面试算法题解(一)
一:题目一
题目描述:
对字符串进行RLE压缩,将相邻的相同字符,用计数值和字符值来代替。例如:aaabccccccddeee,则可用3a1b6c2d3e来代替。
输入描述:
输入为a-z,A-Z的字符串,且字符串不为空,如aaabccccccddeee
输出描述:
压缩后的字符串,如3a1b6c2d3e
解决思路:
首先是输入一个字符串,然后转换为字符数组,从第一个字符开始统计,如果和第一个相等就计数,如果不相等就立即追加字符串中,然后从当前不相等的字符开始继续执行for循环.最后进行统计输出.
AC代码如下.
解法一:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner cin=new Scanner(System.in);
String str = cin.nextLine();
StringBuilder builderZip=new StringBuilder();
char[] chars = str.toCharArray();
char c = chars[0];
int count=0;
for(int i=0;i
解法二:(将一个字符串中的相同字符使用空串替代,计算替换后新的字符串长度差,可以计算出所有相同字符的个数了.)
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner cin=new Scanner(System.in);
String str = cin.nextLine();
int length=0;
while(str.length()>0){
String tempStr=String.valueOf(str.charAt(0));
String newStr=str.replaceAll(tempStr, "");
length=str.length()-newStr.length();
str=newStr;
System.out.print(length+""+tempStr);
length=0;
}
}
}
二 :题目二
题目描述:
一个非空整数数组,计算连续子数组的最大和。如果最大的和为正数,则输出这个数;如果最大的和为负数或0,则输出0.
输入描述:
3,-5,7,-2,8
输出描述:
13
解题思路:
动态规划直接解决,连续子数组最大和,注意输入的是一个数组,但是没有指定数组的大小,输入字符串然后进行分割进行转换为数组.
不使用自带的库函数.
就是当前所有的值的和,和接下来的值进行比较如果大于就赋值新的,如果小于那么当前的最大值任然是这个值,继续运算.从后往前计算.
AC代码如下:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner cin=new Scanner(System.in);
String[] strings=cin.nextLine().split(",");
int[] nums=new int[strings.length];
for(int i=0;inums[i]){
fmax=fmax+nums[i];
}else{
fmax=nums[i];
}
if(res0){
return res;
}else{
return 0;
}
}
} 
三:题目三
题目描述:
牛牛有一个由小写字母组成的字符串s,在s中可能有一些字母重复出现。比如在"banana"中,字母'a'和字母'n'分别出现了三次和两次。
但是牛牛不喜欢重复。对于同一个字母,他只想保留第一次出现并删除掉后面出现的字母。请帮助牛牛完成对s的操作
输入描述:
输入包括一个字符串s,s的长度length(1 ≤ length ≤ 1000),s中的每个字符都是小写的英文字母('a' - 'z')
输出描述:
输出一个字符串,表示满足牛牛要求的字符串
示例1
输入
banana
输出
ban
解题思路:
利用HashSet的去重性,先将字符串中的字符全部放入HashSet中,然后再遍历HashSet将存放的字符串存在StringBuilder中即可,但是去除重复字符后要保持原来的顺序的所以使用LinkedHashSet.注意一下
AC代码如下:
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner cin=new Scanner(System.in);
String string=cin.nextLine();
System.out.println(removeRepateStr(string));
}
private static String removeRepateStr(String str){
if(str==null||str==""){
return "";
}
StringBuilder builder=new StringBuilder();
// 存放字符.
LinkedHashSet set=new LinkedHashSet<>();
for(int i=0;i iterator=set.iterator();
while(iterator.hasNext()){
builder.append(iterator.next());
}
return builder.toString();
}
} 
四:题目四
题目描述:
牛牛选择了一个正整数X,然后把它写在黑板上。然后每一天他会擦掉当前数字的最后一位,直到他擦掉所有数位。 在整个过程中,牛牛会把所有在黑板上出现过的数字记录下来,然后求出他们的总和sum.
例如X = 509, 在黑板上出现过的数字依次是509, 50, 5, 他们的和就是564.
牛牛现在给出一个sum,牛牛想让你求出一个正整数X经过上述过程的结果是sum.
输入描述:
输入包括正整数sum(1 ≤ sum ≤ 10^18)
输出描述:
输出一个正整数,即满足条件的X,如果没有这样的X,输出-1。
示例1

解题思路:
首先寻找的这个数是在这个输入数据的范围内的,按照一定的算法查找,给定了start和end,查找是否存在target的数据.不就是二分查找嘛,只是查找的对比条件要计算一下了.
