论文笔记之---DenseCap:Fully Convolutional Localization Networks for Dense Captioning
Abstract:文中介绍了密集字幕任务,它包含定位及利用自然语言描述定位物体两个主要任务。为了同时解决物体定位和对其进行描述这两个任务,文中提出Fully Convolutional Localization Network,简称FCLN。它由一个卷积网络,一种新的密集定位层,和一个产生标签序列的RNN语言模型组成。
一. 介绍
在过去的几年中, 图像分类已经取得了很大的进展。进一步的研究工作主要沿着两个完全正交的方向进行,其一是在object detection领域模型的发展,其二是在image captioning领域标签复杂度的提升(从固定的分类描述到能表达更丰富内容的序列文字)。
本文将上面提到的两个方向进行了结合从而得到一个统一的框架。文章先介绍dense captioning task,
它要求模型能够描述图片中一系列区域(也就是说不止单个object)
。在这种情况下单一的object detection和image captioning只能被视为其中较为特别的例子。(见Figure1)。
其次,文章的主要贡献在于介绍了一种新的
密集定位层( dense localization layer)
,它完全可微并且可以将其单独插入其他任何图像处理的网络中来达到区域水平的训练和预测。实际上这个定位层预测了图片中的一系列感兴趣的区域(ROI)并使用了双线性插值来较为平滑得提取区域中的激活值。
二. 相关研究工作
Object Detection:介绍了从R-CNN到RPN网络(对anchor box到感兴趣的region做了回归)的发展和不同点,
本文中并没有训练这个途径( training pipeline),并且将ROI pooling 机制替换成了可微的, spatial soft attention机制。
这一改变使得我们可以在RPN网络中使用BP算法,并且对整个网络进行联合训练。
Image Captioning:最早图片描述技术到RNN的变迁。最新则使用soft attention mechanism。
三. 模型
模型结构纵览:(支持单步优化的端对端训练,以及对图片高效和实际的的描述)
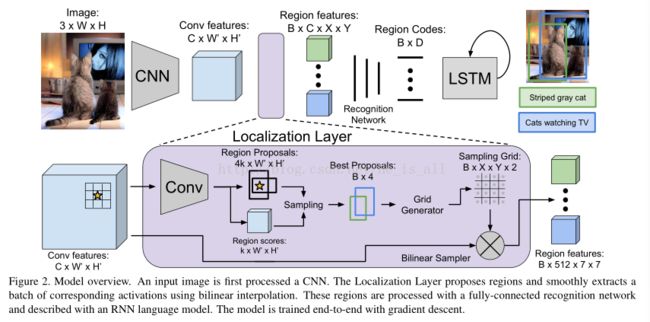
3.1. 模型结构
3.1.1 Convolutional Network
文中使用VGG-16结构。它由13个3×3卷积层和嵌入其中的5个2×2max pooling层组成,文中移除了最后的pooling层,因此如果输入图像是 3×W ×H,那么输出是C×W0 ×H0,W0和H0为原来W和H的16分之一。
3.1.2 Fully Convolutional Localization Layer
localization layer接收到的是有关激活值的输入张量,它能够识别感兴趣的空间区域并且从每一个区域平滑得提取一个固定尺寸的表示。本文基于Faster R-CNN但是用双线性插值代替了 RoI pooling 机制。这一变化的好处在于打开了预测仿射或者变形候选区域的可能性而不仅仅是bounding box。
输入/输出:对于输入的C×W0 ×H0张量,网络选择B个感兴趣的区域,并且对于这些区域给出了三个输出张量,分别是:
区域坐标:一个B×4大小的矩阵。
区域得分:长度为B,给出了每个输出区域的置信度得分。
区域特征:一个B × C × X × Y大小的张量,给出了输出区域的特征。X,Y代表网格大小。
Convolutional Anchors:与 Faster R-CNN类似,定位层也是通过对一系列平移不变的anchors进行回归得到候选区域。过程就是把输入的特征向量,也就是W0 × H0网格中的每一个点映射回W × H的原始图像平面中,并且以该投影点为中心考虑k个不同大小比例的anchor boxes。定位层对每个anchor box的都进行置信度得分和四个标量(scalars)的预测(这四个标量是通过对anchor box到predicted box坐标的回归而得到的)。以上这些结果是通过将特征图送入有着256个3×3滤波器的卷积层,一个ReLU层,以及有着5k个1×1滤波器的卷积层而得到的。所以这个过程最后得到的结果是一个5k × W0 × H0的张量。
