机器学习 -- 线性回归(Linear Regression)原理及算法实现
借鉴至:LionKing数据科学专栏
1. 线性回归的原理
假设有一个数据集,希望通过一些特征 x 1 x_{1} x1,…, x p x_{p} xp预测目标变量 y y y.最简单的模型是假设目标变量 y y y 是这些特征的某个线性组合:
y ≈ a 0 + a 1 x 1 + ⋅ ⋅ ⋅ + a p x p y \approx a_{0} + a_{1}x_{1} + \cdot \cdot \cdot +a_{p}x_{p} y≈a0+a1x1+⋅⋅⋅+apxp
记第 i i i 组观测为 ( x 1 ( i ) , . . . , x n i , y i ) (x_{1}^{(i)},..., x_{n}^{i}, y^{i}) (x1(i),...,xni,yi) 。总共有 n n n 组观测。
第 i i i 组观测的预测值为 y ^ ( i ) = a 0 + a 1 x 1 ( i ) + . . . + a p x p ( i ) \widehat{y}^{(i)} = a_{0} + a_{1}x_{1}^{(i)} + ... + a_{p}x_{p}^{(i)} y (i)=a0+a1x1(i)+...+apxp(i)
我们将 a 0 , a 1 , . . . . . , a p a_{0}, a_{1}, ....., a_{p} a0,a1,.....,ap 视为参数, 最小化均方误差(Mean Squared Error):
L ( a 0 , a 1 , . . . . . , a p ) = 1 n [ ( y ( 1 ) − y ^ ( 1 ) ) 2 + . . . + ( y ( n ) − y ^ ( n ) ) 2 ] L(a_{0}, a_{1}, ....., a_{p}) = \frac{1}{n}[(y^{(1)} - \widehat{y}^{(1)})^{2} + ... + (y^{(n)} - \widehat{y}^{(n)})^{2}] L(a0,a1,.....,ap)=n1[(y(1)−y (1))2+...+(y(n)−y (n))2]
2. 算法
假设 x 0 = 1 , x 1 , . . . . . . , x p x_{0} = 1, x_{1}, ......, x_{p} x0=1,x1,......,xp 组成的数据矩阵 X n × ( p + 1 ) X_{n\times (p+1)} Xn×(p+1) 列满秩(full column rank),即秩为 (p+1)。则 X T X X^{T}X XTX 是秩为 (p+1)的方阵,因此可逆。并且最优的参数 ( a 0 , a 1 , . . . . . . , a p ) (a_{0}, a_{1}, ......, a_{p}) (a0,a1,......,ap) 满足正规方程(normal equation):
X T X [ a 0 a 1 . . . a p ] = X T y X^{T}X\begin{bmatrix}a_{0}\\ a_{1}\\ ...\\ a_{p}\end{bmatrix} = X^{T}y XTX⎣⎢⎢⎡a0a1...ap⎦⎥⎥⎤=XTy
因为 X T X X^{T}X XTX 可逆,可以通过求解该线性系统得到待求的参数。当 p p p 过大时,求解线性系统的效率就会很低,因此我们转而使用 梯度下降(Gradient Descent) 近似地估计参数。
3. Python实现
Python中的 scikit-learn 包 可以进行线性回归模型的训练:scikit-learn线性回归模型文档
print(__doc__)
# Code source: Jaques Grobler
# License: BSD 3 clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes = datasets.load_diabetes()
# Use only one feature
diabetes_X = diabetes.data[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(diabetes_y_test, diabetes_y_pred))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))
# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
输出:
Automatically created module for IPython interactive environment
Coefficients:
[938.23786125]
Mean squared error: 2548.07
Variance score: 0.47
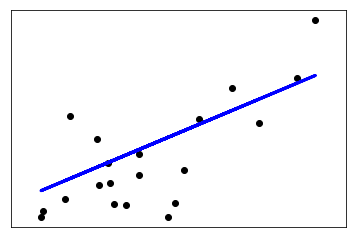
4. 共线性(Collinearity)
当数据矩阵 X n × ( p + 1 ) X_{n\times(p+1)} Xn×(p+1) 不是满秩时,正规方程中的 X T X X^{T}X XTX 不可逆,任何满足正规方程的参数都能够最小化均方误差。满足要求的解有无限多个,因此得出的解容易过拟合(Overfiting)。这个问题又称为数据的共线性。
如果 n ⩽ p n \leqslant p n⩽p ,则数据一定共线性。否则,数据很少精确地满足共线性。即使数据不是精确地满足共线性,也可能会非常接近列不满秩。此时 X T X X^{T}X XTX 虽然可逆,但是数值求解其逆矩阵(Inverse Matrix)非常不稳定,这样得到的不稳定解也容易产生过拟合。
