数据挖掘---频繁项集挖掘Apriori算法的C++实现
1 准备
首先实现这个算法是基于中南大学软件学院数据挖掘课的上机作业。作业(全英文)下载地址:http://download.csdn.net/detail/freeape/9188451
2 作业粗糙翻译内容
2.1 前言
- 编程作业可能比书面作业花费更多的时间,而这也算是你最后成绩的10%,所以请提前开始;
- 这是个人作业,你可以与你的同学或者老师交流,但是不能够共享代码和抄袭;
- 类似的库或频繁模式挖掘算法的程序,可以在网上找到,但你不允许直接使用这些资源,这意味着你可以不包括公共图书馆,或者修改现有的方案;
- 你可以使用Java、C++和Python编程语言;
- 你将会使用UNIX内核包操作系统下工作。它在Linux和MacOS系统上效果很好。如果你是一个Windows用户,你需要:
- 连接到一个EWS实验室机器或找到其他包具有相同的功能;
- 请你写一个关于作业报告,所以要注意有“问题和思考”的地方;
2.2 目标
- 探索频繁模式挖掘如何应用到文本挖掘中,来发现一些有意思的词语;
- 在这个作业中,你首先将在文集上运行LDA(文档主题生成模型),这个文集来自5个领域的会议论文。基于LDA的结果,一个主题(代表一个特定的域)被分配给每个标题每个单词。然后,你经常从每个主题中写一个频繁的挖掘算法来获取有意义的短语。频繁挖掘模式可能不一定是这个主体中有意义的词语。所以你会考虑如何从所有的频繁模式中提取出有意义的词语。最终的目标是为每个主题输出高代表性的短语。
2.3 第一步:认识数据
我们从5个领域的计算机科学会议,收集论文标题:Data Mining(DM), Machine Learning(ML), Database(DB),Information Retrieval(IR,信息检索)和Theory(TH)。你可以从链接中下载raw格式数据paper_raw.txt(作业已经给了,请注意:在这次作业中,我们不会直接使用这个文件,但是你可以自行查看这个文件里的内容,它里面最原始的标题是什么样的)。每一行包含两栏,每篇论文的PaperID和Title,然后用制表符('\t')分隔开来。回忆课堂上的所讲的例子,对于文件中的每一行,你可以把它视为一个实例。在标题的每个单词是等同于在一个实例中的子项。需要注意的地方就是PaperID在整个数据集中是唯一的,所提供的文件是所有数据集中的一个子集而已,有可能PaperID是不为0,也有可能不是连续的。原始数据格式如下:
在这个作业中,数据预处理过程中去除了停用词(如一些功能词:the、is、as、which等),只留下词语和词干。你可以在这里下载数据处理后的文件paper.txt,这是我们将使用的实际数据集。在这个文件中,每行是以一个PaperId,然后紧跟一些项,格式是:
PaperID '\t' term_1 ' ' term_2 ' ' ......
paper.txt文件内容部分如下:
2.4 第二步:数据预处理(20points)
这一步准备输入LDA。你将生成基于paper.txt的两个文件。
2.4.1 生成一个目录(10points)
首先你需要从paper.txt中产生一个词汇,并命名存放词汇文件名为vocab.txt。在这个文件中的每一行是一个从paper.txt提取出来的独立的词语,每个词应出现一次,下面是vocal.txt的前五行,需要注意的是,词语的顺序可以不同:
automatic
acquisition
proof
method
philosophical
...2.4.2 以字典形式标记文本(10points)
在这一步,要求将paper.txt文件中的每个标题转换成如下格式:
[M] [term_1]:[count] [term_2]:[count] ... [term_N]:[count]