Box Regression:采用论文Fast R-CNN论文中的参数来得到anchors到region proposals的回归。输出区域的具体参数计算如下:

(就是利用anchors的中心坐标和它的长宽,以及模型预测出的四个标量来计算输出region的中心和长宽)。
Box Sampling:由于产生的region proposals过多,代价太大,所以要对其进行二次抽样(subsample)。这里采用论文《 Faster r-cnn: Towards real-time object detection with region proposal networks》的方法。(对不同IoU的region进行分类等,另外,与每一个ground-truth region有着最大IoU的预测区域也被视为positive)。
在测试阶段使用NMS算法对候选区域的置信度得分进行选择已得到排名最靠前的300个感兴趣的区域(也就是前文说的B的值)。定位层最后得到的就是包含坐标的B × 4和包含得分的B的两个张量。
Bilinear Interpolation:经过采样过后的region proposals,其大小和比例都是不一样的。考虑到要与全连接层和RNN语言模型相连接,必须要从这些不同大小尺寸的region中提取处固定尺寸的特征表示。
Fast R-CNN所采用的方法提出了RoI pooling层,使每个region proposal都被映射回特征图中,并被与像素边缘对齐的,尺寸大致为 X × Y的网格所分割。随后对每个网格中的特征进行max pooling,最后得到大小为X × Y的输出特征向量。
由于RoI pooling层中梯度无法传到输入的坐标上,所以文中使用了双线性插值来代替。这里面最关键的是引出了sampling grid G,其大小为X × Y × 2把V中的每个元素和U中的实值坐标联系了起来。V是对U的特征进行插值后得到的新的feature map。所以根据U中坐标就可以计算出V中对应元素的值。采样核k表示为:
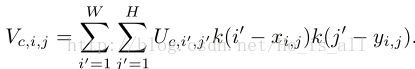
其中:
由于sampling grid是候选区坐标的线性函数,所以梯度就可以被传送回预测的region proposal坐标。对于所有sampled regions,进行双线性插值后得到了大小为B×C×X×Y的张量,而这也是定位层最终的输出形式。
3.1.3 Recognition Network
这一个网络的作用就是将来自定位层的每个region的特征faltten为一个向量并将其传至两个全连接层,这两层都是使用了ReLU单元并且使用了Dropout。每一个region从而能够产生一个维数为D = 4096的code,里面包含了这一个region中的visual appearance。所有positive region的codes被收集到了一个大小为B × D的矩阵中,然后被传送至RNN语言模型。
另外,Recognition Network也可以再次完善每个region proposal的置信度和位置。这两者来自于每个region所对应的D维code的线性变换。最终得到的box regression利用了上文中3.1.2同样的方法。
3.1.4 RNN Language Model
接下去就是利用region codes来适应RNN模型啦。具体就是,给定一个待训练的序列,s1,s2 ... ,sT,RNN中将输入T+2个单词向量,x-1,x0,x1 ... ,xT。RNN最终产生一个向量yt(利用LSTM)。
在测试验证集阶段,我们首先将x-1输入到RNN中。每个时刻采样下一个最有可能的token并且在下一时刻将其送至RNN,这个过程将被不断重复直到END这个token被采样到。
3.2 Loss function
在采样后的positive和negative regions里,对于置信度,文中使用的是binary logistic loss;对于box regression,使用的是平滑L1 loss来变换坐标空间(两个loss都各自被使用两次)在语言模型中每个时刻用的是 cross-entropy 。
所有的损失函数都是通过RNN中的batch size和sequence length来正则化的。对于前四个损失函数,一个合理的weight值为0.1,RNN中的为1.0。
3.3 Training and optimization
