Recurrent Convolutional Neural Networks for Text Classification(中文版)
文章目录
- 用于文本分类的递归卷积神经网络
- 摘要
- 介绍
- 相关工作
- 文本分类
- 深度神经网络
- 模型
- 词表示学习
- 文本表示学习
- 训练
- 训练网络参数
- 预训练单词嵌入
- 实验
- 数据集
- 20Newsgroups
- 复旦数据集
- ACL Anthology Network
- Stanford Sentiment Treebank
- 实验设置
- 方法比较
- Bag of Words / Bigrams + LR / SVM
- 平均嵌入+ LR
- LDA
- 树核
- RecursiveNN
- CNN
- 结果与讨论
- 上下文信息
- 学习的关键词
- 结论
用于文本分类的递归卷积神经网络
赖思伟,徐立恒,刘康,赵军模式识别国家实验室(NLPR)
中国科学院自然研究所
摘要
文本分类是许多NLP应用程序中的基础任务。传统的文本分类器通常依赖于许多人为设计的特征,例如字典,知识库和特殊的树内核。与传统方法相比,我们引入了一种用于文本分类的循环卷积神经网络,而没有人为设计的特征。在我们的模型中,我们应用循环结构来在学习单词表示时尽可能地捕获上下文信息,与传统的基于窗口的神经网络相比,这可能会引入相当少的噪声。我们还使用最大池化,自动判断哪些词在文本分类中起关键作用,以捕获文本中的关键组件。我们对四个常用数据集进行了实验。实验结果表明,该方法在几个数据集上优于最先进的方法,特别是在文档级数据集上。
介绍
文本分类是许多应用程序中的重要组成部分,例如网络搜索,信息过滤和情感分析(Aggarwal和Zhai 2012)。因此,它引起了许多研究者的极大关注。
文本分类中的一个关键问题是特征表示,其通常基于词袋(BoW)模型,其中通常将unigrams,bigrams,n-gram或一些精美设计的模式提取为特征。此外,应用几种特征选择方法,例如频率,MI(互信息)(Cover和Thomas 2012),pLSA(Cai和Hofmann 2003),LDA(Hingmire等人,2013),以选择更多的辨别特征。然而,传统的特征表示方法通常忽略文本中的上下文信息或词序,并且仍然不能令人满意地捕获词的语义。例如,在"A sunset stroll along the South Bank affords an array of stunning vantage points."这句话中,当我们分析“Bank”(unigram)这个词时,我们可能不知道它是指金融机构还是旁边的土地。河。此外,“South Bank”(bigram)这一短语,特别是考虑到两个大写字母,可能会误导那些对伦敦不太了解的人将其视为金融机构。在我们获得更大的背景“A sunset stroll along the South Bank”(5-gram)后,我们可以很容易地区分其含义。虽然高阶n-gram和更复杂的特征(例如tree kernels(Postand Bergsma 2013))旨在捕获更多的上下文信息和单词顺序,但它们仍然存在数据稀疏性问题,这严重影响了分类准确性。
最近,预训练词嵌入和深度神经网络的快速发展为各种NLP任务带来了新的灵感。 Word嵌入是单词的分布式表示,可以大大减轻数据稀疏性问题(Bengio et al.2003)。 Mikolov,Yih和Zweig(2013)表明,预训练的单词嵌入可以捕获有意义的句法和语义规律。在单词嵌入的帮助下,提出了一些基于组合的方法来捕获文本的语义表示。
Socher等人(2011a; 2011b; 2013)提出了递归神经网络(RNN),它已被证明在构造句子表示方面是有效的。但是,**RNN通过树结构捕获句子的语义。其性能在很大程度上取决于文本树构造的性能。**此外,构造这样的文本树表现出至少为O(n2)的时间复杂度,其中n是文本的长度。**当模型遇到长句或文档时,这将非常耗时。**此外,两个句子之间的关系很难用树结构来表示。因此,RNN不适合对长句或文档进行建模。
