hadoop 完全分布式部署(linux) 超详细版
概述:
利用多台Linux主机来进行部署Hadoop,对Linux机器集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上。
新建一个虚拟机hadoop1为主站,分别克隆两个名为hadoop2和hadoop3的从站。
centOS 7 安装 :https://blog.csdn.net/Henry_Lin_Wind/article/details/80876494
| Hostname | IP |
| hadoop1 | 192.168.100.10 |
| hadoop2 | 192.168.100.11 |
| hadoop3 | 192.168.100.12 |
服务器功能规划:分别在3台主机上安装不同的功能
| hadoop1 | hadoop2 | hadoop3 |
|---|---|---|
| NameNode | ResourceManage | |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| HistoryServer | SecondaryNameNode |
安装步骤:1、安装虚拟机,设置网络
2、在主站上安装好java和hadoop,
3、关闭防火墙 systemctl stop firewalld
4、配置core-site.xml、hdfs-site.xml、slaves、yarn-site.xml、mapred-site.xml
5、分别在三台主机上设置SSH无密码登录
6、分发主站的hadoop和java到两个从站上
7:启动集群,查看三台主机的进程。
验证:在hadoop1上运行namenode,在hadoop2上运行yarn,在hadoop3上运行SecondaryNameNode。通过测试一个例子,分别在三个主机上查看
完全分布式安装
1、设置虚拟机网络
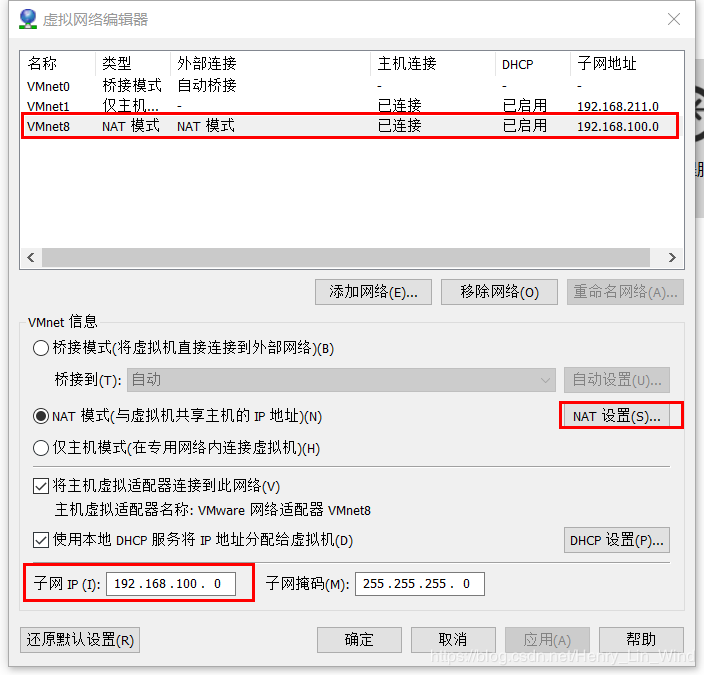
新增NAT模式,修改子网IP为192.168.100.0
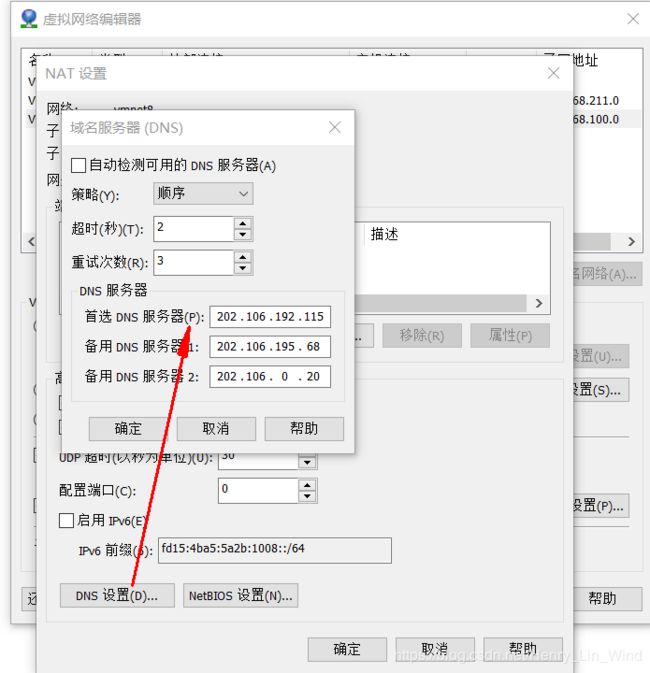
修改NAT设置
2、安装Linux系统 hadoop1,安装完成后右击克隆两个作为从站的主机
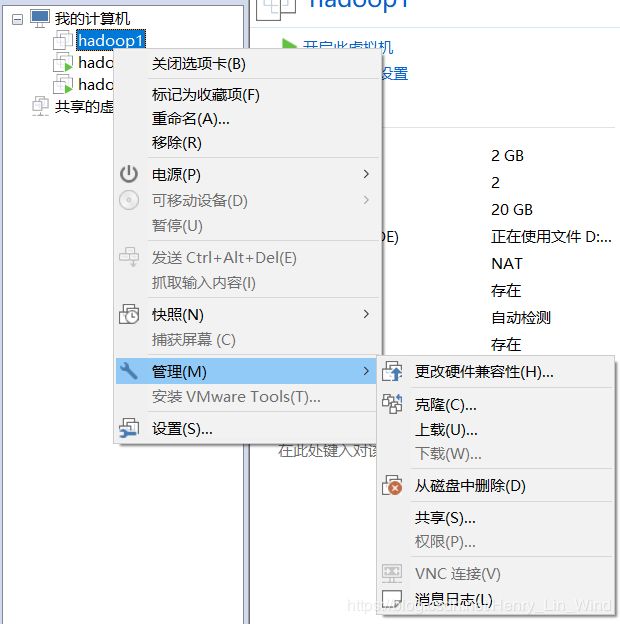
修改两个从站的IP和hostname,具体参考概述的表格。
配置hosts:
sudo vim /etc/hosts三台机器hosts都配置为: 设置完成后可以ping一下来测试三个主机之间是否可以连接。
192.168.100.10 hadoop1
192.168.100.11 hadoop2
192.168.100.12 hadoop3
3、在主站安装Java 和 Hadoop (主站配置好后,通过分发复制到其他从站)
