CVPR 2018 中国论文分享会 之「深度学习」
转自:https://v.douyu.com/show/r90XWgxrlLjvgk25
视频连接:https://v.douyu.com/show/r90XWgxrlLjvgk25
雷锋网(公众号:雷锋网) AI 科技评论按:本文为 2018 年 5 月 11 日在微软亚洲研究院进行的 CVPR 2018 中国论文宣讲研讨会中「Deep Learning」环节的四场论文报告,分别针对Deep Learning的冗余性、可解释性、迁移学习和全局池化做了深入分享。
这些工作多出自大牛组,例如第一个报告的工作来自微软王井东的团队,第二个报告来自张钹、朱军团队,第三个报告有Michael I. Jordan的参与,第四个报告由来自大连理工大学的李培华教授主导。
提要
1、如何降低网络冗余性?
在第一个报告中,微软亚洲研究院的张婷介绍他们通过交错组卷积来解决神经网络基本卷积单元中的冗余问题,在无损性能的前提下缩减模型、提升计算速度的工作,该工作是去年 IGCV1 的延续。(系列工作)
2、如何打开深度学习黑箱?
第二个报告由来自清华大学的苏航介绍了他们在可解释性方面的工作。他们通过在网络层之间加入 control gate (即权值)来显式化每个神经元在模型预测中所起到的作用。
3、什么是部分迁移学习?
随后是由清华大学龙明盛介绍了在迁移学习过程中遇到 source domain 的 label space 大于 target domain 的情况下,如何通过选择部分 label space 进行迁移学习,也即部分迁移学习。
4、线性pooling,岂不浪费资源?
最后由来自大连理工大学的李培华教授介绍他们在重新构造深度学习网络末端全局池化的一系列工作,他们提出使用二阶的全局协方差池化替换目前普遍使用的一阶的全局均值方法,这样能够有效地利用各通道之间的相关信息,而不是舍弃它们。(系列工作)
雷锋网注:
[1] CVPR 2018 中国论文宣讲研讨会由微软亚洲研究院、清华大学媒体与网络技术教育部-微软重点实验室、商汤科技、中国计算机学会计算机视觉专委会、中国图象图形学会视觉大数据专委会合作举办,数十位 CVPR 2018 收录论文的作者在此论坛中分享其最新研究和技术观点。研讨会共包含了 6 个 session(共 22 个报告),1 个论坛,以及 20 多个 posters,AI 科技评论将为您详细报道。
[2] CVPR 2018 将于 6 月 18 - 22 日在美国盐湖城召开。据 CVPR 官网显示,今年大会有超过 3300 篇论文投稿,其中录取 979 篇;相比去年 783 篇论文,今年增长了近 25%。
更多报道请参看:
Session 1:GAN and Synthesis
Session 2: Deep Learning
Session 3: Person Re-Identification and Tracking
Session 4: Vision and Language
Session 5: Segmentation, Detection
Session 6: Human, Face and 3D Shape
1、如何降低网络冗余性?
报告题目:Interleaved Structured Sparse Convolutional Neural Networks
报告人:张婷 - 微软亚洲研究院
论文下载地址:
