Hadoop 及 Hive 压缩应用
1.压缩在Hadoop中的应用
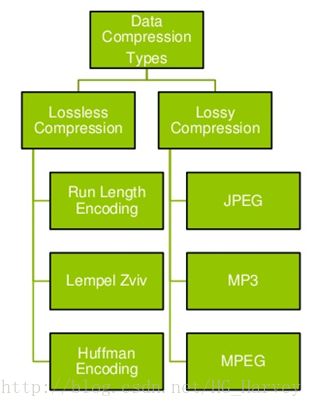
1.压缩概述
为什么使用压缩?文件压缩主要有两个好处:一是减少了存储文件所占空间,二是提高了数据的传输速度,在大数据环境下,这两点显的尤为重要。压缩主要应用在输入文件(Map的输入)、输出文件(Reduce的输出)及中间输出(只有Map,没有Reduce,Map的输出)。
常用的压缩技术有两种,一种是无损压缩(Lossless compression),一种是有损压缩(Lossy compression),无损压缩后文件内容不会丢失,解压后和源文件一模一样,而有损压缩后文件内容会丢失。
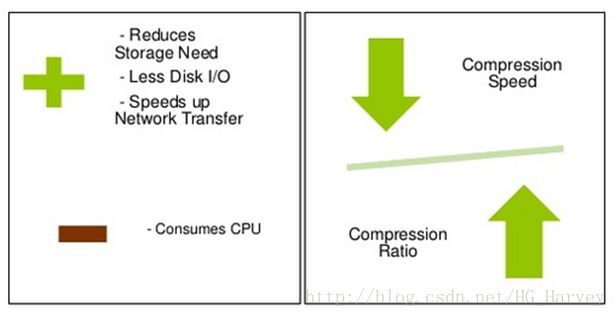
使用压缩后,磁盘空间会减少,从而在读取磁盘IO就会减少,网络带宽也会减少,但是不管是压缩还是解压,这个过程都会用到CPU,所以CPU的利用率及用时就会增加,也就是所谓的鱼和熊掌不可兼得,压缩既有它的优点也也有缺点。
那么这两者该如何权衡呐?根据我们的实际情况,来决定是否使用压缩,选用合适的压缩,比如,在集群环境中,你的CPU利用率很低,但是磁盘空间已经负载比较高了,这种情况下可以使用压缩,但是如果你的CPU的利用率很高,就不建议使用压缩了,这样会使你的CPU利用率更高,提高了集群环境的风险,得不偿失。

2.压缩格式
常用的压缩格式
| 压缩格式 | 工具 | 算法 | 扩展名 | 是否支持分割 |
|---|---|---|---|---|
| gzip | gzip | DEFLATE | .gz | NO |
| bzip2 | bzip2 | bzip2 | .bz2 | YES |
| LZO | lzop | LZOP | .lzo | Yes if indexed |
| Snappy | N/A | Snappy | .snappy | NO |
环境配置如下,使用各种压缩对1.4G的文件进行压缩,对比情况如下
8 core i7 CPU
8GB memory
64 bit CentOS
1.4GB Wikipedia Corpus 2-gram text input
常用压缩的压缩比
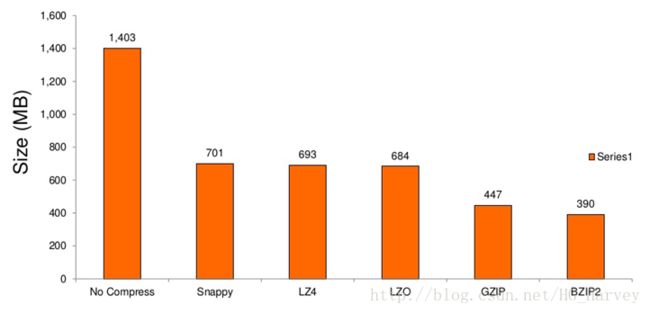
常用压缩的压缩率
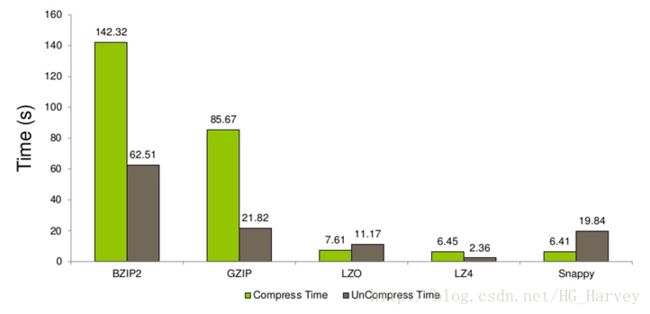
总结:使用压缩可以减少磁盘空间、IO及网络宽带,但是会提高CPU的利用率,压缩比与压缩速度成反比,压缩比越高,压缩速度越慢
3.压缩在MapReduce中的应用
hadoop使用压缩的前提是:编译hadoop源码,输入如下命令来检查hadoop是否支持压缩
$ hadoop checknative如果看到和下图一样的效果,表示hadoop中可以使用压缩,如果你执行后看到的是false,请参考博客:http://blog.csdn.net/hg_harvey/article/details/77540064

压缩在mapreduce中的应用
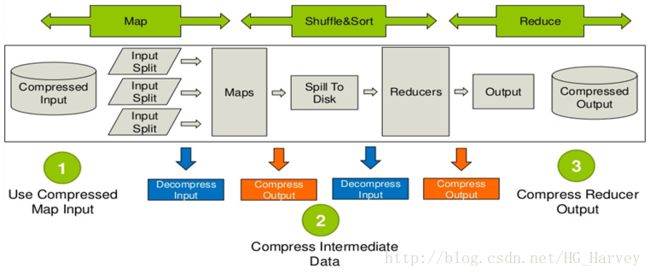

(1).Use Compressed Map Input
map的输入建议使用支持分割的压缩,比如Bzip2,因为可以并行处理
(2).Compress Intermediate Data
中间数据的压缩建议使用压缩速度快的,比如Snappy、LZO,可以节省时间,提高效率
(3).Compress Reducer Output
Reduce的输出建议使用压缩比较高的压缩,压缩后文件较小,减少磁盘空间。
案例:统计单词出现的次数
新建文件hello.txt并编辑文件内容如下
hello hadoop
hello mapreduce
hello hadoop yarn
hello zookeeper
hello hbase
hello hive上传文件到hdfs
$ hadoop fs -mkdir -p /user/hadoop/input
$ hadoop fs -put hello.txt input/