其中,[M]是每行的中的每个标题中的独一无二的词语的个数(如PaperID=7600,M=4)。[count]是指每个标题中的每个独一无二的词语出现的频率(如PaperID=7600,[term_1]:[count]=1)。以PaperID=7600为例,会产生如下的数据格式:
"4 0:1 1:1 2:1 3:1"
注意,[term_i]是一个整数,是索引在vocab.txt一个的某个词语;下标从0开始。最后命名输出文件title.txt,将格式化的数据保存到这个文件中。
注:如果你使用任何其他的LDA包,而不是在接下来的一步中提到的,请确保你的数据格式能够匹配你所使用的LDA包的需求。
2.5 第三步:分区(10points)
回想我们在计算机科学中的五个领域收集的论文标题,如果在纸上直接运行频繁模式挖掘算法,模式将会是独立的主题。因此,我们想要挖掘频繁模式中的每个领域,标题和词语也应该被划分为五个领域。请注意,每个领域的的知识你是不知道的。相反的,我们应用的主题模型,将自动地去发现隐藏在标题和词语后面的主题。具体来说,我们应用LDA(你不必理解主题模型具体是怎么工作的)来为每个词语指定一个主题。
2.5.1 为每个词语(Term)指定一个主题(Topic)(5points)
- 下载LDA包包。解压后你可以看到源代码列表。你可以参考这一页,它对这个包进行了全面的介绍。
- 打开一个终端,进入源代码的目录,
make,生成一个可执行的LDA文件。 - 在
lda-c-dist目录下,有一个settings.txt文件,你可以使用下面的设置,如果你对LDA怎么工作的很清楚,可以自己调整相关参数。
var max iter 20
var convergence 1e-6
em max iter 100
em convergence 1e-4
alpha estimate- 用下面的命令运行LDA
<DIR>/lda-d-dist/lda est 0.001 5 <DIR>/lda-d-dist/settings.txt <DIR>/title.txt random <DIR>/result 0.001是给LDA主题的比率(这只是一个参数,如果你不是很了解,你不是必须改变它);5,代表5个主题;title.txt是在第二步产生的文件,输出的内容将被放到result文件夹中。DIR,是你当前的工作目录。
- 检查你的输出
- 在result目录中,打开word-assignments.dat文件,每一行的格式为:
[M] [term_1]:[topic] [term_2]:[topic] ... [term_N]:[topic]
[M]是每行的中的每个标题中的独一无二的词语的个数(如PaperID=7600,M=4)。与每个词语相关联的[topic]是分配给它的主题。topic下标是从0开始的,如某一行可以是:004 0000:02 0003:02 0001:02 0002:02;这意味着在这个标题中所有的词语都被分配给第三个主题(即topic 02)。注意,你不限于使用这个包,这里还有另外一个选择:http://mallet.cs.umass.edu/topics.php。
2.5.2 重新组织主题(5points)
要求重新组织五个主题的词语。对于第i个主题,要求创建一个文件名为topic-i.txt的文件。通过分配给词语的主题,分离在word-assignment.dat文件中的每一行。例如,在word-assignment.dat文件中的每一行可以被认为是以下格式(注意:在这里用实际的词语替换整数是为了更好地说明):
004 automatic:02 acquisition:02 proof:02 method:02
005 classification:03 noun:02 phrase:03 concept:01 individual:03然后输出文件应该是:
topic-0.txt
...
topic-1.txt
concept
...
topic-2.txt:
automatic acquisition proof method
noun
...
