用python爬取二手房交易信息并进行分析
用python爬取二手房交易信息并分析
- 第一步:编写爬虫
爬取某平台上海市十个区共900条二手房的交易信息
#爬取上海十个区的二手房价信息
import requests
from bs4 import BeautifulSoup
import csv
#获取房价的文本信息
def gethousetext(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "error"
# 获得房子的价格、面积、详细信息等
def gethouseinfo(h_list, html, loc):
h_info = []
soup = BeautifulSoup(html, "html.parser")
house_info = soup.find_all('div', attrs={'class': "listX"})
# 将房屋信息储存在一个列表里
for h in house_info:
p = h.find_all('p')
h_info = [p[0].text, loc, p[2].text, p[3].text, p[4].text]
h_list.append(h_info)
def storehouseinfo(h_list, fpath):
# 打开csv文件,写入数据
with open(fpath, 'w', encoding='utf-8') as f:
house_csv = csv.writer(f, dialect='excel')
house_csv.writerow(["基础信息","区域","访问情况","总价","单价"])
for t in h_list:
house_csv.writerow(t)
def main():
place = ['pudongxinqu', 'minxingqu', 'xuhuiqu', 'putuoqu', 'baoshanqu', 'yangpuqu', 'hongkouqu', 'jiadingqu',
'huangpuqu', 'jinganqu']
place_name = ['浦东新区', '闵行区', '徐汇区', '普陀区', ' 宝山区', '杨浦区', '虹口区', '嘉定区', '黄浦区', '静安区']
path = 'C:/Users/晴蓝/Desktop/house_price.csv'
house_list = []
for x, y in zip(place, place_name):
sh_url = "https://sh.5i5j.com/ershoufang/" + x
for p in range(1, 4):
h_url = sh_url + "/n" + str(p)
html = gethousetext(h_url)
gethouseinfo(house_list, html, y)
storehouseinfo(house_list, path)
main()
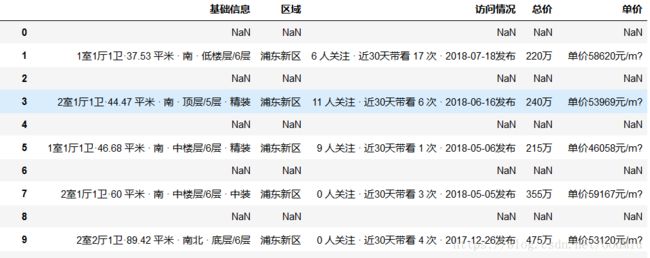
爬取结果展示
- 第二步:提取有效信息
代码展示
import pandas as pd
data = pd.read_csv('C:/Users/晴蓝/Desktop/house_info_list.csv', engine='python')
#data中每隔一行都有空值, 清除空值
data = data.dropna()
data['location'] = data['区域']
#从data的基础信息中提取出房间布局、房屋面积、装修情况
data['room'] = data['基础信息'].str.split('·').str[0]
data['house_area'] = data['基础信息'].str.split('·').str[1].str.split(' ').str[0]
#从访问情况获取关注人数和带看次数
data['attention'] = data['访问情况'].str.split('·').str[0].str.split(' ').str[0]
data['recent_visit_times'] = data['访问情况'].str.split('·').str[1]
