基于贝叶斯算法的拼写检查器
简介:
本篇博文先介绍针对于英文单词的拼写错误的检测以及纠错,然后简单介绍了拼写检查器的原理以及贝叶斯算法在拼写纠错的应用。
通过Java的可视化界面,做了一个简单的电子词典。

代码地址:https://github.com/hlk-1135/Dictionary
一、拼写纠错定义
拼写纠错(Spelling Correction),又称拼写检查(Spelling Checker),往往被用于字处理软件、输入法和搜索引擎中。
拼写纠错一般可以拆分成两个子任务:
- 拼写错误检测Spelling Error Detection:按照错误类型不同,分为Non-word Errors和Real-word
Errors。前者指那些拼写错误后的词本身就不合法,如错误的将“giraffe”写成“graffe”;后者指那些拼写错误后的词仍然是合法的情况,如将“there”错误拼写为“three”(形近),将“peace”错误拼写为“piece”(同音),将“two”错误拼写为“too”(同音)。 - 拼写纠错Spelling Error Correction:自动纠错,如把“hte”自动校正为“the”,或者给出一个最可能的拼写建议,甚至一个拼写建议列表。
二、Non-word拼写错误
拼写错误检测Spelling error detection:任何不被词典所包含的word均被当作拼写错误(spelling error),识别准确率依赖词典的规模和质量。
拼写纠错Spelling error correction:查找词典中与error最近似的word,常见的方法有:最短加权编辑距离(Shortest weighted edit distance)和最高噪音通道概率(Highest noisy channel probability)。
三、Real-word拼写错误
拼写错误检测Spelling error detection:每个word都作为拼写成员(spelling error candidate)。
拼写纠错Spelling error correction:从发音和拼写等角度,查找与word最近似的words集合作为拼写建议,常见的方法有最高噪音通道概率(Highest noisy channel probability)和分类(Classifier)。
四、基于噪声信道模型(Noisy Channel Model)的拼写纠错
Noisy Channel Model即噪声信道模型,或称信源信道模型,这是一个普适性的模型,被用于语音识别、拼写纠错、机器翻译、中文分词、词性标注、音字转换等众多应用领域。其形式很简单,如下图所示:

噪声信道试图通过带噪声的输出信号恢复输入信号,形式化定义为:
![]()
应用于拼写纠错任务的流程如下:
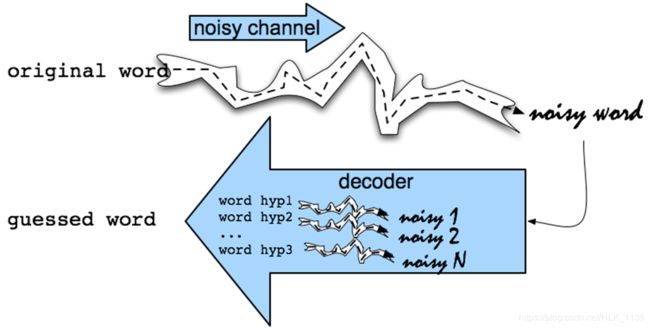
noisy word(即splling error)被看作original word通过noisy channel转换得到,现在已知noisy word(用x表示)如何求得最大可能的original word(用w表示),公式如下:

P(w)为先验概率,P(x|w)为转移概率,二者可以基于训练语料库建立语言模型和转移矩阵(又称error model,channel model)得到。
五、拼写检查器
第一步,以一个比较大的文本文件big.txt作为样本,分析每个单词出现的概率作为语言模型(Language Model)和词典。
big.txt的地址是:http://norvig.com/big.txt
第二步,如果用户输入的单词不在词典中,则产生编辑距离(Edit Distance)为2的所有可能单词。所谓编辑距离为1就是对用户输入的单词进行删除1个字符、添加1个字符、交换相邻字符、替换1个字符产生的所有单词。而编辑距离为2就是对这些单词再进行一次上述所有变换,因此最后产生的单词集会很大。可以与词典作差集,只保留词典中存在的单词。
1)插入一个字符(Insertion)
2)删除一个字符(Deletion)
3)替代一个字符(Substitution)
4)转义一个字符(Transposition)
第三步,假设事件c是我们猜测用户可能想要输入的单词,而事件w是用户实际输入的错误单词,根据贝叶斯公式可知:
P(c|w) = P(w|c) * P(c)/ P(w)
这里的P(w)对于每个单词都是一样的,可以忽略。而P(w|c)是误差模型(Error Model),是用户想要输入w却输入c的概率,这是需要大量样本数据和事实依据来得到的,为了简单起见也忽略掉。因此,我们可以找出编辑距离为2的单词集中P(c)概率最大的几个来提示用户。
据统计,80%的拼写错误编辑距离为1,几乎所有的拼写错误编辑距离小于等于2,基于此,可以减少大量不必要的计算。
通过计算最小编辑距离获取拼写建议候选集(candidate w),此时,我们希望选择概率最大的w作为最终的拼写建议,基于噪声信道模型思想,需要进一步计算P(w)和P(x|w)。
通过对语料库计数、平滑等处理可以很容易建立语言模型,即可得到P(w)。
六、可视化应用
1、项目介绍:基于贝叶斯算法的电子词典
- 语言以及数据库:Java+MySQL
- 开发工具:Eclipse
2、功能模块

运行效果:
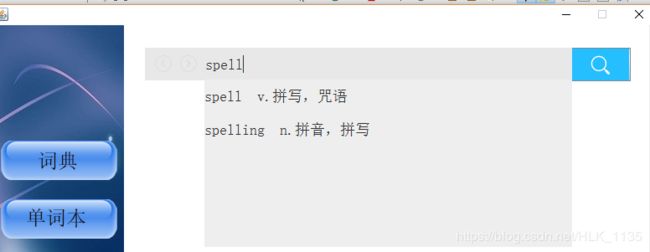
1)运行Main.java

2)输入spell
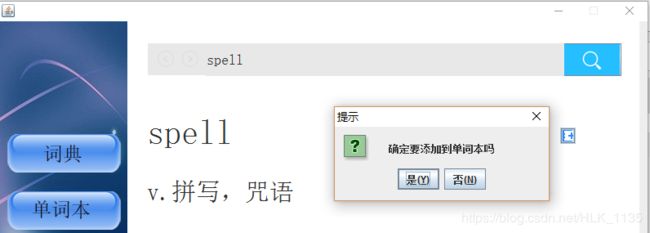
3)输入我们在上文中所提到的错误单词“hte”

同时我们在Eclipse的后台中可以看到相同的提示:

对于拼写的检测以及修改,主要为SpellChecker类:
public class SpellChecker {
private static final char[] alphabets = "abcdefghijklmnopqrstuvwxyz".toCharArray();
public void start() throws IOException {
//1.构建语言模型
String path = "E:\\big.txt";
Map<String, Double> languModel = buildLanguageModel(path);
Set<String> dictionary = languModel.keySet();
while((input = reader.readLine()) != null) {
input = input.trim().toLowerCase();
if("bye".equals(input))
break;
if(dictionary.contains(input))
continue;
long startTime = System.currentTimeMillis();
//3.在编辑距离内设置一个单词集,并删除字典中不存在的单词
Set<String> wordsInEditDistance = buildEditDistance1Set(languModel, input);
wordsInEditDistance.retainAll(dictionary);
if(wordsInEditDistance.isEmpty()) {
wordsInEditDistance = buildEditDistance2Set(languModel, input);
wordsInEditDistance.retainAll(dictionary);
if (wordsInEditDistance.isEmpty()) {
System.out.println("Failed to check this word!");
continue;
}
}
// 4.计算所以可能的概率
List<String> guessWords = guessRightWord(languModel, wordsInEditDistance);
System.out.printf("Do you want to input %s and Cost time: %.10f second(s)\n",
guessWords.toString(), (System.currentTimeMillis() - startTime) / 1000D);
}
}
/**
* 读取语料库big.txt,构建模型
* @param path
* @return
* @throws IOException
*/
private Map<String, Double> buildLanguageModel(String path) throws IOException {
Map<String, Double> languModel = new HashMap<String, Double>();
BufferedReader reader = new BufferedReader(new FileReader(path));
//去掉文档中除字母外的所有符号
Pattern pattern = Pattern.compile("[a-zA-Z]+");
String line;
int totalCount = 0;
while ((line = reader.readLine()) != null) {
String[] words = line.split(" ");
for(String word : words) {
if(pattern.matcher(word).matches()) {
word = word.toLowerCase();
Double wordCount = languModel.get(word);
if(wordCount == null) {
languModel.put(word, 1D);
} else {
languModel.put(word, wordCount+1D);
}
totalCount++;
}
}
}
reader.close();
for(Entry<String, Double> entry : languModel.entrySet())
entry.setValue(entry.getValue() / totalCount);
return languModel;
}
/**
* 编辑距离为1的单词集合
* @param languModel
* @param input
* @return
*/
private Set<String> buildEditDistance1Set(Map<String, Double> languModel,String input) {
Set<String> wordsInEditDistance = new HashSet<String>();
char[] characters = input.toCharArray();
// 删除:删除一个字母的情况,delete letter[i]
for(int i=0;i<input.length();i++) {
wordsInEditDistance.add(input.substring(0,i) + input.substring(i+1));
}
// 换位: 交换letter[i] and letter[i+1]
for(int i=0;i<input.length()-1;i++) {
wordsInEditDistance.add(input.substring(0,i) + characters[i+1]
+ characters[i] + input.substring(i+2));
}
// 替换: 将 letter[i]替换为a-z
for(int i=0;i<input.length();i++) {
for(char c : alphabets) {
wordsInEditDistance.add(input.substring(0,i) + c + input.substring(i+1));
}
}
// 插入: 插入一个新的字母 a-z
for(int i=0;i<input.length()+1;i++){
for(char c : alphabets) {
wordsInEditDistance.add(input.substring(0,i) + c + input.substring(i));
}
}
return wordsInEditDistance;
}
/**
* 编辑距离为2的集合.通过editDistance1函数得到编辑距离为1的集合,
* 该集合单词再通过editDistance1函数,就可以得到编辑距离为2的集合
* @param languModel
* @param input
* @return
*/
private Set<String> buildEditDistance2Set(Map<String, Double> languModel,String input) {
Set<String> wordsInEditDistance1 = buildEditDistance1Set(languModel, input);
Set<String> wordsInEditDistance2 = new HashSet<String>();
for(String editDistance1 : wordsInEditDistance1) {
wordsInEditDistance2.addAll(buildEditDistance1Set(languModel, input));
}
wordsInEditDistance2.addAll(wordsInEditDistance1);
return wordsInEditDistance2;
}
/**
* 从语料库中获取正确单词
* @param languModel
* @param wordsInEditDistance
* @return
*/
private List<String> guessRightWord(final Map<String, Double> languModel,Set<String> wordsInEditDistance){
List<String> words = new LinkedList<String>(wordsInEditDistance);
//按照单词在字库中出现的频率大小排序,频率越大出现的可能性越大
Collections.sort(words, new Comparator<String>() {
@Override
public int compare(String word1, String word2) {
return languModel.get(word2).compareTo(languModel.get(word1));
}
});
return words.size() > 5 ? words.subList(0, 5) : words;
}
}
七、参考文献
- 贝叶斯公式与拼写检查器
- 词典big.txt
- 拼写纠错功能实现
- 数学之美番外篇:平凡而又神奇的贝叶斯方法
- 书籍:《数学之美》、《统计学习方法》