topic-3.txt
classification phrase individual
...在真正的文件中,每一个词语应该被表示为一个整数对应于第二步所产生的字典。topic-i.txt看起来像这样:
[term1] [term2]....[termN]
[term1] [term2]....[termN]
...2.6 第四步:挖掘出每个主题的频繁模式(30points)
在这一步,你需要实现一个频繁模式挖掘算法。你可以选择任何你所喜欢的频繁模式挖掘算法,比如Apriori、FP-Growth、ECLAT等。请注意,你需要在相应的5个主题的用5个文件来运行代码。运行输出格式为([s] (space) [t1 (space) t2 (space) t3 (space) …]):
#Support [frequent pattern]
#Support [frequent pattern]
... 并用频繁模式以#Support开头,从高到低进行排序,你的输出文件应该放在一个名为patterns的文件夹中。第i个文件命名为pattern-i.txt。(提示:需要你自己算出最小支持度min_sup)
思考问题A:你如何选择该任务的min_sup?解释你如何选择你的min_sup的报告,任何合理的选择都可以。
2.7 第五步:挖掘最大/闭合模式(20points)
在此步骤中,您需要实现一个算法来采掘最大频繁项集和闭项集。您可以根据步骤4的输出编写的代码,或实现特定的算法来挖掘最大频繁项集和闭项集,如CLOSET,MaxMiner等。
输出的形式应和第四步中的输出是一样的。最大频繁项集输出到max目录,第i个文件命名为max-i.txt。闭项集输出到closed目录,第i个文件命名为closed-i.txt。
思考问题B:你能找出哪些主题对应于哪个领域的基础上你所采掘出的模式?写在你的观察报告。
思考问题C:比较频繁模式,最大频繁项集和闭项集的结果,是令人满意的结果吗?写下你的分析。
最大频繁项集:就是频繁模式挖掘后的第k频繁项集
闭项集:就是指一个项集X,它的直接超集的支持度计数都不等于它本身的支持度计数。如果闭项集同时是频繁的,也就是它的支持度大于等于最小支持度阈值,那它就称为闭频繁项集。
直接超集:如最后一部分的test.txt中[BB DD],这一项的超集是[BB DD]和[AA BB DD],两个超集的支持度都为1,而[BB DD]项支持度为2,所以[BB DD]是闭项集。
2.8 第六步:按纯度排序(10points)
在http://arxiv.org/pdf/1306.0271v1.pdf这篇文章中,纯度被作为短语排名的措施之一。一个短语是纯粹的主题,如果它是唯一经常在文件(这里的文件是指标题)有关主题和不经常在文件中有关其他主题。例如,“查询处理”是数据库主题中的一个更为纯的短语。我们通过比较看到在topic-t集合D(t)中的一个短语的概率测度模式的纯度(T),看到它在任何其他topic-t集的概率(t’ = 0,1,…,k,t‘ != t)。在我们的例子中,k = 4。相比其他的任何主题,纯度本质上能够测出模式在一个主题的不同。定义如下:
purity(p,t)=log [ f(t,p) / | D(t) | ] - log (max [ ( f(t,p) + f(t',p) ) / | D(t,t') | ] )
这里,f(t,p)是模式p出现在主题t的频率,我们定义D(t)是一个文件的集合,这些文件至少有一个字被分配给主题t。D(t) = { d | 主题t被分配至少有一个字在d中。 D(t,t’) 是D(t)和D(t’)的联合。|-|测量一个set的大小。事实上,|D(t)|是在topic-i.txt的行数,但是注意 | D(t,t’) | != | D(t) | + | D(t’) |。
从步骤4获得的模式重新排列。输出形式应该是:
Purity [frequent pattern]
Purity [frequent pattern]
...通过结合支持度和纯度的方式(这里你需要提出如何结合的),频繁模式从高到低被排序了。你的输出文件应该放在一个名字为purity目录中,第i个文件命名为purity-i.txt。
2.9 第七步:加分(20points)
你能想出其他的过滤/排名标准来提高你的“挖掘”的短语列表的质量吗?执行你的算法,把你的分析放在你的报告中。
(提示:一些相关的论文描述的策略来处理这个问题,通过平衡最大模式和封闭模式。CATHY: http://www.cs.uiuc.edu/~hanj/pdf/kdd13_cwang.pdf KERT: http://arxiv.org/abs/1306.0271. )
2.10 第八步:报告(10points)
现在你准备写你的报告。你应该在报告中包含以下内容:
- 简要说明第四步~第六步你所用的算法。
- 回答所有的思考问题。
- 列出你的源文件名及其相应的步骤。
2.11 项目组织和提交
结构应该如下(<>这个括号里面是你写的代码,后面跟着“|——–”的是目录):
yourNetId_assign3|-------- title.txt
files>
topic-0.txt~topic-4.txt
files>
files>
patterns |--------pattern-0.txt~pattern-4.txt
<max/closed mining source files>
max |--------max-0.txt~max-4.txt
closed |--------closed-0.txt~closed-4.txt
files>
purity |------purity0.txt~purity-4.txt
report.pdf
注:翻译的不准勿怪!最后红色字部分及后面没翻译。
3 编程实现
在Linux系统上实现是不二选择,因为作业里面的lda可执行程序是要make编译产生的,而在windows上去make的话,会缺少一些库文件,导致出现错误。不过,我电脑上刚好有个工具链(用来开发开源无人机Pixhawk的),里面一些库是跟Linux系统上的是一样的,所以进入作业中lda-c-dist文件夹后make一下,产生了一个lda.exe可执行文件。所以我的实现都是在windows上面实现的。
仔细阅读作业要求,可知要自己编程,根据提供的paper.txt文件产生vocab.txt、title.txt这两个文件。然后用lda.exe产生word-assignments.dat文件,又需根据这个dat文件编程产生五个topic-i.txt文件。然后用apriori算法分别对这五个文件进行频繁项集挖掘。最后是完成作业中的问题与思考以及报告。
3.1 编程产生作业的文件
包括:vocab.txt、title.txt、topic-i.txt(i=0,1,2,3,4)。
//-----------------------------------------------------------------
//文 件 名:vocab.cpp