$ hadoop fs -ls
$ hadoop fs -text input/*
进入hadoop-mapreduce-examples-2.7.3.jar所在目录
$ cd /usr/local/hadoop/share/hadoop/mapreduce/
- 不使用压缩
$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount input/ output/查看结果
$ hadoop fs -ls output/
$ hadoop fs -cat output/part-r-00000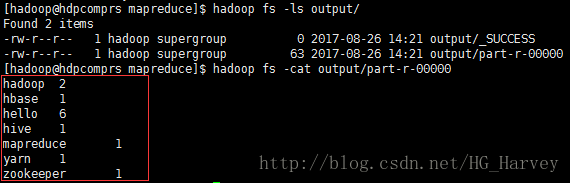
- 使用压缩
hadoop 中使用压缩需要进行配置,有两种方式,一种配置在hadoop的配置文件中,一种直接在命令中指定参数即可,笔者使用第二种方式,如果配置在文件中,请按如下操作
io.compression.codecs
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec
<property>
<name>mapreduce.output.fileoutputformat.compressname>
<value>truevalue>
property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codecname>
<value>org.apache.hadoop.io.compress.BZip2Codecvalue>
property>
<property>
<name>mapreduce.map.output.compressname>
<value>truevalue>
property>
<property>
<name>mapreduce.map.output.compress.codecname>
<value>org.apache.hadoop.io.compress.BZip2Codecvalue>
property>使用MapReduce 压缩统计单数出现的次数,执行命令(执行前先删除output文件)
$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec -Dmapreduce.map.output.compress=true -Dmapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.BZip2Codec input/ output/查看结果
$ hadoop fs -ls output/
$ hadoop fs -text output/part-r-00000.bz2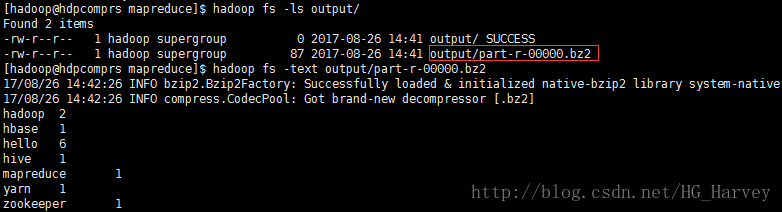
2.压缩格式在Hive中的应用
1.Hive 中的存储格式
hive 中支持的存储格式如下
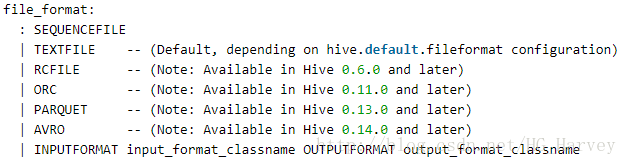
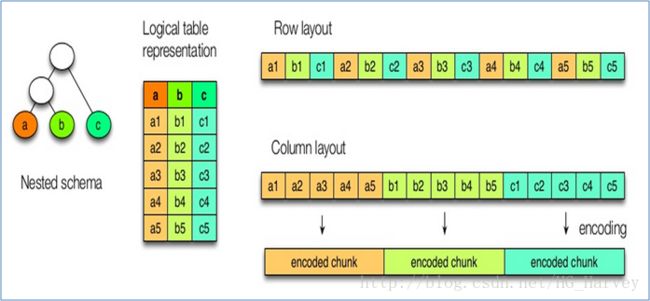
sequencefile和textfile是面向行存储的,rcfile、orc、parquet是面向列存储的的,那么面向行存储和面向列存储的区别是什么呐?
行式存储
比如下图中想要获取A列和C列中的数据,由于是行式存储,所有会对文件中的所有行进行读取,然后取出A列和C列中的值,当我们的查询条件只针对表中的少数几列时,无法跳过那些不必要的列,这样就会对于磁盘IO开销较大、效率较低,不能进行快速查询。

行式存储的特点:
1).一行记录的所有字段都存在一个block里;
2).每一行中混合多种不同类型的值(列),不容易获得一个极高的压缩比;
3).不能支持快速查询
列式存储
列式存储会将列进行分组,如下图,将A和B列存放到Group1中,C列存放在Group2中,D列存放在Group3中,比如想要获取C列中的数据,那么会直接去Group2中获取数据,跳过了不必要的列,效率较高,减少了磁盘IO,因为每列分组后存储的数据的类型是相同的,所以我们可以选择不同的压缩,提高压缩比。