IGCV 1:Interleaved Group Convolutions for Deep Neural Networks
IGCV 2:Interleaved Structured Sparse Convolutional Neural Networks
代码 1:https://github.com/zlmzju/fusenet(Deep Merge-and-Run Net)
代码 2:https://github.com/hellozting/InterleavedGroupConvolutions(IGC)
雷锋网注:IGC = Interleaved Group Convolutions,交错组卷积
这是一个系列工作,分别为 IGCV 1、IGCV 2、IGCV 3。
神经网络从 2012 年引起人们的广泛关注后,主要沿着两个方向发展。其一是让网络变得更深以提高精度,但随着而来的是对 memory 和计算量的需求变得越来越大;考虑到在实际应用中,更多的应该是用一个小 model 来达到同样的精度,因此第二个研究方向就是减少网络中的冗余性,这主要通过修改神经网络中的卷积(所谓卷积,实际上就是矩阵相乘)来实现。
减少冗余性三种方式。第一种是使用低精度的 kernel,将 kernel 整数化、分层化或者二值化等;第二种是 low-rank kernel,即消除掉 kernel 的部分行或列,例如 filter pruning(减少矩阵的行数)、channel pruning(减少矩阵的列数)等;第三种是采用稀疏 kernel,即选择性地将某些参数置零,可以是非结构性的 sparse 或者结构性的 sparse,现在比较热的 group convolution 事实上可以看做是一中结构性的 sparse。
据张婷介绍,他们的这项工作正是基于 group convolution 而发展起来的,目前有 IGCV1 和 IGCV2 两个版本,分别发表在 ICCV 2017 和 CVPR 2018 上。
1、IGCV 1
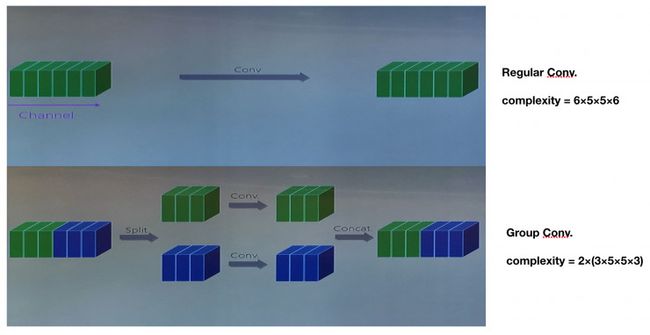
考虑一个传统的卷积,给定输入和输出通道都为 6 个,kernel 为 5×5,那么其 complexity 将为 6×5×5×6。而对于一个分为两组的组卷积,每组有 3 个通道,分别对两组单独做卷积运算,其 complexity 将为 2×(3×5×5×3)。可以看出这样的好处是复杂度降低。
IGCV 1
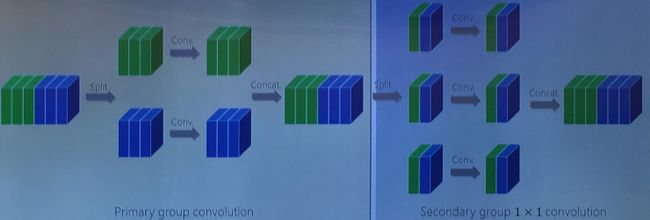
但是由于两组卷积之间不存在交互,不同卷积之间的 features 并不能相互融合起来。为了实现这些 features 之间的融合,张婷团队引入了第二次组卷积,即第二次组卷积过程中,每组的输入通道均来自于第一次组卷积过程不同的组,达到交错互补的目的。其结果在准确率、参数、复杂度上的表现均有提升。
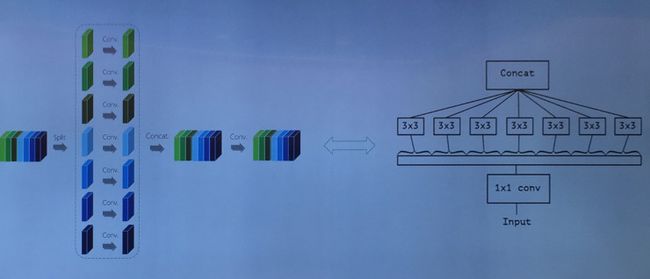
Xception 只是交错组卷积的一种极端特例
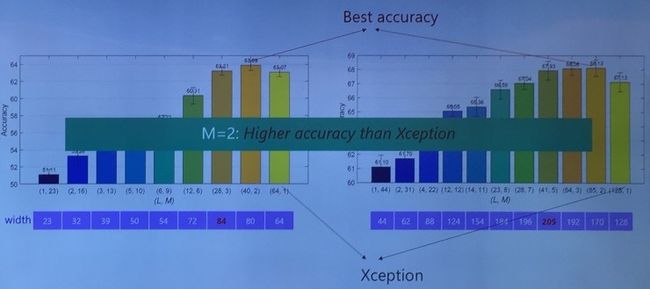
张婷随后提到,谷歌的 Xception 事实上可以看做是交错组卷积的一个极端情况,即第一次组卷积中每组只有一个通道,第二次组卷积为 3×3 的卷积。一个立刻想到的问题就是:在怎样的组卷积分配模式下才能够得到最佳的结果呢?张婷团队针对这个问题也进行了相关的实验,结果发现在第一次组卷积中每组分配两个通道的情况会得到最佳的精度。