另一个只显示时间复杂度O(n)的模型是递归神经网络(RNN)。该模型逐字分析文本并将所有先前文本的语义存储在固定大小的隐藏层中(Elman 1990)。 RecurrentNN的优点是能够更好地捕获上下文信息。这可能有利于捕获长文本的语义。然而,RecurrentNN是一个有偏见的模型,后面的词比早期的词更占优势。因此,当它用于捕获整个文档的语义时,它可能会降低效率,因为关键组件可能出现在文档中的任何位置而不是最后。
为了解决偏差问题,卷积神经网络(CNN)是一种无偏模型,被引入到NLP任务中,这可以公正地确定具有最大池化层的文本中的判别性短语。因此,与递归或递归神经网络相比,CNN可以更好地捕获文本的语义。 CNN的时间复杂度也是O(n)。然而,先前对CNN的研究倾向于使用简单的卷积核,例如固定窗口(Collobert等人,2011; Kalchbrenner和Blunsom,2013)。当使用这样的内核时,很难确定窗口大小:小窗口可能导致丢失一些关键信息,而大窗户导致巨大的参数空间(可能难以训练)。因此,它提出了一个问题:我们能否比传统的基于窗口的神经网络学习更多的上下文信息,并且更准确地表示文本的语义用于文本分类。
为了解决上述模型的局限性,我们提出了一种递归卷积神经网络(RCNN)
并将其应用于文本分类任务。
- 首先,我们应用双向递归结构,与传统的基于窗口的神经网络相比,可以引入相当少的噪声,以在学习单词表示时最大程度地捕获上下文信息。
- 此外,在学习文本表示时,模型可以保留更大范围的单词排序。
- 其次,我们使用最大池化层来自动判断哪些特征在文本分类中起关键作用,以捕获文本中的关键组件。通过结合递归结构和最大汇集层,我们的模型利用了递归神经模型和卷积神经模型的优势。
- 此外,我们的模型表现出O(n)的时间复杂度,其与文本长度的长度线性相关。
我们将我们的模型与先前使用四种不同类型的英语和中文任务的先进方法进行比较。分类分类包括主题分类,情感分类和写作风格分类。实验表明,我们的模型在四个常用数据集中的三个中优于先前的最先进方法。
相关工作
文本分类
传统的文本分类工作主要集中在三个主题上:特征工程,特征选择和使用不同类型的机器学习算法。
特征工程:对于特征工程,最广泛使用的功能是词袋功能。此外,还设计了一些更复杂的功能,如词性标签,名词短语(Lewis 1992)和树核(Post and Bergsma 2013)。
特征选择:旨在删除噪声特征并提高分类性能。最常见的特征选择方法是删除停用词(例如,“the”)。先进的方法使用信息增益,互信息(Cover和Thomas 2012)或L1正规化(Ng 2004)来选择有用的特征。
机器学习算法:通常使用分类器,例如逻辑回归(LR),朴素贝叶斯(NB)和支持向量机(SVM)。但是,这些方法存在数据稀疏性问题。
深度神经网络
最近,深度神经网络(Hinton和Salakhutdinov2006)和表示学习(Bengio,Courville和Vincent 2013)已经为解决数据稀疏性问题提出了新的思路,并且已经提出了许多用于学习单词表示的神经模型(Bengio et al。 2003; Mnih和Hinton,2007; Mikolov,2012; Collobert等,2011; Huang等,2012; Mikolov等,2013)。单词的神经表示称为单词嵌入,是一种实值矢量。单词嵌入使我们能够通过简单地使用两个嵌入向量之间的距离来测量单词相关性。
通过预先训练的单词嵌入,神经网络在许多NLP任务中展示了它们的出色表现。 Socher等人(2011b)使用半监督递归自动编码器来预测句子的情绪。 Socher等人(2011a)提出了一种递归神经网络的复述检测方法。 Socher等(2013)引入了递归神经张量网络来分析短语和句子的情感。 Mikolov(2012)使用递归神经网络来构建语言模型。 Kalchbrenner和Blunsom(2013)提出了一种新的对话行为分类的经常性网络。 Collobert等人(2011)介绍了用于语义角色标记的卷积神经网络。
模型