列式存储的特点:
1).不能保证一行数据的多列都存储在一个block;
2).查询时能够避免读取不必要的列;
3).每一列的数据类型肯定是相同的,可以针对每列选择适合自己的压缩方式,能够达到较高的压缩比;
总结:列式存储可以减少磁盘空间、减少磁盘IO、提高查询性能
2.Hive 中存储格式的使用
1.TextFile
hive 中默认的存储格式为textfile,存储方式为行存储,不支持分割。
有一个文件page_views.dat,内容截图如下
$ more data/page_views.dat
- 不压缩
创建表page_views
create table page_views(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';查看表的存储信息
desc formatted page_views;
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat加载数据
load data local inpath '/home/hadoop/data/page_views.dat' overwrite into table page_views;
查看未压缩前表对应HDFS中文件大小
dfs -du -h /user/hive/warehouse/db_comprs.db/page_views;
18.1 M /user/hive/warehouse/db_comprs.db/page_views/page_views.dat- 压缩
压缩前需要配置如下参数(也可以配置在hive-site.xml中,永久生效)
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec;创建表page_views_compress 并压缩(TextFile+BZip2)
create table page_views_compress ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' as select * from page_views;表的存储信息与表page_views相同
查看压缩后表page_views_compress对应hdfs中文件的大小
dfs -du -h /user/hive/warehouse/db_comprs.db/page_views2;
3.6 M /user/hive/warehouse/db_comprs.db/page_views2/000000_0.bz22.SequenceFile
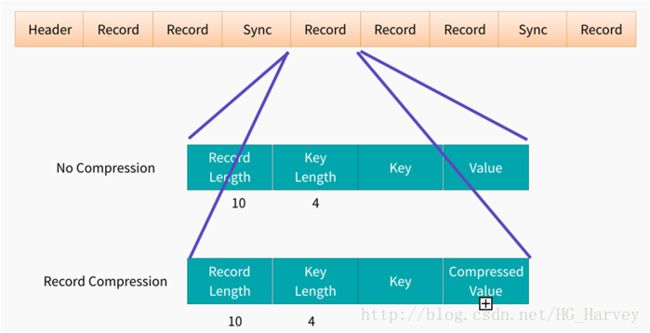
key、value形式存储,二进制类型,存储方式为行存储。
支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩
SequenceFile构成图
创建表page_views_seq(创建表的时候数据直接从表page_views中加载)
create table page_views_seq
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as sequencefile
as select * from page_views;也可以先创建表,再加载数据
create table page_views_seq(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as sequencefile;但加载数据时如果使用load会报如下错误
load data local inpath '/home/hadoop/data/page_views.dat' overwrite into table page_views_seq;Failed with exception Wrong file format. Please check the file’s format.