2、IGCV 2
在 IGCV 1 的工作,张婷团队验证了两件事情:第一,组卷积能够在保证性能的情况下降低复杂度,减少计算量;第二,组卷积中每组分配两个通道能够达到最佳性能。但是我们看到,在 IGCV 1 的模型中第一次组卷积是只是将所有通道均分成两组,而每一组仍然是一个非常 dense、非常耗时的操作。于是他们用交错组卷积的方式将这部分也进行替换,得到了 IGCV 2。

IGCV 2(这里为了分配,选用了8通道,同时将IGCV 1中的第一次组卷积放到了后面)
将上面这种表示重新整理,可以得到如下的三层交错组卷积的图,其结果仍然能够保证 kernel 矩阵是 dense 的。
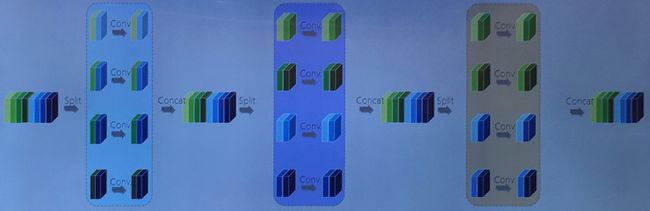
IGCV 2
相比 IGCV 1,其结果有比较明显的提高。
3、IGCV 3
IGCV 2 并不是终结,张婷团队接下来又将 IGCV 2 与 low-rank filters 的方法相结合,即首先用一个 1×1 的 group pointwise covolution 升维,然后进行 3×3 的组卷积,再通过一个 1×1 的 group pointwise covolution 降维。

4、总结
张婷等人通过在卷积中使用交错组卷积(包括加入新的组卷积(IGCV 1)以及替换原有的组卷积(IGCV 2))可以获得一个更快、更小、更准的 model。
参考文献:
[1] MSRA王井东详解ICCV 2017入选论文:通用卷积神经网络交错组卷积
[2] https://arxiv.org/abs/1707.02725
[3] https://arxiv.org/abs/1804.06202
2、如何打开深度学习黑箱?
报告题目:Interpret Neural Networks by Identifying Critical Data Routing Paths
报告人:苏航 - 清华大学
论文下载地址:暂无
当前深度学习的有效性主要是依靠大数据+算力,但是深度学习网络本身对我们来说仍然是一个黑箱。如何解释深度学习网络模型生成的结果成为当前研究的一个热点。
那么什么是「可解释性」呢?这有三个维度,分别为:
-
预测的可解释性,也即为什么会如此分类,多从用户的角度来提问;
-
模型的可解释性,即模型内部是如何达到这样结果,多为开发人员和研究者所关心;
-
数据的可解释性,数据的那个(些)维度真正对任务有作用。
当前的大多数机器学习,特别是以统计为基础的统计学习都是将数据映射到特征空间中来进行学习,但是这里的问题是人并不理解机器的特征学习,人所能理解的一方面是原始的数据空间(与我们的感觉相关),一方面是更高层次的知识空间(与我们的知觉相关)。
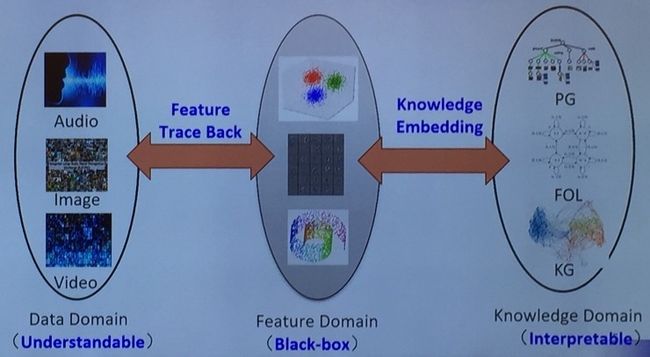
因此,苏航所在团队认为解决机器学习的可解释性可以从两个方向进行,一个是追述到原始的数据空间,另一个则是把低层的特征空间与高层的知识空间相联系。由此他们也进行了两方面的可解释性研究工作,其中后者已经发表在 CVPR 2017 上,而前者发表在 CVPR 2018,也是这次报告的主要内容。
1、思想
当一张图片输入到网络中,将通过多层卷积层的多个神经元,最终输出结果。那么在这个复杂网络中,到底是哪些神经元对最终的 Prediction 起到了最关键的作用呢?