解决共线性的方法主要有两种。第一种是找出共线性的列并且删除其中一列直到数据列满秩。第二种是使用正则化(Regularization)。
5. 岭回归(Ridge Regression),Lasso回归和弹性网络(Elastic Net)回归
对于线性归回,正则化的两种是使用岭回归(Ridge Regression)或Lasso。
岭回归的思想是在原来的均方误差损失函数的基础上加上参数的 l 2 l_{2} l2范数平方作为惩罚项。新的损失函数是:
L λ ( a 0 , a 1 , . . . , a p ) = L ( a 0 , a 1 , . . . , a p ) + λ n [ a 0 2 + a 1 2 + . . . + a p 2 ] L_{\lambda}(a_{0}, a_{1},..., a_{p}) = L(a_{0}, a_{1},...,a_{p}) + \frac{\lambda}{n}[a_{0}^{2} + a_{1}^{2} + ...+ a_{p}^{2}] Lλ(a0,a1,...,ap)=L(a0,a1,...,ap)+nλ[a02+a12+...+ap2]
类似原来的正规方程,新的方程为:
( X T X + λ I p + 1 ) [ a 0 a 1 . . . a p ] = X T y (X^{T}X + \lambda I_{p+1})\begin{bmatrix} a_{0}\\ a_{1}\\ ...\\ a_{p}\end{bmatrix} = X^{T}y (XTX+λIp+1)⎣⎢⎢⎡a0a1...ap⎦⎥⎥⎤=XTy
由于 X T X X^{T}X XTX 一定是半正定(Positive Semi-definite)的,只要 λ > 0 , X T X + λ I p + 1 \lambda > 0, X^{T}X + \lambda I_{p+1} λ>0,XTX+λIp+1 的每一个特征值都不小于 λ \lambda λ,因此 X T X + λ I p + 1 X^{T}X + \lambda I_{p+1} XTX+λIp+1 是正定(Positive Definite)的,进而可逆。岭回归的解存在且唯一。
Lasso的思想是在均方损失误差的基础上加上参数的 l 1 l_{1} l1 范数作为惩罚项。新的损失函数是:
L λ ( a 0 , a 1 , . . . , a p ) + λ n [ ∣ a 0 ∣ + ∣ a 1 ∣ + . . . + ∣ a p ∣ ] L_{\lambda}(a_{0}, a_{1},..., a_{p}) + \frac{\lambda}{n}[|a_{0}| + |a_{1}| + ... + |a_{p}|] Lλ(a0,a1,...,ap)+nλ[∣a0∣+∣a1∣+...+∣ap∣]
Lasso的求解相对于岭回归复杂一些,主流的算法是 Least Angle Regression(LARS).
Lasso倾向于得出稀疏(Sparse)解,岭回归倾向于得出稠密(Dense)解。
弹性网络(Elastic Net)结合了两者,同时使用 l 2 l_{2} l2范数和 l 1 l_{1} l1范数作为惩罚项,其形式如下:
L λ ( a 0 , a 1 , . . . , a p ) = L ( a 0 , a 1 , . . . , a p ) + λ n ( τ ∥ β ∥ 2 2 + ( 1 − τ ) ∥ β ∥ 1 ) L_{\lambda}(a_{0}, a_{1}, ..., a_{p}) = L(a_{0}, a_{1}, ..., a_{p}) + \frac{\lambda}{n}(\tau \left \| \beta \right \|_{2}^{2} + (1 - \tau)\left \| \beta \right \|_{1}) Lλ(a0,a1,...,ap)=L(a0,a1,...,ap)+nλ(τ∥β∥22+(1−τ)∥β∥1)
其中, 0 ⩽ τ ⩽ 1 0 \leqslant \tau \leqslant 1 0⩽τ⩽1 调节两种惩罚的比例,若 τ = 0 \tau = 0 τ=0 ,则弹性网络回归化为Lasso回归;若 τ = 1 \tau = 1 τ=1,则弹性网络回归化为岭回归。
弹性网络回归的好处是即保留了稀疏性,又可以把相关性高的变量同时找出来。
6. 均方误差的概率意义
线性回归采用最小化残差平方和主要有三个原因:第一,数学上残差平方和的解,在数据列满秩的前提下,存在且唯一;第二,平方和的解有显式数学解可以精确求得;第三,最小化残差平方和等价于正态(Gaussian)假设下的最大似然估计(Maximum Likelihood Estimation)。
对于第三点,假设数据来自 y = X β + ε y = X\beta + \varepsilon y=Xβ+ε,其中 ε ∼ N ( 0 , σ 2 ) \varepsilon \sim N(0, \sigma^{2}) ε∼N(0,σ2)。
给定数据 ( X ( 1 ) , y ( 1 ) ) , . . . . . , ( X ( n ) , y ( n ) ) (X^{(1)}, y^{(1)}),.....,(X^{(n)}, y^{(n)}) (X(1),y(1)),.....,(X(n),y(n)),第 i i i 组数据的似然即 y ( i ) − X ( i ) β y^{(i)} - X^{(i)}\beta y(i)−X(i)β 在正态分布中的概率密度:
L i = 1 2 π a e x p [ − ( y ( 2 ) − X ( i ) β ) 2 2 σ 2 ] L_{i} = \frac{1}{\sqrt{2\pi a}}exp[-\frac{(y^{(2)}-X^{(i)}\beta)^{2}}{2 \sigma ^{2}}] Li=2πa1exp[−2σ2(y(2)−X(i)β)2]
总体的似然为 L = L 1 L 2 . . . L n L = L_{1}L_{2}...L_{n} L=L1L2...Ln。最大化似然即最大化每个数据的对数似然(Log Likelihood)之和:
l = l o g L 1 + . . . + l o g L n l = logL_{1} + ... + logL_{n} l=logL1+...+logLn
l o g L i = − l o g ( 2 π σ ) − 1 2 σ 2 ( y ( i ) − X ( i ) β ) 2 logL_{i} = -log(\sqrt{2\pi} \sigma) - \frac{1}{2 \sigma^{2}}(y^{(i)} - X^{(i)}\beta)^{2} logLi=−log(2πσ)−2σ21(y(i)−X(i)β)2
l = − n l o g ( 2 π σ ) − 1 2 σ 2 [ ( y ( 1 ) − y ^ ( 1 ) ) 2 + . . . + ( y ( n ) − y ^ ( n ) ) 2 ] l = -nlog(\sqrt{2 \pi}\sigma) - \frac{1}{2 \sigma^{2}}[(y^{(1)} - \widehat{y}^{(1)})^{2} + ... + (y^{(n)} - \widehat{y}^{(n)})^{2}] l=−nlog(2πσ)−2σ21[(y(1)−y (1))2+...+(y(n)−y (n))2]
因此最大化 l l l 等价最小化 [ ( y ( 1 ) − y ^ ( 1 ) ) 2 + . . . + ( y ( n ) − y ^ ( n ) ) 2 ] [(y^{(1)} - \widehat{y}^{(1)})^{2} + ... + (y^{(n)} - \widehat{y}^{(n)})^{2}] [(y(1)−y (1))2+...+(y(n)−y (n))2], 即残差平方和。
7. 岭回归的概率意义
岭回归从概率意义上可以看作在数据服从高斯噪声假设下,参数的先验分布(Prior Distribution)为以 0 为中心的正态分布。
若假设参数 β \beta β 服从先验分布 N ( 0 → , τ 2 I p + 1 ) N(\overrightarrow{0}, \tau^{2} I_{p+1}) N(0,τ2Ip+1),则 β \beta β 的先验概率为:
p r i o r ( β ) = C e x p − ∥ β ∥ 2 2 2 τ 2 prior(\beta) = Cexp-\frac{\left \| \beta \right \|_{2}^{2}}{2\tau^{2}} prior(β)=Cexp−2τ2∥β∥22
其中 C C C 为只与 p p p 和 τ \tau τ 有关的常数。
根据贝叶斯定理(Bayes’ Theorem),数据的后验似然(Posterior Likelihood)与先验和 L L L 的乘积成正比。
p o s t e r i o r ( β ; X , y ) ∝ p r i o r ( β ) L posterior(\beta; X,y) \propto prior(\beta)L posterior(β;X,y)∝prior(β)L
l o g ( p o s t e r i o r ( β ; X , y ) ) = C − 1 2 τ 2 ∥ β ∥ 2 2 − 1 2 σ 2 [ ( y ( 1 ) − y ^ ( 1 ) ) 2 + . . . + ( y ( n ) − y ^ ( n ) ) 2 ] log(posterior(\beta; X, y)) = C -\frac{1}{2\tau^{2}}\left\| \beta \right\|_{2}^{2} - \frac{1}{2\sigma^{2}}[(y^{(1)} - \widehat{y}^{(1)})^{2} + ... + (y^{(n)} - \widehat{y}^{(n)})^{2}] log(posterior(β;X,y))=C−2τ21∥β∥22−2σ21[(y(1)−y (1))2+...+(y(n)−y (n))2]
最大化后验似然等价于最小化:
[ ( y ( 1 ) − y ^ ( 1 ) ) 2 + . . . + ( y ( n ) − y ^ ( n ) ) 2 ] + σ 2 τ 2 ∥ β ∥ 2 2 [(y^{(1)} - \widehat{y}^{(1)})^{2} + ... + (y^{(n)} - \widehat{y}^{(n)})^{2}] + \frac{\sigma^{2}}{\tau^{2}}\left\| \beta \right\|_{2}^{2} [(y(1)−y (1))2+...+(y(n)−y (n))2]+τ2σ2∥β∥22
取 λ = σ 2 τ 2 \lambda = \frac{\sigma^{2}}{\tau^{2}} λ=τ2σ2,最大化后验似然等价于岭回归的损失函数。
类似地,Lasso 可以视作给参数一个拉普拉斯分布(Laplace Distribution)作为先验。
8. 常见的面试问题
Q:为什么需要正则化?
Q:为什么 l 1 l_{1} l1 更容易给出稀疏解(Sparse Solution)?
Q: R 2 R^{2} R2 是什么?应当如何计算?
Q:共线性应该如何检测?