AC代码如下:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner cin=new Scanner(System.in);
long sum=cin.nextLong();
// 二分查找这个数是否存在
System.out.println(binarySearch(0, sum, sum));
}
// 获取一个数每次除以10后的商之和.
private static long getSum(long num){
long sum=0;
while(num!=0){
sum+=num;
num/=10;
}
return sum;
}
// 二分查找
private static long binarySearch(long start, long end, long target){
while(start<=end){
long mid=start+(end-start)/2;
long sum=getSum(mid);
if(sum==target){
return mid;
}
if(sum>target){
end=mid-1;
}
if(sum
五:题目五
题目描述:
数据分页,对于指定的页数和每页的元素个数,返回该页应该显示的数据.
输入描述:
第一行输入数据个数,第二行全部数据,第三行输入页数,第四行输入每页最大数据个数.
输出描述:
输出该页应该显示的数据,超出范围请输出'超过分页范围'.
示例1
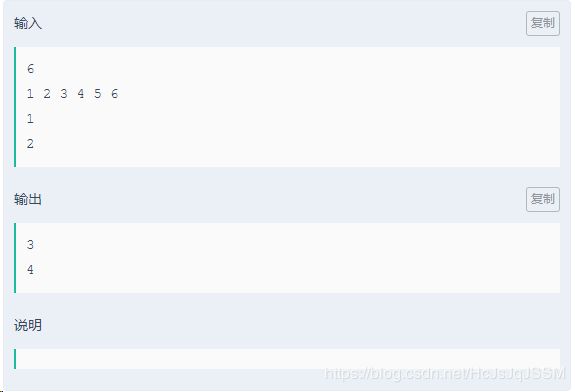
解题思路:
按照题目要求,注意题目中描述的页号是从0开始的,做一下最后一页不满的输出调整.
AC代码如下:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner cin=new Scanner(System.in);
int num=cin.nextInt();
int[] data=new int[num];
for(int i=0;inum){
System.out.println("超出范围");
}else{
calPageShow(num, data, pageNum, pageSize);
}
}
public static void calPageShow(int num, int[] data, int pageNum, int pageSize){
// 计算页数个数
int result=pageNum*pageSize;
// 4,5,6,7
// (1,2,3,4,5,6,7)
// (0,1,2,3,4,5,6)
for(int i=result;i=num-1){
return;
}
}
}
} 
六:题目六
题目描述
在日常书面表达中,我们经常会碰到很长的单词,比如"localization"、"internationalization"等。为了书写方便,我们会将太长的单词进行缩写。这里进行如下定义:
如果一个单词包含的字符个数超过10则我们认为它是一个长单词。所有的长单词都需要进行缩写,缩写的方法是先写下这个单词的首尾字符,然后再在首尾字符中间写上这个单词去掉首尾字符后所包含的字符个数。比如"localization"缩写后得到的是"l10n","internationalization"缩写后得到的是"i18n"。现给出n个单词,将其中的长单词进行缩写,其余的按原样输出。
输入描述:
第一行包含要给整数n。1≤n≤100
接下来n行每行包含一个由小写英文字符构成的字符串,字符串长度不超过100。
输出描述:
按顺序输出处理后的每个单词。
示例1
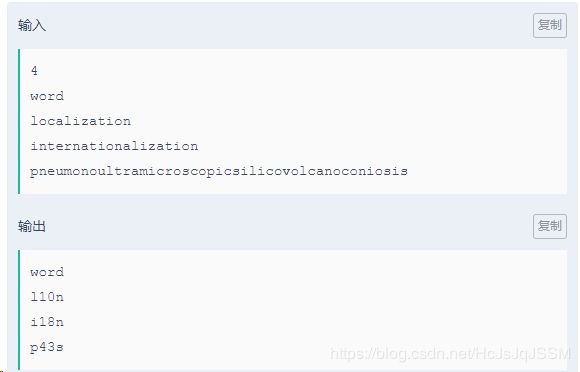
AC代码如下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(reader.readLine());
while ((n--) != 0) {
String word = reader.readLine();
int len = word.length();
if (len < 10){
System.out.println(word);
}
else{
System.out.println(word.charAt(0)
+ String.valueOf(len - 2) + word.charAt(len - 1));
}
}
}
}