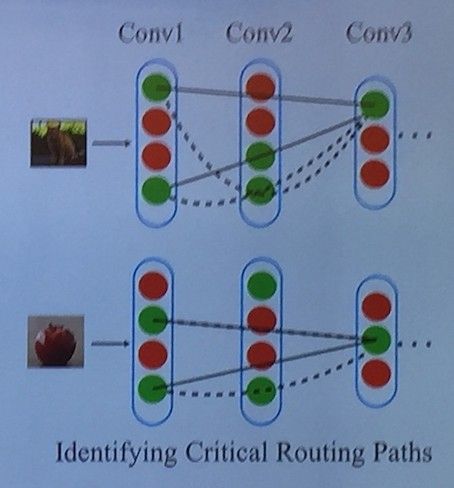
苏航将这些对预测起关键作用的神经元称为 critical nodes,而这些 critical nodes 的数据流传递路径则称为 critical data routing paths。如果将这些 critical nodes 设置为 0,整个网络的预测将显而易见地迅速恶化。
2、方法

相应的方法就是在每一层的输出通道上关联一个标量 λ 作为控制门,传递给下一层的输入是上一层输出结果乘以控制门λ_k 后的结果。这里λ值有两个约束条件:非负性,也即只能增强和抑制输出结果,而不能改变结果的符号;稀疏性,通常具有可分解性质的稀疏模型更易于解释。
通过网络训练(Distillation Guided Pruning,DGP)可以学习出λ的矩阵,该 λ 矩阵元素的大小就决定了相应神经元对预测的重要性。
3、实验
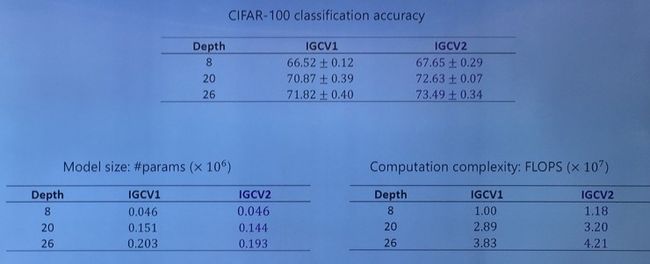
苏航团队首先做了稀疏性验证,如下表所示
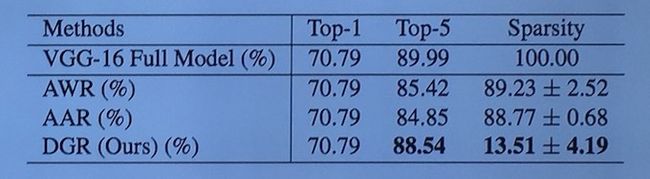
可以看出在准确率不变的情况下,网络的稀疏性大大降低。(注:这里所谓稀疏性是指选择的 critical routing nodes / total nodes)。也即只有百分之十几的神经元在预测中真正起到作用。
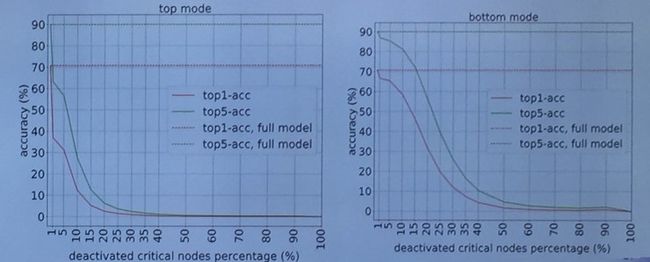
其次,这些 critical nodes 真的如所预期的那样重要吗?苏航团队通过逐步去除 critical nodes 来检验预测的准确率,发现在仅仅去除 1% 的情况下,准确率就从 70% 下降到不足 40%,这也说明了这些 critical nodes 对于预测起到了非常关键的作用。

另外,他们还还将网络不同层的 control gate 进行可视化。他们发现在整个模型中,浅层的 critical nodes 的分布较为分散,而越往深层则相关的 nodes 就越聚集。
4、应用
这种可解释性的方法有一个显而易见的应用,就是对抗样本检测。如下图所示

一个阿尔卑斯山加上噪声后会以 99.9% 的概率预测为一只狗,一个河豚加入噪声后会以 100% 的概率预测为螃蟹。事实上,当在网络浅层加入这些噪声时并不会有太大的影响,而如果是在深层加入这些噪声则会误导(改变)原来的 routing paths,从而转变到别的类别上。
参考资料
[1] 张钹院士:AI科学突破的前夜,教授们应当看到什么?
[2] https://arxiv.org/abs/1703.04096
[3] http://www.xlhu.cn/publications.html
[4] http://www.suhangss.me/publications
3、部分迁移学习是什么?
报告题目:Partial Transfer Learning with Selective Adversarial Networks
报告人:龙明盛 - 清华大学
论文下载地址:Partial Transfer Learning with Selective Adversarial Networks
Code下载地址:http://github.com/thuml
所谓迁移学习,就是在两个具有不同概率分布的 domain 之间进行学习,目前已经是一个非常火热的研究领域。那么什么是部分迁移学习(Partial Transfer Learning)呢?
