:
- 数据质量差,没有统一上报途径,销售数据反馈滞后。
- 电商、直销等渠道分散,活动敏感性强,无法预测。
- 产品生命周期短(尤其在快消产品越来越短),没有可参考的历史数据。
- 没有科学模型支持预测。用上月销量指导下月销量的“天真预测”可能适用一些产品,但大部分是不适用的。
- 预测结果评价方法单一,无法支持模型优化。
- 市场变化快,预测频率低,无法根据市场变化快速调整。之前说过现行S&OP模式的流程走完基本需要一个月,如果发生明显变化,做排产更新是来不及的。
大部分企业又采用了以产定销的模式,导致可能A缺货、B高库存的问题。产销协调计划事实上是围绕仓库来进行的,通过动态安全库存方式来解决前后端协调问题:销售变化是波动的,生产是平的,库存是服务与市场可能出现的变化的。
数据逻辑下的产销协调什么样
我们说明了为什么S&OP并不适用于现在的生产销售,那么到底我们的产销协调计划的模式应该遵循可执行原则,具体来说,有四个原则:
- 第一,一个计划。一个计划供应链的整个生产计划由一个部门或者由一个计划来指挥,核心总体不变,形成部门协调。
- 第二,高频率。提高计划与预测频率,把月计划打破成为周计划,把月预测打破成为周预测,甚至是天预测;
- 第三,需求驱动。以实际市场需求作为驱动,以销定产;
- 第四,品类差异化、策略模型化。不同类别品种采取不同的供应链策略,各种策略要通过业务模型实现决策优化。
因此,供应链优化的模式应该是这样的:长周期滚动预测指导备料,短周期动态安全库存指导生产。
滚动多周计划。按照周计划去做需求预测,但不用于工厂排产,而是根据业绩目标、实际销售,做滚动多周的需求预测指导备料,一般是滚动26周(半年)来做产能的平衡;高峰期的需求放到低谷期实现,用来指导MRP和原材料采购。
滚动多日计划。滚动多周计划针对长周期概念,短周期则要滚动多日,将每天需求同步给供应商,按照不同sku设定动态的安全库存,以动态安全库存MinMax作为生产信号。
在实际的执行环节当中,其实每一个链条都是用数据来串起来的。预测是通过预测模型,生产计划的平衡也是通过一个数据模型,通过MRP系统等等。
最终形成基于逻辑数据的产销协调计划与预测原则:
- 对产品进行ABC分类,不同类别采用不同策略;
- 做滚动多周需求预测;
- 基于滚动多周预测,进行逻辑安全库存控制,产能平衡,形成长周期主生产计划,MRP分解后向供应商输出滚动多周物料需求计划;
- 对成品仓库进行动态库存控制,每周更新库存控制参数;
- 基于动态库存控制参数,编制滚动多日主生产计划。
破除预测的管理难题
预测不准的问题如何解决,在管理上已经有很多可以做的。
- 提高预测频率。刚刚已经详细论述过。
- 减少预测层次,只在总部高频率预测。
- 弱化预测准确率,承担业绩的人不预测。比如,销售参与到预测中,往往会保险起见,让工厂多备料。
- 只对可预测的做预测。确实有些无法预测的产品,比如特殊渠道等。
从实践来看,业内全品类产品,能够在月计划做到预测准确率85%以上,日预测能够达到30%到50%,就已经非常不错了,销售预测的结果只是一个中目标,你没有办法把它拿来直接应用。
对于不能做预测的产品怎么办?如果说订单的交期较长,那就只能按单生产;如果说订单的交期较短,那就按单装配,我们备原材料;如果说按单交期更短,为了满足这部分客户的利益,就只能够备库存,产销协调计划没有完美的解决方案,只能有合适的解决方案,不能做的,要用其他的策略来替代。
结合业务实际,利用科学模型
销售预测是数据驱动的,也是一整个业务流程,在充分了解产品的模式和整个业务逻辑之后,才能够做出相对比较完美的销售预测的模型和结果。
所以,在做预测之前,先要做业务调研、定制模型、做小规模的数据验证,调整逻辑后正式应用。整个过程要遵循三个要点:
第一,基于科学方法结合业务实际,定制有效的预测模型。
每一个产品它的波动曲线是不一样的,所适应的统计学模型是不一样的,所以一定要从最小颗粒度(SKU)进行多模型的数据匹配。现在我们和F-One的实践模式当中有总结出来,有6到8种适合于不同数据曲线波动的情况下的可能适用模型。在每一次预测的过程当中都通过不同的模型去试算一下,最终通过科学的评价方法,系统自动的折出一种最优的模型作为未来我们可以使用的预测模型。