//创建日期:2015-10-15
//作 者:yicm
//功 能:由paper.txt产生vocab.txt,再由vocab.txt产生title.txt,
// 然后根据title.txt,由lda.exe产生的word-assignment.dat
// 作为输入,产生topic-i.txt五个文件
//说 明:此程序是连续处理的,word-assignment.dat是title.txt产生
// 之后再作为输入的
//修改日期:
// 2015-11-1:
//-----------------------------------------------------------------
#include ":" <" ";
}
}
out << endl;
}
out.close();
}
//-----------------------------------------------------------
//将文件中的每一行字符串作为一个元素依次存放到vector中
//-----------------------------------------------------------
void VocabProcess::store_file(ifstream& is)
{
string textline;
while(getline(is,textline))
lines_of_text.push_back(textline);
}
//-----------------------------------------------------------
//将存放每一行字符串的vector的元素依次取出,将其分解为单词,并将单词的行数保存到map< string, set >中
//-----------------------------------------------------------
void VocabProcess::build_paper_map()
{
for(line_no line_num = 0; line_num != lines_of_text.size(); ++line_num){
//绑定行字符串到istringstream
istringstream line(lines_of_text[line_num]);
string word;
//循环从行字符串读取单词到string类型word
while(line >> word){
if(!isNum(word)){
//将行号插入到键值为word,值为vector类型的map中
word_map[word].insert(line_num);
}
}
}
}
void VocabProcess::build_vocab_map(string file)
{
ifstream in;
in.close();
in.clear();
in.open(file.c_str());
string vocab;
int i = 0;
while(getline(in,vocab)){
vocab_map[vocab] = i++;
}
}
//-----------------------------------------------------------
//判断字符串是否为数字
//-----------------------------------------------------------
bool VocabProcess::isNum(string str)
{
stringstream sin(str);
int num;
char c;
if(!(sin >> num))
return false;
if (sin >> c)
return false;
return true;
}
string VocabProcess::get_vocab_of_the_line(int line_num) const
{
map<string,int>::const_iterator map_it = vocab_map.begin();
while(map_it != vocab_map.end()){
if(map_it->second == line_num){
return map_it->first;
}
++map_it;
}
return "";
}
void VocabProcess::reorganize_terms_by_topic(string datFileName)
{
char topicFile[][16] = {"topic-0.txt","topic-1.txt","topic-2.txt","topic-3.txt","topic-4.txt"};
fstream topicF[5];
for(int i = 0; i < 5; ++i){
topicF[i].open(topicFile[i],fstream::out);
}
/*读取word-assignments.dat数据,存放到vector中*/
ifstream infile;
if(!open_file(infile,datFileName)){
cerr << "open file is failed!" << endl;
return ;
}
string datline;
while(getline(infile,datline))
lines_of_dat.push_back(datline);
/*处理数据*/
string delim1 = ":";
string delim2 = " ";
for(line_no line_num = 0; line_num != lines_of_dat.size(); ++line_num){
{
vector<string> ret;
split(lines_of_dat[line_num],delim1,delim2,ret);
//cout <
int vocab_num = atoi(ret[0].c_str());
//cout << "vocab_num=" <
int topic_num = 0;
string topicLine[5] = "";
for(int i = 1; i < (2*vocab_num+1); i+=2){
topic_num = atoi(ret[i+1].c_str());
topicLine[topic_num] += get_vocab_of_the_line(atoi(ret[i].c_str())) + " ";
}
for(int j =0; j < 5; ++j){
if(topicLine[j].size() != 0)
topicF[j] << topicLine[j] << endl;
}
}
}
for(int i = 0; i < 5; ++i){
topicF[i].close();
}
}
//-----------------------------------------------------------