我们提出了一个深度神经模型来捕获文本的语义。图1显示了我们模型的网络结构。网络的输入是文档 D D D,它是单词 w i , w 2 . . . w n w_i,w_2 ... w_n wi,w2...wn的序列。网络的输出包含类元素。我们使用 p ( k ∣ D , θ ) p(k|D,\theta) p(k∣D,θ)来表示文档为k类的概率,其中0是网络中的参数。
词表示学习
我们结合一个单词及其上下文来表达一个单词。这些内容有助于我们获得更精确的词义。在我们的模型中,我们使用循环结构(一种双向递归神经网络)来捕捉上下文。
我们将 c l ( w i ) c_l(w_i) cl(wi)定义为单词 w i w_i wi的左上下文, c r ( w i ) c_r(w_i) cr(wi)作为词 w w w的右上下文。 c l ( w i ) c_l(w_i) cl(wi)和 c r ( w i ) c_r(w_i) cr(wi)都是具有 ∣ c ∣ |c| ∣c∣实值元素的密集向量。使用等式(1)计算单词 w i w_i wi的左侧上下文 c l ( w i ) c_l(w_i) cl(wi),其中 e ( w i − 1 ) e\left(w_{i-1}\right) e(wi−1)是单词 w i − 1 w_{i-1} wi−1的单词嵌入,其是具有 ∣ e ∣ |e| ∣e∣实值元素的密集向量。 c l ( w i − 1 ) c_{l}\left(w_{i-1}\right) cl(wi−1)是前一个单词 w i − 1 w_{i-1} wi−1的左侧上下文。任何文档中第一个单词的左侧上下文使用相同的共享参数 c l ( w 1 ) c_{l}\left(w_{1}\right) cl(w1). W ( l ) W^{(l)} W(l)是一个转换为隐藏层(上下文)到下一个隐藏层。 W ( s l ) W^{(s l)} W(sl)是一个矩阵,用于将当前单词的语义与下一个单词的左上下文相结合。 f f f是非线性激活函数。右侧上下文 c r ( w i ) \boldsymbol{c}_{r}\left(w_{i}\right) cr(wi)以类似的方式计算,如等式(2)所示。文档中最后一个单词的右侧上下文共享参数 c r ( w n ) \boldsymbol{c}_{r}\left(w_{n}\right) cr(wn)。
c l ( w i ) = f ( W ( l ) c l ( w i − 1 ) + W ( s l ) e ( w i − 1 ) ) c r ( w i ) = f ( W ( r ) c r ( w i + 1 ) + W ( s r ) e ( w i + 1 ) ) \begin{aligned} c_{l}\left(w_{i}\right) &=f\left(W^{(l)} c_{l}\left(w_{i-1}\right)+W^{(s l)} e\left(w_{i-1}\right)\right) \\ c_{r}\left(w_{i}\right) &=f\left(W^{(r)} c_{r}\left(w_{i+1}\right)+W^{(s r)} e\left(w_{i+1}\right)\right) \end{aligned} cl(wi)cr(wi)=f(W(l)cl(wi−1)+W(sl)e(wi−1))=f(W(r)cr(wi+1)+W(sr)e(wi+1))

图1:循环卷积神经网络的结构。该图是句子"A sunset stroll along the South Bank affords an array of stunning vantage points."的部分例子,下标表示原始句子中相应单词的位置。