1、部分迁移学习

简单地说,当做迁移学习时,如果 source domain 中类的数量大于 target domain 中类的数量,那么显而易见的是在 source domain 中那些和 target domain 中类相似的类对于迁移学习来说将起到正向的作用;而那些不在 target domain 中的类将对迁移学习起到负作用。如果能够只用起到正向作用的类进行迁移学习,那么相比用整个 source domain 来做迁移学习效果应该会更好。这即是部分迁移学习的思想。
2、迁移学习的两种方法
目前迁移学习的方法,基本思想就是让 source domain 和 target domain 的数据分布尽量接近。目前则主要有两种方法。
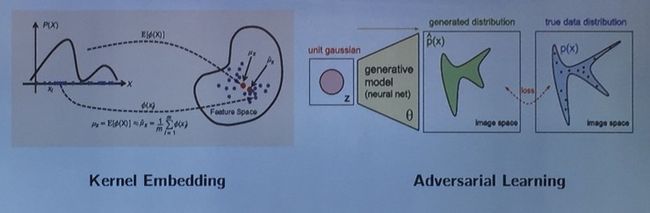
1)Kernel Embedding
一种方法是从统计中延伸过来的,即 Kernel Embedding。这种方法通过定义在两个数据集之间的距离,将这个距离最小化,也即将两个 domain 拉近,此时既可以将 source domain 的模型迁移到 target domain 上。对应的工作是 Song et al. 在 IEEE 2013 的工作[1]。

代表性的工作是龙明盛团队在 ICML 2015 上提出的 Deep Adaptation Network [2]。这篇文章目前的引用率高达 346 次。
2)对抗学习
在 source domain 和 target domain 之间学习一个判别器,如果这个判别器不能将两个 domain 的特征/分布分开,那么这就是一个可以做迁移学习的特征。对应的工作是 Goodfellow et al. 在 NIPS 2014 上的工作[3]。
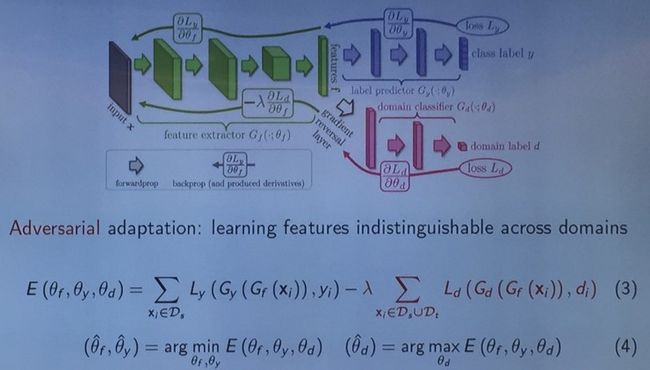
代表性的工作是 Yaroslav Ganin et al. 在 JMLR 2016 上提出的 Domain Adversarial Neural Network(DANN)[4]。这篇文章目前的引用率达 282 次。
3、怎么做部分迁移学习?
以上两种方法都是假设两个 domain 之间的 label space 是一样的。但是加入 source domain 与 target domain 的 label space 并不一样,那么在 Kernel Embedding 的方法中会将所有相关和不相关的 label space 都拉在一起,而在对抗方法中不一致的 label space 也将起到负作用。
基于这样的考虑,龙明盛团队提出了 Selective Adversarial Networks,思想很简单,即在原有的对抗方法基础上,加入一系列能够判别某个类来源的判别器。
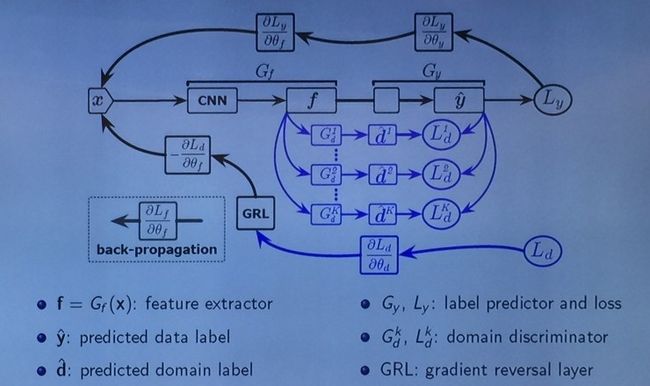
这个网络大的框架与 DANN 类似:输入 x,通过一个 CNN 抽取出 feature;基于这些 feature 可以训练一个 G,对 source domain 进行分类,然后通过对抗来学习让 source domain 和 target domain 分不开的 feature。不同的是 source domain 的 label space 要大于 target domain,因此他们在 source 和 target 之间建立了多个判别器,每个判别器只做一件事情,即判断某各类是来自 source 还是来自 target,由此通过类加权的方式即可以选择出 source domain 中的正样本。这也是该网络取名为选择对抗网络(Selective Adversarial Networks)的原因。判别器具体的构造公式在此不再详细叙述。