//开打一个文件
//-----------------------------------------------------------
ifstream& open_file(ifstream &in,const string &file)
{
in.close();
in.clear();
in.open(file.c_str());
return in;
}
void split(string& s, string& delim1,string &delim2, vector<string> &ret)
{
size_t last1 = 0;
size_t last2 = 0;
size_t index = 0;
size_t last = 0;
size_t index1 = s.find_first_of(delim1,last1);
size_t index2 = s.find_first_of(delim2,last2);
if(index1 > index2){
last = last2;
index = index2;
}
else {
last = last1;
index = index1;
}
//npos表示没有查找到
while (index != string::npos)
{
//printf("%d %d\n",index,last);
ret.push_back(s.substr(last,index-last));
last = index + 1;
size_t index1 = s.find_first_of(delim1,last);
size_t index2 = s.find_first_of(delim2,last);
if(index1 > index2){
index = index2;
}
else {
index = index1;
}
}
if (index-last>0)
{
ret.push_back(s.substr(last,index-last));
}
}
int main(int argc,char *argv[])
{
ifstream infile;
ofstream outVocab;
ofstream outTitle;
if(argc < 5 || !open_file(infile,argv[1])){
//vocab.exe paper.txt vocab.txt title.txt word-assignments.dat
//输入文件为:paper.txt word-assignments.dat
//输出文件为:vocab.txt title.txt
cerr << "usage:\t vocab.exe [input_file_name] [outout_vocab_file_name] [outout_title_file_name] [dat_file_name]" << endl;
return EXIT_FAILURE;
}
//将paper.txt转换成vocab.txt
VocabProcess tq;
tq.read_file(infile);
tq.write_vocab(outVocab,argv[2]);
//将vocab.txt转换成title.txt
tq.build_vocab_map(argv[2]);
tq.write_title(outTitle,argv[3]);
//将word-assignment.dat相关topic数据分类到五个文件中
tq.reorganize_terms_by_topic(argv[4]);
return EXIT_SUCCESS;
} 3.2 Apriori算法C++实现
这个算法是对数据挖掘概念与技术一书中中的Apriori算法伪代码的实现。
Apriori算法原理也可以参考这本书,讲的很详细。这里就不讲了。
伪代码如下:
//【Apriori】
// 使用逐层迭代方法基于候选产生找出频繁项集
//【输入】
// D:事务数据库
// min_sup:最小支持度阈值(绝对支持度)
//【输出】
// L,D中的频繁项集。
//【方法实现】
/*找出频繁1项集*/
L1 =find_frequent_1-itemsets(D);
For(k=2;Lk-1 !=空集;k++){
//产生候选,并剪枝
Ck =apriori_gen(Lk-1 );
//扫描 D 进行候选计数
For each 事务t 包含于 D{ //扫描D,进行计数
Ct =subset(Ck,t); //得到 t 的子集,他们是候选
For each 候选 c 包含于 Ct
c.count++;
}
//返回候选项集中不小于最小支持度的项集
Lk ={c 属于 Ck | c.count>=min_sup}
}
Return L= 所有的频繁集;
第一步:连接(join)
Procedure apriori_gen (Lk-1 :frequent(k-1)-itemsets)
For each 项集 l1 属于 Lk-1
For each 项集 l2 属于 Lk-1
If( (l1 [1]=l2 [1])&&( l1 [2]=l2 [2])&& ……&& (l1 [k-2]=l2 [k-2])&&(l1 [k-1]1]) )
then{
c = l1 连接 l2 // 连接步:产生候选
//若k-1项集中已经存在子集c则进行剪枝
if has_infrequent_subset(c, Lk-1 ) then
delete c; // 剪枝步:删除非频繁候选
else add c to Ck;
}
Return Ck;
第二步:剪枝(prune)
Procedure has_infrequent_sub (c:candidate k-itemset; Lk-1 :frequent(k-1)-itemsets)
For each (k-1)-subset s of c
If s 不属于 Lk-1 then
Return true;
Return false; C++编程实现Apriori算法:
apriori.h
#ifndef __APRIORI_H_
#define __APRIORI_H_
#include apriori.cpp
#include "apriori.h"
void Apriori::printMapSet(map< set<string> ,int> &mapSet)
{
map< set<string>, int >::iterator it = mapSet.begin();
while(it != mapSet.end()){
set<string>::iterator itSet = it->first.begin();
cout << "[" ;
while(itSet != it->first.end()){
cout << *itSet << "," ;
++itSet;
}
cout << "]" << " " << it->second << endl;