如等式(1)和(2)所示,上下文向量捕获所有左侧和右侧上下文的语义。例如,在图1中, c l ( w 7 ) c_{l}\left(w_{7}\right) cl(w7)编码左侧上下文“stroll along the South”的语义以及句子中的所有先前文本, c r ( w 7 ) c_{r}\left(w_{7}\right) cr(w7)编码右侧的语境“提供…”。然后,我们定义单词 w w w的表示;在等式(3)中,其是左侧上下文向量 c l ( w i ) c_{l}\left(w_{i}\right) cl(wi),单词嵌入 e ( w i ) e(w_i) e(wi)和右侧上下文向量 c r ( w i ) c_{r}\left(w_{i}\right) cr(wi)的串联。通过这种方式,使用这种上下文信息,我们的模型可以更好地消除单词 w i w_i wi的含义;与仅使用固定窗口的传统神经模型相比(即,它们仅使用关于文本的部分信息)。
x i = [ c l ( w i ) ; e ( w i ) ; c r ( w i ) ] \boldsymbol{x}_{i}=\left[c_{l}\left(w_{i}\right) ; \boldsymbol{e}\left(w_{i}\right) ; c_{r}\left( w_{i}\right)\right] xi=[cl(wi);e(wi);cr(wi)]
循环结构可以在文本的正向扫描中获得所有 c l c_l cl,并且对文本进行向后扫描。时间复杂度为O(n)。在我们获得表示 x i x_i xi之后;在 w i w_i wi这个词中,我们将tanh激活函数与 x i x_i xi一起应用于线性变换;并将结果发送到下一层。
y i ( 2 ) = tanh ( W ( 2 ) x i + b ( 2 ) ) \boldsymbol{y}_{i}^{(2)}=\tanh \left(W^{(2)} \boldsymbol{x}_{i}+\boldsymbol{b}^{(2)}\right) yi(2)=tanh(W(2)xi+b(2))
y i ( 2 ) \boldsymbol{y}_{i}^{(2)} yi(2)是一个潜在的语义向量,其中将分析每个语义因素以确定表示文本的最有用的因素。
文本表示学习
我们模型中的卷积神经网络旨在表示文本。从卷积神经网络的角度来看,我们前面提到的循环结构是卷积层。当计算所有单词的表示时,我们应用最大池化层。
y ( 3 ) = max i = 1 y i ( 2 ) \boldsymbol{y}^{(3)}=\max _{i=1} \boldsymbol{y}_{i}^{(2)} y(3)=i=1maxyi(2)
max函数是一个逐元素的函数。 y ( 3 ) y^{(3)} y(3)的第k个元素是 y ( 2 ) y^{(2)} y(2)的第k个元素中的最大元素。池化层将具有不同长度的文本转换为固定长度的向量。通过池化层,我们可以捕获整个文本中的信息。还有其他类型的池化层,例如平均池化层(Collobert et al.2011)。我们这里不使用平均池化,因为只有几个单词及其组合对于捕获文档的含义很有用。 最大池化层试图在文档中找到最重要的潜在语义因素。池化层利用循环结构的输出作为输入。池化层的时间复杂度为O(n)。整个模型是循环结构和最大池层的级联,因此,我们模型的时间复杂度仍然是O(n)。我们模型的最后一部分是输出层。与传统的神经网络类似,它被定义为
y ( 4 ) = W ( 4 ) y ( 3 ) + b ( 4 ) \boldsymbol{y}^{(4)}=W^{(4)} \boldsymbol{y}^{(3)}+\boldsymbol{b}^{(4)} y(4)=W(4)y(3)+b(4)
最后,softmax函数应用于 y ( 4 ) y^{(4)} y(4)。它可以将输出数转换为概率。
p i = exp ( y i ( 4 ) ) ∑ k = 1 n exp ( y k ( 4 ) ) p_{i}=\frac{\exp \left(\boldsymbol{y}_{i}^{(4)}\right)}{\sum_{k=1}^{n} \exp \left(\boldsymbol{y}_{k}^{(4)}\right)} pi=∑k=1nexp(yk(4))exp(yi(4))
训练
训练网络参数
我们将所有要训练的参数定义为 θ \theta θ。
