AT&T汇编之冒泡排序
冒泡排序,这个已经很多年没有写过的算法,今天没事干用AT&T汇编实现了一遍,下面就来说说怎么用汇编来实现这个冒泡排序算法。
写任何代码前一定要想好,必须写伪代码是我的风格。尤其写算法,即便是一个简单的冒泡排序,如果不想好思路,贸然动手,也可能会遇到一些坑浪费时间。
示例数组: 11, 9, 8, 8, 7, 10
冒泡排序的思想就是两两交换,直到数组有序为止。
过程分析:
1st: 9, 11
9, 8, 11
...
9, 8, 8, 7, 10, 11 冒泡出了一个最大的数字11
2nd: 8, 9
8, 8, 7, 9, 10, 11 冒泡出了第二大的数字10(这里比较巧合,9正好是第三大的数字,无视)
3rd: 8, 7, 8, 9, 10, 11 第三大9
4th: 7, 8, 8, 9, 10, 11 8
5th: 7, 8, 8, 9, 10, 11 没有发生交换,已然有序,直接终结算法
每次交换一轮可冒泡出一个最大的数字,对于长度为N的数组,只需交换N-1轮即可。
每交换一轮,下一轮会少一次交换。
如果某一轮没有发生交换,说明数组已经有序,直接终结算法。
综上,需要用双重循环,O(N^2)的算法来实现。
首先声明,本文对于数组有两种表示法,seq表示法,下标从1开始;index表示法,下标从0开始。伪代码一律用seq表示法,实现代码由于使用C++或者ASM,故需要转换为index表示法。
##方法1:
首先我们用seq表示法和index表示法来求出i和j的界限:
** seq_i(1, len-1)
#seq: i=1,max_j=len-1 i=2,max_j=len-2 => max_j=len-i
** seq_j(1, len-i) <=> index_j(0, 伪代码:
BUBBLE_SORT(A)
len = A.length
swap = false
for i in 1..len-1 do
for j in 1..len-i do
if A[j] > A[j+1]
SWAP(A[j], A[j+1])
swap = true
if swap not true
break
C++代码:
void BubbleSort(std::vector& array) {
size_t len = array.size();
bool swap = false;
for (i=1; i<=len-1; ++i) {
for (j=0; j array[j+1]) {
std::swap(array[j], array[j+1]);
swap = true;
}
}
if (!swap) {
break;
}
}
}
ASM代码:
.section .data
values:
.int 11, 9, 8, 8, 7, 10
#len = A.length
len=6
.section .bss
.lcomm output, 24
.section .text
.global _start
_start:
#BUBBE_SORT(A)
#swap = false
#for i in 1..len-1 do
mov $1, %esi
loop1:
#for j in 1..len-i do <=> index(0,len-i-1)
mov $0, %edi
loop2:
mov values(, %edi, 4), %eax
mov %edi, %ebx
inc %ebx
mov values(, %ebx, 4), %edx
#if A[j] > A[j+1]
#SWAP(A[j], A[j+1])
#swap = true
mov %eax, %ecx
sub %edx, %ecx #A[j]-A[j+1]
js skip
xchg %eax, %edx
mov %eax, values(, %edi, 4)
mov %edx, values(, %ebx, 4)
skip:
inc %edi
mov $len, %eax
sub %esi, %eax #len-i
cmp %edi, %eax #j##方法2:
因为每过一轮,会少交换一次,所以j和i是有关联的。我们可以优化j的表示方法。
BUBBULE_SORT2(A)
len = A.length
for i in len..2 do //i每减小一次,j也少一次
for j in i-1..1 do // 1. i=len,max_j=len-1=i-1 2. i=len-1,max_j=len-2=i-1 => max_j A[j+1]
SWAP(A[j], A[j+1])
//seq_i(len, 2) <=> index_i(len-1, 1) <=> index_i(len-1, >0)
//seq_j(i-1, 1) <=> index_j(i-1, 0) <=> index_j( index_j(i, 1)
//9, 2, 5, 4
//i=4,j<4=3
//i=3,j<3=2
//j建立的是和i和关系,和len无关
在这里需要说明的是,index表示法只是一种表示方法,可以用来表示下标,但也可以用来进行计数。下面的代码就是用index_j来计数。
ASM代码:
.section .data
values:
.int 11, 6, 8, 8, 7, 3
#len = A.length
len=6
.section .text
.global _start
#BUBBULE_SORT2(A)
_start:
mov $values, %esi
mov $len-1, %ebx #i
mov %ebx, %ecx #j
loop:
#for i in len..2 do //i每减小一次,j也少一次
#for j in i-1..1 do //1. i=len,max_j=len-1=i-1 2. i=len-1,max_j=len-2=i-1 => max_j=i-1 index_i(len-1, 1) <=> index_i(len-1, >0)
#seq_j(i-1, 1) <=> index_j(i-1, 0) <=> index_j( index_j(i, 1)
#A=[9, 2, 5, 4]
#seq: i=4,j<4=3
#index: i=3,j<3=2
#j建立的是和i的关系,和len无关,和是索引还是序列号无关
mov (%esi), %eax
#if A[j] > A[j+1]
#SWAP(A[j], A[j+1])
cmp %eax, 4(%esi)
jge skip
xchg %eax, 4(%esi)
mov %eax, (%esi)
skip:
add $4, %esi
dec %ecx #index_j(i, 1) j控制每次交换的次数
jnz loop
dec %ebx #index_i(len-1, 1) => --i
jz end
mov %ebx, %ecx #j=i
mov $values, %esi #从头开始交换
jmp loop
end:
xor %rdi, %rdi
call exit
可以使用gdb查看排序结果:
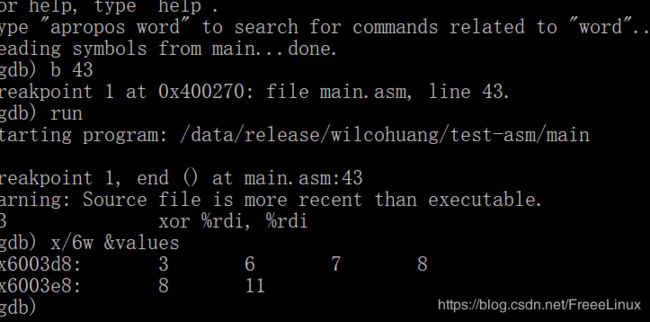
就这样,我们就得到一个排好序的数组啦~