++it;
}
}
void Apriori::printsetSet(set< set<string> > &setSet)
{
set< set<string> >::iterator c2It = setSet.begin();
while(c2It != setSet.end()){
set<string>::iterator ckSetIt = (*c2It).begin();
cout << "[";
while(ckSetIt != (*c2It).end()){
cout << *ckSetIt << "," ;
++ckSetIt;
}
cout << "]"<< endl;
++c2It;
}
}
void Apriori::printSet(set<string> &setS)
{
set<string>::iterator setIt = setS.begin();
cout << "[";
while(setIt != setS.end()){
cout <<*setIt << "," ;
++setIt;
}
cout << "]" << endl;
}
//---------------------------------------------------------
//将文本数据存入到Map中,产生事务数据库D,即textDataBase
//---------------------------------------------------------
int Apriori::buildData()
{
/*打开文本文件*/
ifstream inFile;
inFile.open(dataFileName.c_str());
if(!inFile){
cerr << "open " <"is failed!" << endl;
return EXIT_FAILURE;
}
/*读取文本行*/
string textline;
vector<string> lines_of_text;
while(getline(inFile,textline))
lines_of_text.push_back(textline);
/*产生事务数据库*/
int line_num ;
for(line_num = 0; line_num != lines_of_text.size(); ++line_num){
istringstream line(lines_of_text[line_num]);
string word;
while(line >> word){
textDatabase[line_num].insert(word);
}
}
textDatabaseCount = textDatabase.size();
cout << "textDatabaseCount: " << textDatabaseCount << " " << line_num<< endl;
return EXIT_SUCCESS;
}
//-------------------------------------------------------------------------
//获取候选1项集
//-------------------------------------------------------------------------
map<string, int> Apriori::getCandidate1ItemSet()
{
map<string, int> candidate1ItemSetTemp;
map<long, set<string> >::iterator mapIter = textDatabase.begin();
set<string>::iterator setIter = mapIter->second.begin();
while(mapIter != textDatabase.end()){
while(setIter != mapIter->second.end()){
pair<map<string, int>::iterator, bool> ret =
candidate1ItemSetTemp.insert(make_pair(*setIter,1));
if(!ret.second)
++ret.first->second;
++setIter;
}
++mapIter;
setIter = mapIter->second.begin();
}
return candidate1ItemSetTemp;
}
//-------------------------------------------------------------------------
//获取频繁1项集
//-------------------------------------------------------------------------
map< set<string>, int > Apriori::findFrequent1Itemsets()
{
set<string> freq1Key;
map< set<string>, int > freq1ItemSetMap;
map<string, int> candidate1ItemSet = getCandidate1ItemSet();
map<string, int>::iterator candIt = candidate1ItemSet.begin();
while(candIt != candidate1ItemSet.end()){
if(candIt->second >= minSup){
freq1Key.erase(freq1Key.begin(),freq1Key.end());
freq1Key.insert(candIt->first);
freq1ItemSetMap[freq1Key] = candIt->second;
}
++candIt;
}
return freq1ItemSetMap;
}
//-------------------------------------------------------------------------
//根据频繁k-1项集键集获取频繁k项集
//k>1
//-------------------------------------------------------------------------
map< set<string>, int > Apriori::getFreqKItemSet(int k, set< set<string> > freqMItemSet)
{
map< set<string>, int > freqKItemSetMap;
map< set<string>, int> candFreqKItemSetMap;