4、实验
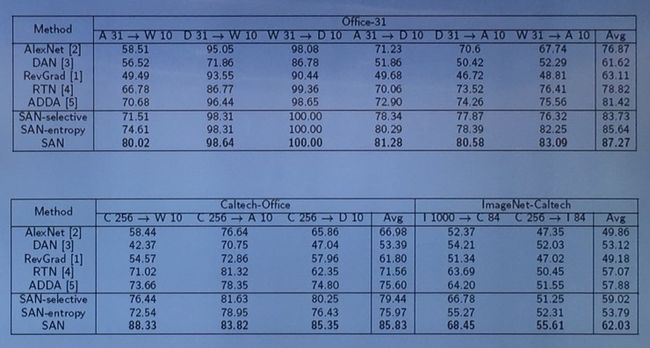
通过以上多种实验结果的对比,可以看出在不同数据集的迁移学习中,部分迁移学习的表现远远优于其他迁移学习方法。
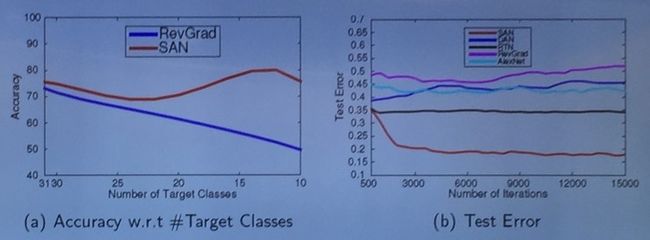
在这一个分析图中,可以看出在 source domain 一定的情况下,target domain 中的类数量越少,选择对抗网络的表现越好,而作为对比基于对抗网络的深度迁移模型 RevGrad 则会随着 target domain 的类数量减少性能逐渐下降。而另一方面,SAN 的误差相比其他模型也要低得多,且在迭代中更快地达到稳定。
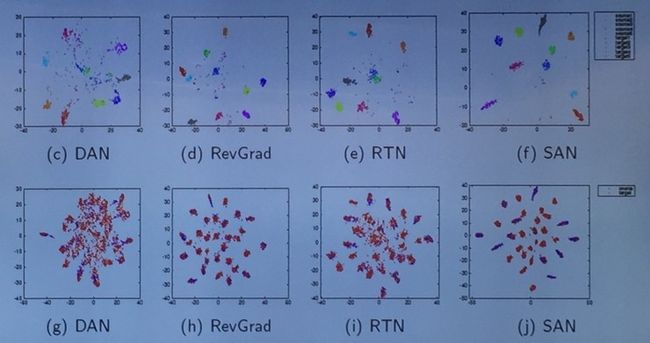
他们也将结果进行了可视化。可以看出 SAN 能够将不同的类清晰地区分开来,source domain 和 target domain 中相似的类别能够有效地聚在一起;作为对比,其他方法中两个 domain 中的类则全部/部分地混杂在一起。
参考资料:
[1] Kernel Embeddings of Conditional Distributions (IEEE 2013)
[2] Learning Transferable Features with Deep Adaptation Networks (ICML 2015)
[3] Generative Adversarial Networks
[4] Domain-Adversarial Training of Neural Networks (JMLR 2016)
[5] 为什么吴恩达认为未来属于迁移学习?
4、线性pooling,岂不浪费资源?
报告题目:Towards Faster Training of Global Covariance Pooling Networks by Iterative Matrix Square Root Normalization
报告人:李培华 - 大连理工大学
论文下载地址:
Towards Faster Training of Global Covariance Pooling Networks by Iterative Matrix Square Root Normalization
Code:https://github.com/jiangtaoxie/iSQRT-COV-ConvNet
这是一个系列工作。
1、动机
深层卷积神经网络在大规模物体分类以及计算机视觉的其他领域中获得了很大的成功,这个网络事实上可以看成是学习和表示的过程,即经过层次化的卷积及 pooling 来学习 local feature,最后会经过一个全局平均池化(Global average pooling)得到一个图像层面的表示,然后送给分类器进行分类。
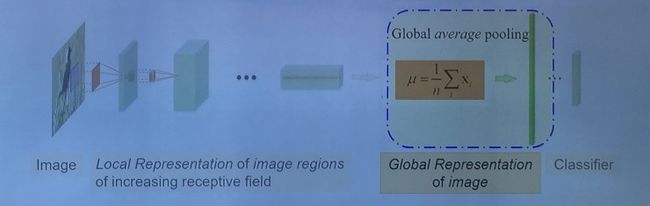
这里关注的重点正是全局平均池化。这层的工作最早是在 ICLR 2014(Min Lin et al.)上提出来的,现在已经广泛地应用于主流的深层网络,例如 Inception、ResNet、DenseNet 等。但是这个全局平均池化的问题在于,前面的网络经过不断地学习得到一个表达能力很强的 feature,但是最后在表示这个图像的时候却做了一个全局的均值,从统计意义上来讲,均值只是一个一阶的信息。学习到的很强的 feature 在临门一脚的时候,我们却只取了一阶的信息,这本身很奇怪:为什么我们不用表达能力更强的表示呢?