θ = { E , b ( 2 ) , b ( 4 ) , c l ( w 1 ) , c r ( w n ) , W ( 2 ) W ( 4 ) , W ( l ) , W ( r ) , W ( s l ) , W ( s r ) } \begin{array}{c}{\theta=\left\{E, \boldsymbol{b}^{(2)}, \boldsymbol{b}^{(4)}, \boldsymbol{c}_{l}\left(w_{1}\right), \boldsymbol{c}_{r}\left(w_{n}\right), W^{(2)}\right.} \\ {W^{(4)}, W^{(l)}, W^{(r)}, W^{(s l)}, W^{(s r)} \}}\end{array} θ={E,b(2),b(4),cl(w1),cr(wn),W(2)W(4),W(l),W(r),W(sl),W(sr)}
具体来说,参数是字嵌入 E ∈ R ∣ e ∣ × ∣ V ∣ E \in \mathbb{R}|\boldsymbol{e}| \times|V| E∈R∣e∣×∣V∣,偏置矢量 b ( 2 ) ∈ R H , b ( 4 ) ∈ R O \boldsymbol{b}^{(2)} \in \mathbb{R}^{H}, \boldsymbol{b}^{(4)} \in \mathbb{R}^{O} b(2)∈RH,b(4)∈RO,初始内容 c l ( w 1 ) , c r ( w n ) ∈ R ∣ c ∣ c_{l}\left(w_{1}\right), c_{r}\left(w_{n}\right) \in \mathbb{R}^{|c|} cl(w1),cr(wn)∈R∣c∣和变换矩阵 W ( 2 ) ∈ R H × ( ∣ e ∣ + 2 ∣ c ∣ ) , W ( 4 ) ∈ R O × H , W ( l ) , W ( r ) ∈ R ∣ c ∣ × ∣ c ∣ , W ( s l ) , W ( s r ) ∈ R ∣ e ∣ × ∣ c ∣ W^{(2)} \in \mathbb{R}^{H \times(|e|+2|c|)}, W^{(4)} \in \mathbb{R}^{O \times H}, W^{(l)}, W^{(r)} \in \mathbb{R}^{|\mathbf{c}| \times|\boldsymbol{c}|}, W^{(s l)}, W^{(s r)} \in \mathbb{R}^{|\boldsymbol{e}| \times|\mathbf{c}|} W(2)∈RH×(∣e∣+2∣c∣),W(4)∈RO×H,W(l),W(r)∈R∣c∣×∣c∣,W(sl),W(sr)∈R∣e∣×∣c∣其中 ∣ V ∣ |V| ∣V∣是词汇表中的单词数, H H H是隐藏层大小, O O O是文档类型的数量。
网络的训练目标使用 θ \theta θ的最大似然对数
θ ↦ ∑ D ∈ D log p ( class D ∣ D , θ ) \theta \mapsto \sum_{D \in \mathbb{D}} \log p\left(\operatorname{class}_{D} | D, \theta\right) θ↦D∈D∑logp(classD∣D,θ)
其中 D \mathbb{D} D是训练文档集,class D _{D} D是正确的文档类 D D D.我们使用随机梯度下降(Bottou 1991)来优化训练目标。在每个步骤中,我们随机选择一个示例 ( D , class D ) \left(D, \text {class}_{D}\right) (D,classD)并进行渐变步骤。
θ ← θ + α ∂ log p ( class D ∣ D , θ ) ∂ θ \theta \leftarrow \theta+\alpha \frac{\partial \log p\left(\operatorname{class}_{D} | D, \theta\right)}{\partial \theta} θ←θ+α∂θ∂logp(classD∣D,θ)
其中 α \alpha α是学习率。
