【数据库设计】范式基础 第一范式、第二范式、第三范式、BC范式
在写这篇博文之前,我想抛开那些晦涩的官方的定义,用通俗的话来说一下范式,因为我觉得那些苦涩难懂,并且,我们也没有必要将它们完全记住。下面先来简单的看一下范式的描述。
Normal Form前言
在数据库设计的关系模式设计中,缺少范式,经常会使我们的表出现插入异常,删除异常,添加异常和代码冗余。范式的出现正是为了解决这一问题。这是范式作用的通俗解释。
然后我们来看一下范式的定义:符合某一种级别的关系模式的集合,表示一个关系内部各属性之间的联系的合理化程度,总之,范式的出现就是要让我们的关系模式设计更加合理化。
Normal Form的分类
范式的常用的分类有三种:N1(第一范式),N2(第二范式),N3(第三范式),除此之外,还有针对于第三范式进行修正的Boyce-Codd范式(BCNF),以及不怎么常用的N4(第四范式)和N5(第五范式)。
范式的级别都是层层递进的,比如N2就是在N1的基础上而来的,因此,我们知道,满足N2首先你就得满足N1,所以范式的等级并不是层层独立的,每一层都建立在上一层之上。
1.第一范式
第一范式,通俗的讲,就是只要是符合N1的关系,每个属性都不可再分,这是关系设计的基础,比如我们看一张表。

这样的关系模式就不满足N1,因为电话联系方式被分割了。因此,我们只用做稍微的修改就能满足N1。

2.第二范式
再来看看什么是第二范式,第二范式就是说,在满足第一范式的前提下,非主属性不能对主属性有部分依赖。换一种说法,第二范式在第一范式的基础上,撤销了非主属性对主属性的部分依赖。
看一个例子,我们假设有这样一张表
这是一个学生信息的关系表,首先我们必须,明确,在这张表中的主属性有两个:学号和选课名。
而非主属性有四个:姓名,年龄,性别,成绩。
然而,学号->姓名,所以我们说学号对键(学号,选课名)部分依赖,因此我们可以得出这个关系模式并不满足于N2。我们需要将它改进,但是 HOW?
how
我们需要将它改成两张表。改进结果如下:
表1:
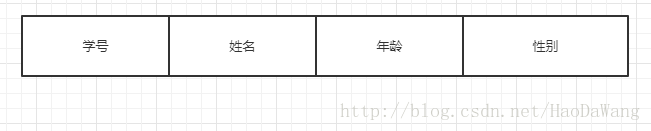
表2:

对于表1,它的键为学号,因为该键只有一个属性,因而,不可能有部分依赖关系,满足N2。
对于表2,它的键为(学号,选课名),然而,学号-/->成绩,选课名-/->成绩,即成绩对键(学号,选课名)没有部分依赖关系。
综上所述,这样是满足N2的。
同时,它也解决了大部分的数据冗余。
3.第三范式
N2固然很好,但是如果我们现在想要记录学生所在系部,以及他的系主任呢?这时候就要求我们添加两个属性到表1,如图所示:

这样看起来依然是满足N2的,对于键学号,因为键只有一个,因此不存在部分函数依赖关系,因此是满足N2的。
不过这样我们还是会有大量的数据冗余。
不仅如此,我们还会面临下面的情况
1.试想一个场景,我们需要清空(重置)一个系所有的学生信息,那么我们顺带系部名称和系主任也被清除了。
2.如果现在我们想要新开一个系,然后面对学生进行招人,我们设定学号为主键,那么系部是不能被新建成功的,因为学号为主键,但是学号又不能为空。
那么该如何解决,这就是N2要面临的问题,于是N3很好的就解决了。
N3是什么?通俗的讲,它去除了非主属性对主属性的传递函数依赖关系。
我们回头看添加完系部名称的那张表,我们发现,尽管所有的非主属性都不对于主属性有部分函数依赖关系,但是系部对学号依赖,而系主任对系部依赖,因此主属性对系部名称有传递依赖关系。N3就是要去除这种关系,于是我们想要再新建一张表。
表一:

表二:
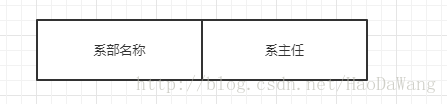
这样设计,既减少了数据冗余,又解决了上述的问题。
现在,我们可以随意清除一个系的学生信息。而不会影响到系部信息。
并且,我们可以新建一个系,然后再进行招人计划。
BCNF
BC范式是针对N3的一个修改,主要是撤销了主属性之间的传递依赖关系和部分依赖关系。
除此之外还有N4和N5,但是因为应用场景很少,这里就不再加以赘述。
总结
对于NF的浅析至此,希望能够帮到大家