set< set<string> > candFreqKItemSet = aprioriGen(k-1, freqMItemSet);
//效率是根据min_sup的值的大小决定的,大,效率高,小效率高
map<long, set<string> >::iterator mapIter = textDatabase.begin();
//下面的while循环效率很低
while(mapIter != textDatabase.end()){
set<string> itValue = mapIter->second;
set< set<string> >::iterator kit = candFreqKItemSet.begin();
while(kit != candFreqKItemSet.end()){
set<string> kSet = *kit;
set<string> setTemp(kSet.begin(),kSet.end());
removeAll(setTemp,itValue);
if(setTemp.size() == 0){
pair< map< set<string>, int >::iterator ,bool > ret =
candFreqKItemSetMap.insert(make_pair(kSet,1));
if(!ret.second)
++ret.first->second;
}
++kit;
}
++mapIter;
}
map< set<string>, int>::iterator candIt = candFreqKItemSetMap.begin();
while(candIt != candFreqKItemSetMap.end()){
if(candIt->second >= minSup){
freqKItemSetMap[candIt->first] = candIt->second;
}
++candIt;
}
return freqKItemSetMap;
}
//-------------------------------------------------------------------------
//取交集
//-------------------------------------------------------------------------
set<string> Apriori::retainAll(set<string> &set1, set<string> &set2)
{
set<string>::iterator set1It = set1.begin();
set<string> retSet;
while(set1It != set1.end()){
set<string>::iterator set2It = set2.begin();
while(set2It != set2.end()){
if((*set1It) == (*set2It)){
retSet.insert(*set1It);
break;
}
++set2It;
}
++set1It;
}
return retSet;
}
//-------------------------------------------------------------------------
//返回set1中去除了set2的数据集
//-------------------------------------------------------------------------
void Apriori::removeAll(set<string> &set1, set<string> &set2)
{
set<string>::iterator set2It = set2.begin();
while(set2It != set2.end()){
set1.erase(*set2It);
++set2It;
if(set1.size() == 0)break;
}
}
//-------------------------------------------------------------------------
//取并集
//-------------------------------------------------------------------------
set<string> Apriori::addAll(set<string> &set1, set<string> &set2)
{
set<string>::iterator set1It = set1.begin();
set<string>::iterator set2It = set2.begin();
set<string> retSet(set1.begin(),set1.end());
while(set2It != set2.end()){
retSet.insert(*set2It);
++set2It;
}
return retSet;
}
//-------------------------------------------------------------------------
//根据频繁(k-1)项集获取候选k项集
//m = k-1
//freqMItemSet:频繁k-1项集
//-------------------------------------------------------------------------
set< set<string> > Apriori::aprioriGen(int m, set< set<string> > &freqMItemSet)
{
set< set<string> > candFreqKItemSet;
set< set<string> >::iterator it = freqMItemSet.begin();
set<string> originalItemSet;
set<string> identicalSetRetain;
cout << "aprioriGen start" <while(it != freqMItemSet.end()){
originalItemSet = *it;
/*itr其实就是当前it自加一次所指*/
set< set<string> >::iterator itr = ++it;
while(itr != freqMItemSet.end()){
set<string> identicalSet(originalItemSet.begin(),originalItemSet.end());
set<string> setS(*itr);
identicalSetRetain.erase(identicalSetRetain.begin(),identicalSetRetain.end());
identicalSetRetain = addAll(identicalSet,setS);//是取originalItemSet和setS的交集