基于这样的思考,李培华团队考虑用一个二阶(甚至高阶)的统计方法来替换一阶的全局平均池化,并由此而做出一系列工作,分别发表在 CVPR 2016[1](数学理论的推导和验证)、ICCV 2017 [2](首次在大规模图像识别中使用,性能优异)和 CVPR 2018(迭代计算矩阵平方根,速率得到提升)上。
2、方法
基本的方法很简单,即将一阶的均值换成二阶的协方差。不过这里协方差有一个幂,经验证该幂值取 0.5 时的性能最优,它解决了两个问题:解决了小样本高维度难以统计的问题;有效地利用了协方差矩阵(是一个李群)的几何结构。这方面的理论工作发表在 CVPR 2016 中。
使用二阶协方差的平方根作为全局池化,其优点在于能够利用深度网络学习后的各通道之间的相关信息。而以前的全局平均池化则只是算出了每个通道的均值,而忽略了通道之间的相关信息。在发表在 ICCV 2017 的这篇论文中,他们首次将全局协方差池化的方法应用于大规模视觉识别任务当中,在同样的 50 层圣经网络模型下,使用全局协方差池化,识别率可以提高 2 个百分点。需要注意的是,在这篇文章中,他们求解协方差平方根的方法是将协方差进行本征分解得到本征值,然后求本征值的平方根。

这就存在一个效率的问题了。目前几乎所有基于 GPU 的平台对本征分解的支持都非常差,所以在效率方面非常糟糕。例如使用 Matlab,相比基于 CPU 的平台,基于 GPU 的平台至少慢 5 倍以上。在这次被 CVPR 2018 收录的这篇论文中,李培华团队所解决的正是这样一个问题,即如何提高效率。
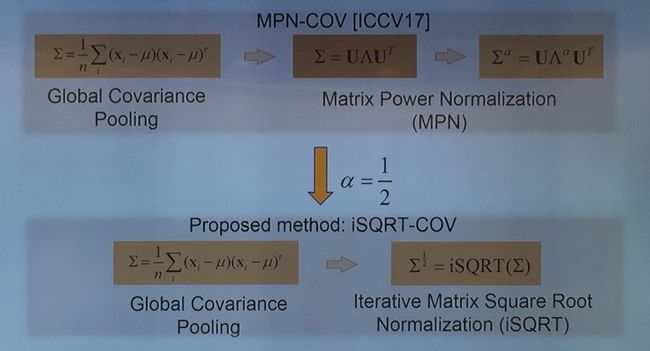
思想方法是:在求协方差的平方根时,不再使用本征分解,而是使用迭代法,称为 iSQRT-COV。迭代法非常适合大规模的 GPU 实现。论文中使用的迭代方法结构如下图所示:
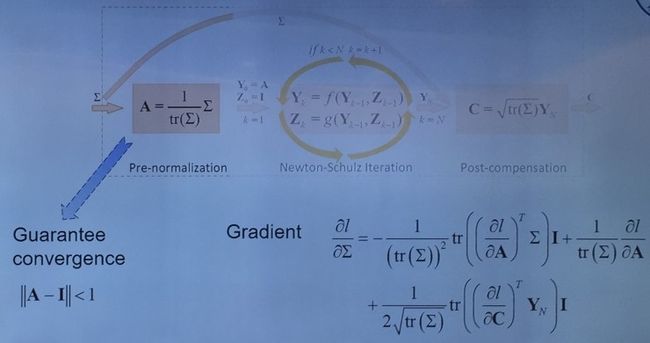
共有三层,分别为 pre-normalization、Newton-Schulz Iteration、Post-compensation。之所以出现 pre-normalization,是因为迭代本身并不是全局收敛,通过协方差矩阵除以矩阵的迹可以保证其收敛性;但是除以迹后改变了协方差的大小,因此在迭代之后通过 Post-compensation 再将迹的值给补偿回来。这两层非常关键,没有这两层迭代根本不会收敛。
其实验表明,这种迭代方法并不需要很多次迭代,5 次足以得到非常好的结果;3 次迭代时性能会有些许下降,但速度会得到提升。