FAILED: Execution Error, return code 1 from
org.apache.hadoop.hive.ql.exec.MoveTask
解决方法:使用insert加载数据
insert into table page_views_seqselect * from page_views;查看表的存储信息
desc formatted page_views_seq;
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.SequenceFileInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat查看表对应HDFS中的文件大小
dfs -du -h /user/hive/warehouse/db_comprs.db/page_views_seq;
19.6 M /user/hive/warehouse/db_comprs.db/page_views_seq/000000_03.RCFile
全称:Record Columnar File,存储方式:行列混合存储(先根据行进行分组,然后把行转为列存储),压缩后比源文件小10%左右。
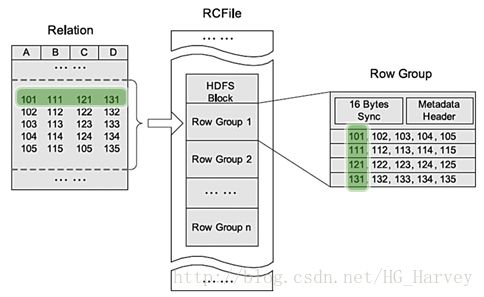
创建表page_views_rcfile
create table page_views_rcfile
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as rcfile
as select * from page_views;查看表的存储信息
desc formatted page_views_rcfile;
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe
InputFormat: org.apache.hadoop.hive.ql.io.RCFileInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.RCFileOutputFormat查看表对应HDFS中的文件大小
dfs -du -h /user/hive/warehouse/db_comprs.db/page_views_rcfile;
18.0 M /user/hive/warehouse/db_comprs.db/page_views_rcfile/000000_0总结:TextFile、SequenceFile、RCFile三者对比
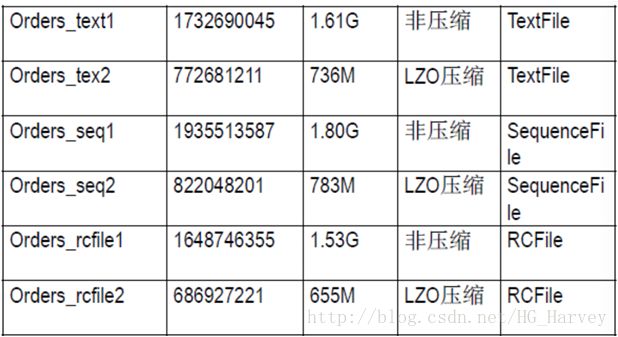
4.ORC
全称为Optimized Row Columnar,存储方式为列式存储,它对RCFile做了一些优化,使用ORC可以提高Hive的读、写以及处理数据的性能。
官网:https://orc.apache.org/
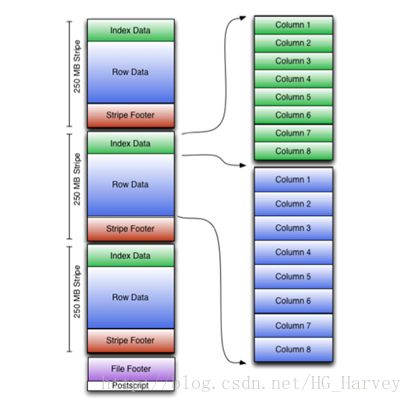
ORC支持多种压缩方式,可以通过相关参数指定,常用的配置参数如下

不同方式压缩对比(ORCFile的压缩比最高)
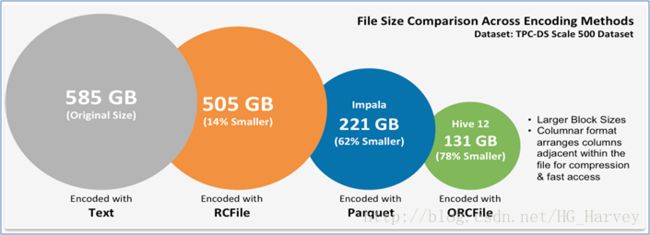
- 不压缩
创建表page_views_orc
create table page_views_orc
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as orc
tblproperties ("orc.compress"="NONE")
as select * from page_views;查看表的存储信息
desc formatted page_views_orc;
# Storage Information
SerDe Library: org.apache.hadoop.hive.ql.io.orc.OrcSerde
InputFormat: org.apache.hadoop.hive.ql.io.orc.OrcInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat查看表对应HDFS中的文件大小
dfs -du -h /user/hive/warehouse/db_comprs.db/page_views_orc;
7.7 M /user/hive/warehouse/db_comprs.db/page_views_orc/000000_0- 使用zlib压缩(ORC+ZLIB)
create table page_views_orc_zlib
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as orc
tblproperties ("orc.compress"="ZLIB")
as select * from page_views;表的存储信息与表page_views_orc相同
查看表对应HDFS中的文件大小
dfs -du -h /user/hive/warehouse/db_comprs.db/page_views_orc_zlib;
2.8 M /user/hive/warehouse/db_comprs.db/page_views_orc_zlib/000000_0- 使用snappy压缩(ORC+Snappy)
创建表page_views_orc_snappy
create table page_views_orc_snappy
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as orc
tblproperties ("orc.compress"="SNAPPY")