if(identicalSetRetain.size() == m+1){
if(!has_infrequent_subset(identicalSetRetain, freqMItemSet))
candFreqKItemSet.insert(identicalSetRetain);
}
++itr;
}
}
cout << "aprioriGen end" <return candFreqKItemSet;
}
//-------------------------------------------------------------------------
//使用先验知识,剪枝。删除候选k项集中存在k-1项的子集
//-------------------------------------------------------------------------
bool Apriori::has_infrequent_subset(set<string> &candKItemSet, set< set<string> > &freqMItemSet)
{
int occurs = 0;
if(freqMItemSet.count(candKItemSet))
return true;
return false;
}
//-------------------------------------------------------------------------
//获取mapSet的键值,存放于set中
//-------------------------------------------------------------------------
set< set<string> > Apriori::keySet(map< set<string>, int > &mapSet)
{
map< set<string>, int >::iterator it = mapSet.begin();
set< set<string> > retSet;
while(it != mapSet.end()){
retSet.insert(it->first);
++it;
}
return retSet;
} main.cpp
//---------------------------------------------------
//创建日期: 2015-10-14
//修改日期: 2015-10-16
//作 者: yicm
//版 本:
//说 明: Apriori算法C++实现。本实现尽可能地去提高运行效率了,
// 在aprioriGen函数中运行时间是跟min_sup有关的,min_sup越
// 大则运行时间越短,min_sup越小则运行时间越长;在getFreqKItemSet
// 函数中运行时间主要都消耗在扫描事务数据库,并统计每个候选的个数。
//---------------------------------------------------
#include map< set<string>, int> freqKItemSetMap = apriori.getFreqKItemSet(k, freqKItemSet);
if(freqKItemSetMap.size() != 0) {
set< set<string> > freqKItemSetTemp = apriori.keySet(freqKItemSetMap);
L.insert(make_pair(k,freqKItemSetTemp));
freqKItemSet = apriori.keySet(freqKItemSetMap);
}
else {
cout << "k= " << k <break;
}
}
//打印所有满足min_sup的频繁集
map<int, set< set<string> > >::iterator allLIt = L.begin();
while(allLIt != L.end()){
cout << "频繁k" << allLIt->first << "项集: " << endl;
apriori.printsetSet(allLIt->second);
++allLIt;
}
#endif
#if (0)
/*获取文本文件中原始数据*/
apriori.buildData();
cout << "----------------" << endl;
/*获取候选集1*/
map<string, int> candidate1ItemSet = apriori.getCandidate1ItemSet();
cout << "候选1项集大小: " << candidate1ItemSet.size() << endl;
/*获取频繁项集1*/
map< set<string>, int > freq1ItemSetMap = apriori.findFrequent1Itemsets();
cout << "频繁1项集大小: " << freq1ItemSetMap.size() << endl;
/*打印频繁项集1*/
cout << "-频繁1项集-" << endl;
apriori.printMapSet(freq1ItemSetMap);
/*获取候选集2*/
set< set<string> > C2 = apriori.aprioriGen(1, apriori.keySet(freq1ItemSetMap));
cout << "-候选2项集-" << endl;
apriori.printsetSet(C2);
/*获取频繁2项集*/
set< set<string> > C1 = apriori.keySet(freq1ItemSetMap);
cout << "-频繁1项集键集--" << endl;
apriori.printsetSet(C1);
map< set<string>, int> L2 = apriori.getFreqKItemSet(2,C1);
cout << "---频繁2项集----" << endl;
apriori.printMapSet(L2);
/*获取频繁3项集*/
map< set<string>, int> L3 = apriori.getFreqKItemSet(3,C2);
cout << "---频繁3项集----" << endl;
apriori.printMapSet(L3);
#endif
return 0;
} 3.3 Apriori算法实现测试
test.txt文件内容如下:
AA BB EE
BB DD
BB CC
AA BB DD
AA CC
BB CC
AA CC
AA BB CC EE
AA BB CC以min_sup=2为例:
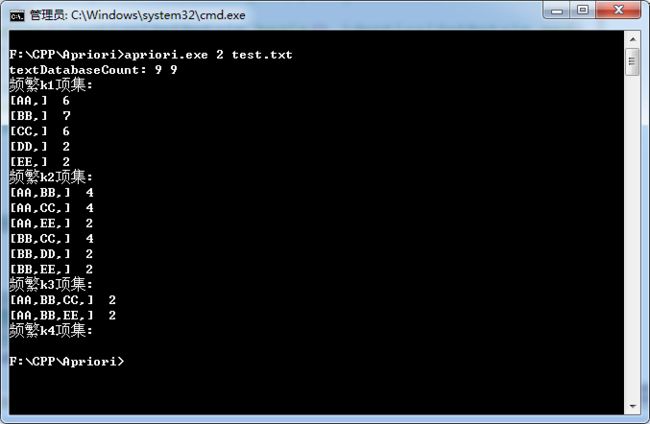
频繁4项集为空集跳出循环。