我们使用一种在训练阶段训练具有随机梯度下降的神经网络时广泛使用的技巧。我们从均匀分布初始化神经网络中的所有参数。最大值或最小值的大小等于“扇入”的平方根(Plaut和Hinton 1987)。该数字是我们模型中前一层的网络节点。该层的学习率除以“扇入”。
预训练单词嵌入
单词嵌入是单词的分布式表示。分布式表示适用于神经网络的输入。传统的表征,例如一个one-hot的表征,将导致维度的灾难(Bengio et al.2003)。最近的研究(Hinton和Salakhutdinov,2006; Erhan等,2010)表明神经网络可以通过合适的无监督预定程序收敛到更好的局部最小值。
在这项工作中,我们使用Skip-gram模型来预防单词嵌入。这个模型是许多NLP任务中最先进的(Baroni,Dinu和Kruszewski 2014)。 Skipgram模型训练单词 w 1 , w 2 ⋯ ⋅ w T w_{1}, w_{2} \dots \cdot w_{T} w1,w2⋯⋅wT嵌入。通过最大化平均对数概率
1 T ∑ t = 1 T ∑ − c ≤ j ≤ c , j ≠ 0 log p ( w t + j ∣ w t ) \frac{1}{T} \sum_{t=1}^{T} \sum_{-c \leq j \leq c, j \neq 0} \log p\left(w_{t+j} | w_{t}\right) T1t=1∑T−c≤j≤c,j̸=0∑logp(wt+j∣wt)
p ( w b ∣ w a ) = exp ( e ′ ( w b ) T e ( w a ) ) ∑ k = 1 ∣ V ∣ exp ( e ′ ( w k ) T e ( w a ) ) p\left(w_{b} | w_{a}\right)=\frac{\exp \left(e^{\prime}\left(w_{b}\right)^{T} e\left(w_{a}\right)\right)}{\sum_{k=1}^{|V|} \exp \left(e^{\prime}\left(w_{k}\right)^{T} e\left(w_{a}\right)\right)} p(wb∣wa)=∑k=1∣V∣exp(e′(wk)Te(wa))exp(e′(wb)Te(wa))
其中 ∣ V ∣ |V| ∣V∣是未标记文本的词汇. e ′ ( w i ) e^{\prime}\left(w_{i}\right) e′(wi)是 w i w_{i} wi的另一个嵌入。我们使用嵌入 e e e,因为这里将使用一些加速方法(例如,分层softmax(Morin和Bengio 2005)),并且在实践中不计算 e ′ e^{\prime} e′。
实验
数据集
为了证明所提方法的有效性,我们使用以下四个数据集进行实验:20 News groups,Fudan Set,ACL Anthology Network和Sentiment Treebank。表1提供了有关每个数据集的详细信息。

表1:数据集的摘要,包括类的数量,列车/开发/测试集条目的数量,平均文本长度和数据集的语言。
20Newsgroups
该数据集包含来自20个新闻组的消息。我们使用bydate版本并选择四个主要类别(comp,polit,rec和religion),然后是Hingmire等人(2013)。
复旦数据集
复旦大学文献分类集是一个中文文献分类集,由20个类组成,包括艺术,教育和能源。
ACL Anthology Network
此数据集包含ACL和相关组织发布的科学文档。它由Post和Bergsma(2013)注释,作者有五种最常见的母语:英语,日语,德语,中文和法语。
Stanford Sentiment Treebank
该数据集包含由Socher等人(2013)解析和标记的电影评论。
标签为非常消极,负面,中性,正面和非常正面。
实验设置
我们按如下方式预处理数据集。
对于英文文档,我们使用Stanford Tokenizer来获取令牌。
对于中文文档,我们使用ICTCLAS来分割单词。