as select * from page_views;表的存储信息与表page_views_orc相同
查看表对应HDFS中的文件大小
dfs -du -h /user/hive/warehouse/db_comprs.db/page_views_orc_snappy;
3.7 M /user/hive/warehouse/db_comprs.db/page_views_orc_snappy/000000_05.Parquet
存储方式:列式存储,支持的大数据框架有hive、spark、pig等。
- 不压缩
创建表page_views_parquet
create table page_views_parquet
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as parquet
as select * from page_views;查看表的存储信息
# Storage Information
SerDe Library: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat查看表对应HDFS中的文件大小
dfs -du -h /user/hive/warehouse/db_comprs.db/page_views_parquet;
13.1 M /user/hive/warehouse/db_comprs.db/page_views_parquet/000000_0- 使用gzip压缩(Parquet+GZIP)
设置压缩方式
set parquet.compression=GZIP;create table page_views_parquet_gzip ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as parquet as select * from page_views;表的存储信息与page_views_parquet相同
查看表对应HDFS中的文件大小
dfs -du -h /user/hive/warehouse/db_comprs.db/page_views_parquet_gzip;
3.9 M /user/hive/warehouse/db_comprs.db/page_views_parquet_gzip/000000_06.测试各种压缩查询性能
通过统计session_id为B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1有多少行记录。查看各种存储格式压缩前后从HDFS中的读取数据情况
1. TextFile
- 不压缩
select count(1) from page_views where session_id = 'B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';HDFS Read: 19024011- 压缩后(TextFile+BZip2)
select count(1) from page_views_compress where session_id = 'B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';HDFS Read: 38329672. SequenceFile
select count(1) from page_views_seq where session_id = 'B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';HDFS Read: 205105873. RCFile
select count(1) from page_views_rcfile where session_id = 'B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';HDFS Read: 37268274. ORC
- 不压缩
select count(1) from page_views_orc where session_id = 'B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';HDFS Read: 1776857- 使用zlib压缩(ORC+ZLIB)
select count(1) from page_views_orc_zlib where session_id = 'B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';HDFS Read: 1258547- 使用snappy压缩(ORC+Snappy)
select count(1) from page_views_orc_snappy where session_id = 'B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';HDFS Read: 17523305. Parquet
- 不压缩
select count(1) from page_views_parquet where session_id = 'B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';HDFS Read: 2688443- 使用gzip压缩(Parquet+GZIP)
select count(1) from page_views_parquet_gzip where session_id = 'B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';HDFS Read: 1625928