data['recent_visit_times'] = data['recent_visit_times'].str.replace(' ','').str[6:-1]
#获取单价和总价
data['house_price'] = data['总价'].str[:-1]
data['per_square_price'] = data['单价'].str[2:-4]
#清除脏数据
del data['区域']
del data['基础信息']
del data['访问情况']
del data['总价']
del data['单价']
#将数据保存到新的文件下
data.to_csv('C:/Users/晴蓝/Desktop/house_cleaning_data.csv', encoding='utf-8')
结果展示:

第三步:进行可视化分析
#小户型市场前景好
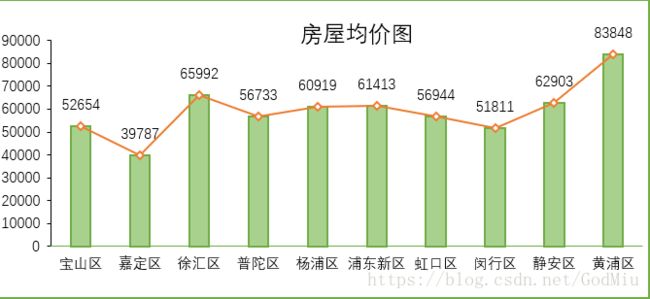
房价随着距离市中心的距离不断变化。嘉定区因为距离较远,所以房价在十个区中最低,其他9个区的房屋每平方的均价都在50000以上。且处于上海外环外的地区的嘉定、宝山、闵行房屋均价比位于上海外环外的房屋均价都低。而浦东新区并不完全属于外环内,但房屋均价却比较高
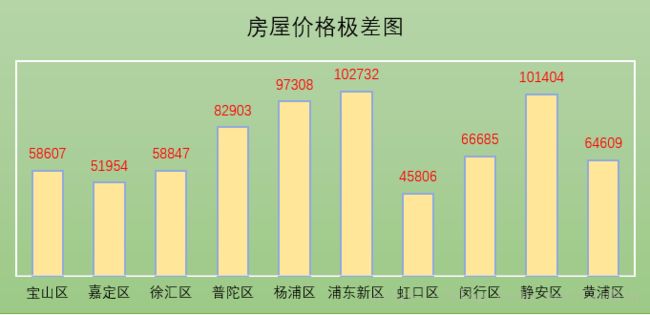
图中可以看到浦东新区的房价极差是最高的,主要是浦东新区的区域面积比较大,一部分在外环内另一部分在外环外,房屋价格差异较大,在外环内的房价在一定程度上拉高了浦东新区的房价说水平
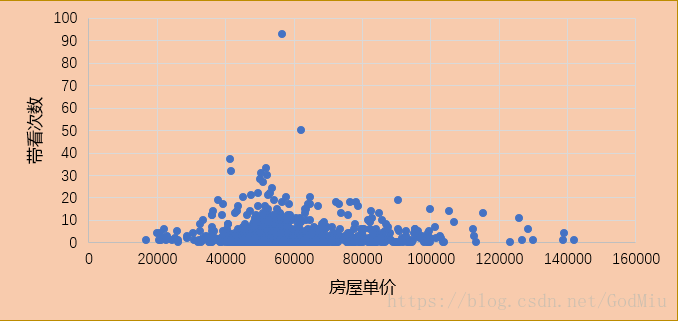
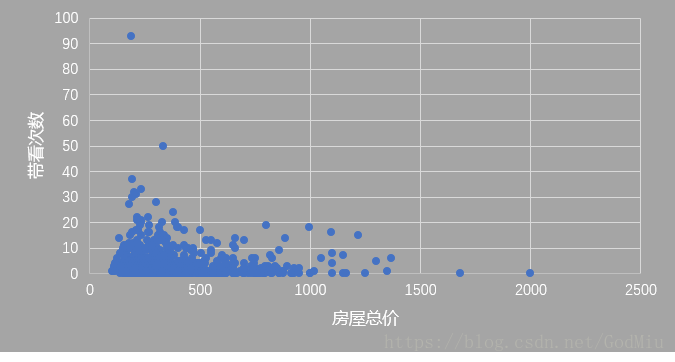
第一张图点数分布两边少中间多,带看次数在总体上先随着价格增多,在80000左右的时候总体的带看次数随着价格的增加而开始下降。图中的数据有点左偏,说明二手房的购买者经济能力并不是很足,偏向于单价在40000到60000之间的房子。
第二张图的点数分布主要集中在500万以下的区域,同前一张图的结论相同,二手房的购买者更倾向于价格更低的二手房
房屋的总价收到单价和房屋面积的影响,房屋的面积与房屋的户型有很大的关系,户型越多房屋的面积就越大。
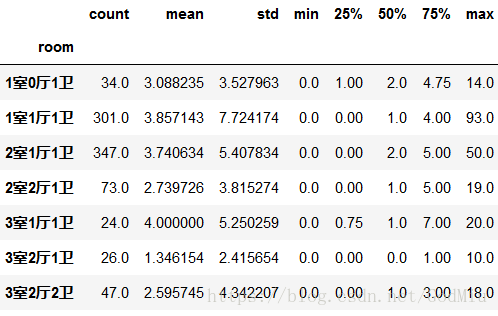
这是各个区户型总数在20以上的带看次数
从爬取的户型总数来看,二手房小户型1室1厅1卫和2室1厅1卫所在比重大,接近三分之二的户型都是小户型,其中的原因主要是小户型购买的经济压力较小,且多数人是因为家里人口增多,收入变高,打算卖房买房。小户型带看次数平均值都在3.0以上,说明大家对二手房小户型的中意程度比较高。
结论:小户型二手房的购买者主要是经济能力不是很足但又是买房刚需的年轻小两口,小户型的价格相对来说比较低,且从上述不同户型的平均带看次数来看,小户型二手房的前景依旧不错。
#发现问题
网站内容的访问次数和关注度能够表现出该内容对访问者的影响力,同时可以看出访问者对该内容的注意程度,网站的所有者可以从中挖掘出大量的商业信息。
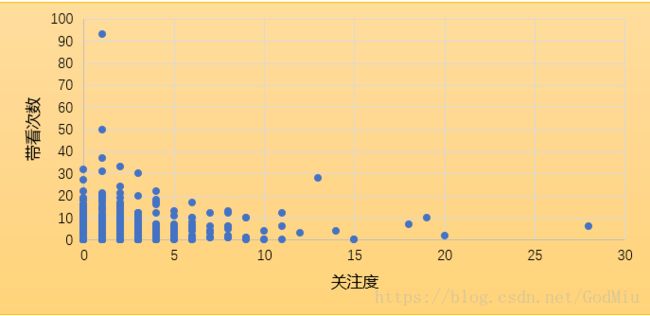
图中数据是某平台二手房每个房屋的关注度和实际带看次数。
两种数据的散点图没能发现明显的规律,假设两种数据不具有明显的线性关系。运用线性模型求得带看次数与关注次数的相关系数为0.0914,该值接近0,基本上两者没有相关性,假设正确。说明网站上房屋的关注度并没有进一步的转换为房屋的实际带看次数.
正常情况下,网页上的关注度越多,那么实际的带看次数也应当越多,那么有那些原因会造成上述情况呢?
1、网站里房屋的关注度是虚假的,是网站所有者随意杜撰的。
2、网站房屋的关注度是真的,但却是房屋所有者利用众多小号或其他手段关注自己的房屋造成的关注量大的假象。
3、网站所有者对房屋关注度的转化不够重视,没有利用好这个流量。
该如何解决这些情况呢(争对后两种情况):
1、网站所有者可以设立一些确认是真实关注者的指标,比如根据关注者在该房屋页面的停留时间的长短,和对该页面重复访问的次数来判断是否关注者的真假性。
2、根据用户的年龄、工作等判断是否有购房的需求和能力。
3、根据用户的访问时间的长短和次数来判断用户是否可以持续追踪。
4、观察用户是否有过咨询记录,判断用户是否真正有需要购房。
5、可以对关注用户进行房屋的电话推销,进一步的了解用户的需求,将其转化为实际的带看人数。