我们不会删除文本中的任何停用词或符号。之前已将所有四个数据集分为训练集和测试集。 ACL和SST数据集具有预定义的培训,开发和测试分离。
对于其他两个数据集,我们将10%的训练集分成一个开发集,并将剩余的90%作为真实的训练集。
20Newsgroups的评估指标是Macro-F1测量,然后是最先进的工作。其他三个数据集使用精度作为度量。
神经网络的超参数设置可以取决于所使用的数据集。我们在之前的研究中选择了一组常用的超参数(Collobert et al.2011; Turian,Ratinov,and Bengio 2010)。此外,我们将随机梯度下降的学习率设置为0.01,隐藏层大小为 H = 100 H = 100 H=100,单词嵌入的向量大小为 ∣ e ∣ = 50 |e| = 50 ∣e∣=50,上下文向量的大小为 ∣ c ∣ = 50 |c| = 50 ∣c∣=50。我们使用Skip-gram算法使用word2vec中的默认参数训练单词嵌 入。我们使用英文和中文的维基百科转储来训练嵌入一词。
方法比较
我们将我们的方法与广泛使用的文本分类方法和每个数据集的最新方法进行比较。
Bag of Words / Bigrams + LR / SVM
Wang和Manning(2012)提出了几个强大的文本分类基线。这些基线主要使用具有unigram和bigrams作为特征的机器学习算法。我们分别使用逻辑回归(LR)和SVM8。每个特征的权重是术语频率。

表2:数据集的测试集结果。顶部,中部和底部分别是基线,最先进的结果和我们模型的结果。相应的论文报道了最先进的结果。
平均嵌入+ LR
此基线使用单词嵌入的加权平均值,然后应用softmax图层。每个单词的权重是其tfidf值。 Huang等人(2012)也将这一策略作为其任务的全球背景。 Klementiev,Titov和Bhattarai(2012)在跨语文档分类中使用了它。
LDA
基于LDA的方法在捕获若干分类任务中的文本的语义方面实现了良好的性能。我们选择两种方法作为比较方法:ClassifyLDA-EM(Hingmire等人,2013)和Labeled-LDA(Li,Sun和Zhang,2008)。
树核
Post和Bergsma(2013)使用各种树内核作为特征。它是ACL本机语言分类任务中最先进的工作。我们列出了两种主要的比较方法:Berkeley解析器(Petrov et al.2006)生成的无上下文语法(CFG)和Charniak and Johnson(2005)(C&J)的重新排序特征集。
RecursiveNN
我们选择两种基于递归的方法与所提出的方法进行比较:递归神经网络(RecursiveNN)(Socher等人,2011)及其改进版本,递归神经张量网络(RNTNs)(Socher等人,2013)。
CNN
我们还选择卷积神经网络(Collobert et al.2011)进行比较。它的卷积内核简单地将嵌入字连接在预定义的窗口中。从形式上看,
x i = [ e ( w i − ⌊ w i n / 2 ⌋ ) ; ∣ … ; e ( w i ) ; … ; e ( w i + ⌊ w i n / 2 ⌋ ) ] x_{i}=\left[e\left(w_{i-\lfloor w i n / 2\rfloor}\right) ; | \ldots ; e\left(w_{i}\right) ; \ldots ; e\left(w_{i+\lfloor w i n / 2\rfloor}\right)\right] xi=[e(wi−⌊win/2⌋);∣…;e(wi);…;e(wi+⌊win/2⌋)]
结果与讨论
实验结果如表2所示。
- 当我们将神经网络方法(RNN,CNN和RCNN)与广泛使用的传统方法(例如,BoW + LR)进行比较时,实验结果表明神经网络方法优于所有四个数据集的传统方法。它证明了基于神经网络的方法可以有效地组成文本的语义表示。与基于BoW模型的传统方法相比,神经网络可以捕获更多的特征上下文信息,并且可能较少受到数据稀疏性问题的影响。