第二,引入外部影响因素,事件因子锁定销量峰谷。
所有的统计模型都是实验室诞生的,实验室数据就是理想状况的数据。实际业务当中往往没有这种理想状况的数据,但是一旦发生这种理想状况的数据这些模型就很适用。往往存在的问题是有很大量的波峰波谷,这些波峰波谷要找出背后的影响因子,以事件的形式,比如说节假日,促销活动,竞争对手的促销活动等,去除这些有可能存在的波动。
第三,降低偶然事件或异常数据的影响。
销售预测都是基于历史数据来做,历史数据当中有很多杂音,比如说去年发生了某一些事件,今年不会发生明年也不会发生,我们在预测的时候就要把这些事件的影响给它去除。
所以,首先要按照正常的理想的状况的数据去预测,再把去年某个事件因子的影响量给添加到今年可能出现的对应的时间点。
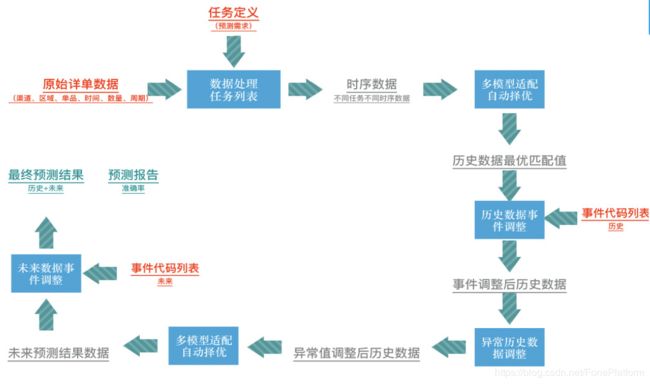
我们的咨询和F-One产品的结合就是基于这样的一个基本逻辑。所以业务人员操作的过程中其实很简单,只要把事件的名称、影响周期、影响品种列表植入,系统就会自动的去识别这个影响因子的影响量,去算到未来的这个预测当中。一般是提取底层的ERP的系统去提取原始的详单数据,然后定一些任务,把这个任务通过多模型适配自动择优,择优之后把一些外部的事件列表给导入进去。系统就会自动的根据这些事件列表去把这些因子给计算出来放到我们今年已经预测好的结果当中,然后再调整一些前面已经发生,但是未来不可能发生这些异常了数据,再去做一些模型的优化,最后输出结果。
建立多维预测评价,实现模型自动优化
预测模型的到底是否真的适用,应该用相应的指标进行检验。
- 预测有效性。首先结果一定是相对准确的,并且要考虑在相对短的时间内,是不是SKU还没有呈现规律,需要进行模型显著性检验。
- 预测偏差。企业的计算方法不尽相同,比如Mape(平均绝对误差率)、Mad(平均绝对误差)等等,选择从不同维度做测评,因为每一个评价方法都代表了一个优化方向。
- 预测效率评价。需要数据的高质量、模型的高自动化程度与并行处理能力。
根据业务数据状况,通过试验后选择最适合的模型组合,每一次预测运行,系统自动从三个角度为每一个SKU选择最优模型组合进行匹配。
产销协调需要什么样的系统
我们回归到产销协调的基本逻辑——以需求驱动到产能平衡,链条上的每一个节点都会有特殊的业务场景,需要数据流的方式进行串联,数据流每一个节点上都有经过业务验证之后的逻辑和统计模型。
• 流程管理需求。供应链的上以数据是要给下一级数据使用的。
• 数据分析支持需求;
• 多场景支持需求;
• 定制建模需求;
• 灵活性、可拓展需求;
• 多级用户(终端使用者,逻辑和模型修改者)。
这样,企业的业务人员了解自己的业务逻辑之后,随着时间的变化,可以自动去修改当中的数据逻辑与统计模型。
传统的做法大概有这样三种:
第一,每一个节点都用Excel,通过人工方式去传递,无法高频率地去调整生产计划和需求预测,不满足市场高速变化的需求。
第二,定制软件,一般情况下定制一整套这样的一个逻辑的软件,成本和时间非常大,而且复杂程度非常高,灵活性很差,定制好了之后基本上三年五年是不敢动的,常常会出现模块和Excel结合的状况。
第三,完全产品化的模块结合。
在我所协作的这个项目,我把F-One定位成这样的一个平台——能够支持多个业务场景,而且业务场景之间可以有数据流的关联性,通过流程的方式串联起来。比如,刚才讲的这个产销协调计划这个模式当中的节点,销售预测、动态安全库存、MRP之间都是可以通过业务逻辑的梳理之后,定制模型和逻辑写入到每一个场景模块里面的,F-One平台支持数据流的方式,让这些数据能够流转起来成为一个链条。
我们不仅在实践的过程当中验证了F-One对于产销协调的适用性,有一些企业的数据分析人员同时具有业务逻辑的能力的话,在项目离开之后,也创造了一些新功能写入到系统。因为F-One同时支持二次开发的能力。