我们用预训练ImageNet的权重来初始化CNN,其他权重的取值来源于标准差为0.01的高斯分布。CNN中权重的训练使用了momentum为0.9的SGD,其他的权重使用了Adam算法。CNN的fune-tuning在迭代一轮后就开始了,但是不包含CNN中的前四个卷积层的微调。
四. 实验
Dataset:文中实验所用到的是 Visual Genome(VG)region caption数据集,其中包含了 94313张图片和 4100413个描述片段(平均每张图片43.5个snippets)。图片取自 MS COCO 和YFCC100M,对每个图片中区域的注释是在Amazon Mechanical Turk人工完成的。下面是文中模型在测试图片上的表现:

Preprocessing:对于注释的内容,去掉了类似于“there is...”和“this seems to be a”这一类的 referring phrases。为了效率去除了大于10个单词的注释,另外还有注释个数小于20或者大于50的图片。最终留下的有87398张图, validation sets和test sets各分得5000张图,剩下的全部拿来作为训练集使用。
同时在验证过程中,对 validation和test图片进行预处理,将其中严重重叠的boxes改为一个box,这一个box同时指向多个reference captions。同时对于每张图中预测的boxes也进行不断迭代的选择,将那些重叠率最高的boxes通过取平均值的方式进行融合变为单个box。
4.1 Dense Captioning
在这个阶段中,模型将接收单幅图片并在图片中产生一系列带有置信度和注释的regions。
Evaluation metrics:在一定范围内改变thresholds的值,评估定位和语言模型的mAP。对于localization使用的是IoU阈值,对于语言模型使用METEOR得分阈值。
为了将语言模型的精确度与定位层想分离,文中将真实的注释打包,并将预测的注释与它们进行比较。这样就可以不用考虑空间位置的关系了。
Baseline models:文中使用的是 Region RNN model。为了调查在full images上的训练和regions上的训练,在 MS COCO用同样的模型也进行了训练。
在测试过程中我们考虑region proposals的三个来源:1.在ground truth boxes上建立上限。2.使用 EdgeBoxes为每张测试图片提取300个boxes。3. EdgeBoxes经过微调,得到高的召回率。但是文中使用单独的RPN。
这个实验的结果如下图:
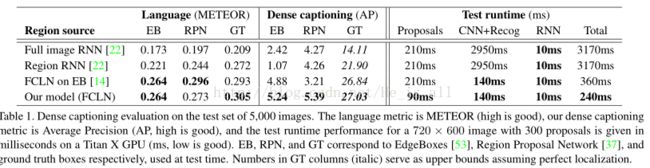
(接下去就讲到了一系列的评估,比如region level和image level数据的区别,RPN比external region proposals更好等等....不一一翻译成中文了,太累了)
4.2 Image Retrieval using Regions and Captions
文中提到的dense captioning模型除了能生成新的描述外,还能够利用自然语言中的提问来支持图片检索。
Experiment setup:从VG模型中随机选择的1000张图片,通过重复的采样得到得到100个test queries,然后希望模型能够根据每个query找到原图。
Evaluation:对于每一个query caption都会对相应的图片和 ground-truth bounding box进行检测。我们在 ground-truth box和 model's predicted grounding之间计算IoU。
Models:仍旧是用4.1的模型,比较了full model和baseline model的ranking表现及localization的表现。具体实验结果如下图:

五.总结
(终于到了总结部分...)
这篇文章介绍了dense captioning 这一任务,它要求一个模型能够同时定位并描述一幅图片的内容。文中利用了FCLN结构来解决这个问题,FCLN主要基于CNN-RNN模型。有别于以前的网络,文中提出了localization layer,最终获得了较好的结果。未来可能会释放 rectangular proposal regions,放弃测试阶段的NMS并用一个可训练的 spatial suppression layer。
(原论文codes:点击打开链接)