- 当使用SST数据集将CNN和RCNN与RNN进行比较时,我们可以看到基于卷积的方法可以获得更好的结果。这说明与基于先前的神经网络相比,基于卷积的框架更适合于构建文本的语义表示。我们认为主要原因是CNN可以通过最大池化层选择更多的判别特征,并通过卷积层捕获上下文信息。相比之下,RNN只能在构造的文本树下使用语义合成来捕获上下文信息,这在很大程度上取决于树构造的性能。此外,与需要O(n2)时间来构造句子表示的基于递归的方法相比,我们的模型表现出较低的O(n)时间复杂度。实际上,Socher等人(2013年)报告的RNTN训练时间约为3-5小时。使用单线程机器在SST数据集上训练RCNN只需几分钟。
在所有数据集中,期望ACL和SST数据集,RCNN优于最先进的方法。在ACL数据集中,RCNN具有最佳基线的竞争结果。对于20News数据集,我们将错误率降低了33%,对于具有最佳基线的复旦集,错误率降低了19%。结果证明了该方法的有效性。 - 我们将RCNN与ACL数据集中精心设计的特征集进行比较。实验结果表明,RCNN优于CFG特征集,并获得了与C&J特征集竞争的结果。我们相信RCNN可以捕获长距离模式,这些模式也是由树内核引入的。尽管有竞争力的结果,RCNN不需要手工制作的功能集,这意味着它可能在低资源语言中有用。
- 我们还将RCNN与CNN进行比较,发现RCNN在所有情况下均优于CNN。我们认为原因是RCNN中的循环结构比CNN中的基于窗口的结构更好地捕获上下文信息。该结果证明了所提出方法的有效性。为了更清楚地说明这一点,我们在下一小节中提出了详细的分析。
上下文信息
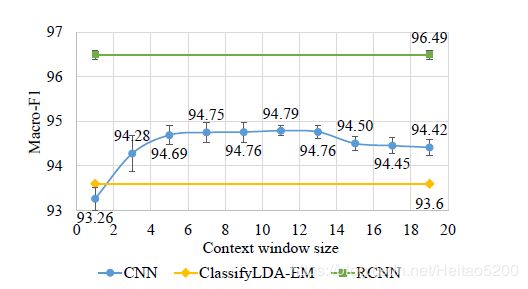
图2:上下文窗口大小如何影响20Newsgroups分类性能的Macro-F1曲线
在这一小节中,我们研究了模型中循环结构更详细地捕获上下文信息的能力。 CNN和RCNN之间的区别在于它们使用不同结构来捕获上下文信息。 CNN使用固定的单词窗口作为上下文信息,而RCNN使用循环结构来捕获大范围的上下文信息。 CNN的性能受窗口大小的影响。小窗口可能导致一些长距离模式的丢失,而大窗口将导致数据稀疏性。此外,大量参数更难训练。
我们考虑从1到19的所有奇数窗口大小来训练和测试CNN模型。例如,当窗口大小为1时,CNN仅使用单词嵌入 [ e ( w i ) ] \left[e\left(w_{i}\right)\right] [e(wi)]来表示单词。当窗口大小为3时,CNN使用 [ e ( w i − 1 ) ; e ( w i ) ; e ( w i + 1 ) ] \left[e\left(w_{i-1}\right) ; e\left(w_{i}\right) ; e\left(w_{i+1}\right)\right] [e(wi−1);e(wi);e(wi+1)]表示单词 w i w_{i} wi。这些不同窗口大小的测试分数如图2所示。由于篇幅限制,我们只显示20Newsgroups数据集的分类结果。在此图中,我们可以观察到RCNN在所有窗口大小方面都优于CNN。它说明了RCNN可以捕获具有不依赖于窗口大小的循环结构的上下文信息。 RCNN优于基于窗口的CNN,因为循环结构可以保留更长的上下文信息并且引入更少的噪声。
学习的关键词

表3:RCNN和RNTN提取的正面和负面特征的比较
为了研究我们的模型如何构建文本的表示,我们列出了表3中测试集中最重要的单词。最重要的单词是最大池化层中最常选择的信息。因为我们模型中的单词表示是一个单词及其上下文,所以上下文可能包含整个文本。我们只呈现中心词及其相邻的三元组。为了便于比较,我们也列出了由RNTN提取的最正/负卦短语(Socher等al.2013)。
与此相反,以在RNTN最积极和最负短语,我们的模型不依赖于句法分析器,有脱颖而出所提出的n-gram通常不是“短语”。结果表明,积极情绪中最重要的词是“值得”,“最甜蜜”和“精彩”等词,负面情绪词则是“极其地”,“糟糕”,“无聊”。
结论
我们将循环卷积神经网络引入文本分类。我们的模型利用循环结构捕获上下文信息,并使用卷积神经网络构造文本表示。实验表明我们的模型使用四种不同的文本分类数据集优于CNN和RNN。