3、实验
李培华团队在 ImageNet 上进行了实验:
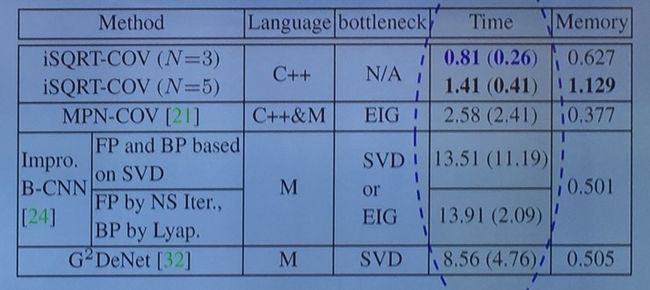
可以看出,1)相比于 ICCV 2017 的工作,在内存上消耗增加了,但速率却得到了提升;2)与其他方法比较内存消耗上基本相同,但速率却提高了一个量级。
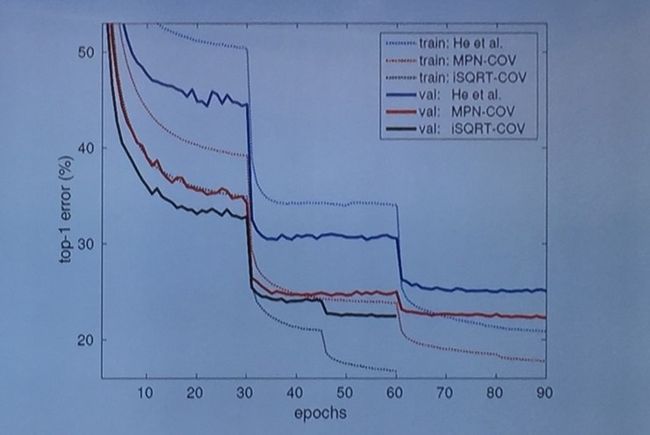

在 ResNet-50 的架构下,iSQRT-COV 网络在不到 50 次迭代下就能得到很好的结果,而其他方法则需要至少 60 次迭代;而性能上没有损失,甚至还有少许提升。
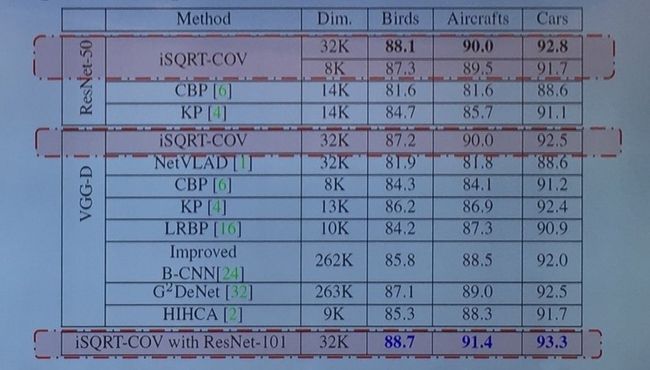
他人也将该方法在小数据集上进行了验证,结果显示性能同样会有很大的提升。
4、结论
在生成的卷积网络里面,全局协方差池化是比全局平均池化更好的一个选择。原因有三:1)性能更好,泛化能力更强;2)在统计学和几何学上有很好的理论解释;3)收敛速度快,计算效率上比较高。
再次强调,这是一个系列工作,除了全局协方差池化的工作外,李培华团队还做了全局高斯池化的工作 [3][4]。
参考资料:
[1] RAID-G: Robust Estimation of Approximate Infinite Dimensional Gaussian with Application to Material Recognition (CVPR 2016)
[2] Is Second-order Information Helpful for Large-scale Visual Recognition?(ICCV 2017)
[3] G2DeNet: Global Gaussian Distribution Embedding Network and Its Application to Visual Recognition(CVPR 2017, oral)
[4] Local Log-Euclidean Multivariate Gaussian Descriptor and Its Application to Image Classification(IEEE TPAMI, 2017)
[5] Towards Faster Training of Global Covariance Pooling Networks by Iterative Matrix Square Root Normalization
相关文章:
CVPR 2018 中国论文分享会之 「GAN 与合成」