Neo4j图数据库高级应用系列 / 服务器扩展指南 (3.1) - 基本路径扩展过程
1、概述
路径扩展过程(Path Expanding)是从指定的一个或一组起始节点开始,根据过滤规则沿着特定关系依次访问其他相连节点的过程。该过程迭代执行,直到没有更多相连节点或者预设的结束条件满足时终止。路径扩展可以看作是图的遍历(Graph Traversal)的一种实现方式。
2、应用
在Cypher中也可以实现图的遍历。APOC的路径扩展过程除了调用方法不一样以外,还具有下面的优势:
1) 更加多样的遍历方式。
2) 更加细粒度的遍历过程控制。
3) 更好的执行性能。
4) 可扩展性更好。
3、过程接口
CALL apoc.path.expand(
startNode
relationshipFilter,
labelFilter,
minDepth,
maxDepth )
YIELD path AS
参数名 类型 缺省值 可为空? 说明
startNode LONG - 节点id,或者Node - 节点对象 无 否 遍历的起始节点
relationshipFilter 关系过滤器规则 NULL 是 参见3.2.2
labelFilter 标签过滤器规则 NULL 是 参见3.2.1
minDepth INTERGER 0 是 最小遍历层次数。
maxDepth INTEGER -1 是 最大遍历层次数。-1表示不限制,直到不再有可遍历的路径为止。
4、示例数据
**(注意:因为在线文本编辑器的原因,下面查询中文本的引号不能正确显示,请做必要的替换后执行)**
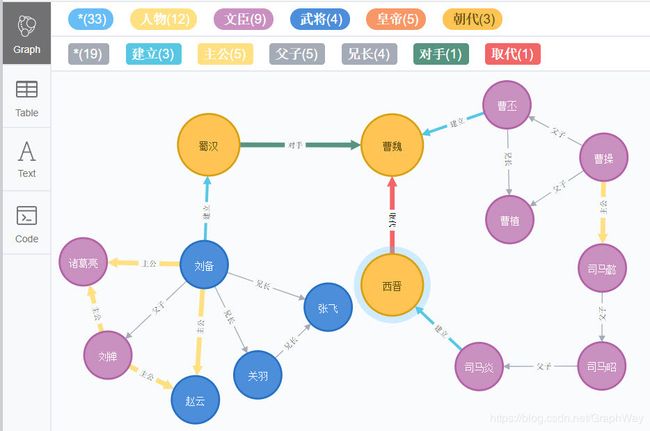
// 3.3A 创建三国人物关系图
CREATE (n1:`人物`:`皇帝`:`文臣`:`武将` {name: '刘备'})
-[:兄长]-> (n2:`人物`:`武将` {name: '关羽'}),
(n2) -[:兄长]-> (n3:`人物`:`武将` {name: '张飞'}),
(n1) -[:兄长]-> (n3),
(n1) -[:主公]-> (n4:`人物`:`武将` {name: '赵云'}),
(n1) -[:父子]-> (n5:`人物`:`皇帝`:`文臣` {name: '刘禅'}),
(n1) -[:主公]-> (n6:`人物`:`文臣` {name: '诸葛亮'}),
(n5) -[:主公]-> (n4),
(n5) -[:主公]-> (n6),
(a1:`朝代`{name:'蜀汉'}) -[:对手]-> (a2:`朝代`{name:'曹魏'}),
(a3:`朝代`{name:'西晋'}) -[:取代]-> (a2),
(m1:`人物`:`文臣` {name: '曹操'})
-[:父子]-> (m2:`人物`:`文臣`:`皇帝` {name: '曹丕'}),
(m1) -[:父子]-> (m3:`人物`:`文臣` {name: '曹植'}),
(m2) -[:兄长]-> (m3),
(m1) -[:主公]-> (m4:`人物`:`文臣` {name: '司马懿'}),
(m4) -[:父子]-> (m5:`人物`:`文臣` {name: '司马昭'}),
(m5) -[:父子]-> (m6:`人物`:`文臣`:`皇帝` {name: '司马炎'}),
(n1) -[:建立{year:221}]-> (a1),
(m2) -[:建立{year:220}]-> (a2),
(m6) -[:建立{year:266}]-> (a3)
运行上面的Cypher查询会得到以下三国人物关系图:
5、样例查询
// 3.3(1) 调用基本路径扩展过程,从“蜀汉”节点出发遍历图。
// 参数:- startNode:代表“蜀汉”的节点
// - relationshipFilter: NULL
// - labelFilter: NULL
// - minLevel: 0
// - maxLevel: -1,遍历直到返回能够到达的所有路径
// 返回结果:所有170条路径、15个节点、19个关系。
MATCH (n:朝代{name:'蜀汉'})
CALL apoc.path.expand(n,NULL,NULL,0,-1) YIELD path
RETURN path
// 3.3(2) 调用基本路径扩展过程,从“蜀汉”节点出发遍历图。
// 参数:- startNode:代表“蜀汉”的节点
// - relationshipFilter: NULL
// - labelFilter: -朝代,即遍历到其他“朝代”节点终止。
// - minLevel: 0
// - maxLevel: -1,遍历直到返回能够到达的所有路径
// 返回结果:蜀汉的所有人物。
MATCH (n:朝代{name:'蜀汉'})
CALL apoc.path.expand(n,NULL,'-朝代',0,-1) YIELD path
RETURN path
// 3.3(3) 调用基本路径扩展过程,从“蜀汉”节点出发遍历图。
// 参数:- startNode:代表“蜀汉”的节点
// - relationshipFilter: NULL
// - labelFilter: +皇帝|朝代
// - minLevel: 0
// - maxLevel: -1,遍历直到返回能够到达的所有路径
// 返回结果:三国时期的所有朝代及其皇帝。
MATCH (n:朝代{name:'蜀汉'})
CALL apoc.path.expand(n,NULL, '+皇帝|朝代',0,-1) YIELD path
RETURN path
---- 待续 ----
(下篇:3.2 可配置的路径扩展过程)