安装步骤可以参考我的其他篇博客,配置如下。
JAVA_HOME=/usr/local/jdk1.8.0_171
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
HADOOP_HOME=/usr/local/hadoop-2.9.2
PATH=$JAVA_HOME/bin:$PATH/bin:$HADOOP_HOME/bin
export JAVA_HOME CLASSPATH PATH HADOOP_HOME
验证验证是否成功:
[root@hadoop1 hadoop-2.9.2]# java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
[root@hadoop1 hadoop-2.9.2]# hadoop version
Hadoop 2.9.2
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 826afbeae31ca687bc2f8471dc841b66ed2c6704
Compiled by ajisaka on 2018-11-13T12:42Z
Compiled with protoc 2.5.0
From source with checksum 3a9939967262218aa556c684d107985
This command was run using /usr/local/hadoop-2.9.2/share/hadoop/common/hadoop-common-2.9.2.jar
4、配置Hadoop JDK路径修改hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路径:
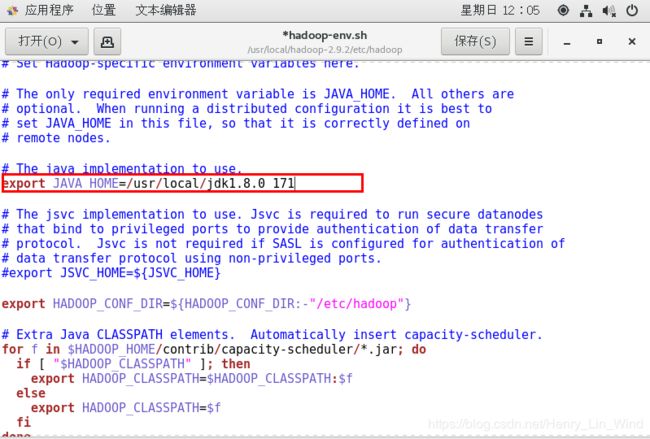
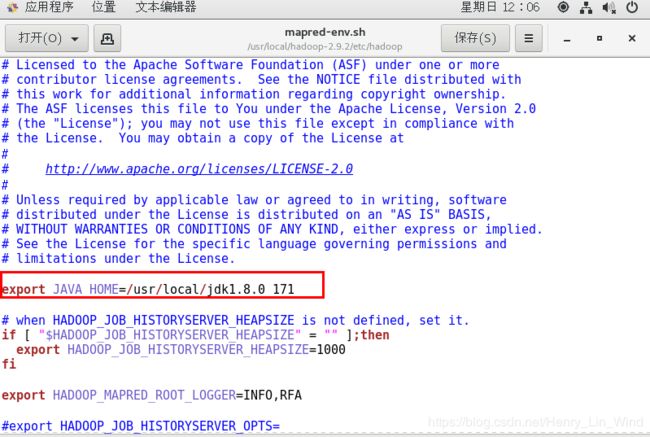
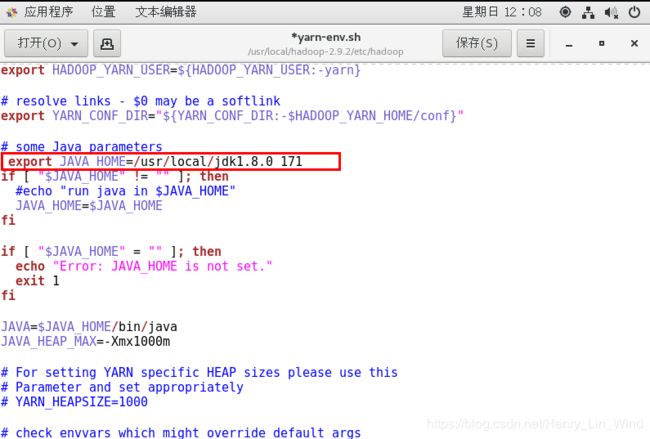
5、配置core-site.xml
fs.defaultFS
hdfs://hadoop1:8020
hadoop.tmp.dir
/usr/local/hadoop-2.9.2/data/tmp
fs.defaultFS为NameNode的地址。
hadoop.tmp.dir为hadoop临时目录的地址,默认情况下,NameNode和DataNode的数据文件都会存在这个目录下的对应子目录下。应该保证此目录是存在的,如果不存在,先创建。
6、配置hdfs-site.xml
dfs.namenode.secondary.http-address
hadoop3:50090
dfs.namenode.secondary.http-address是指定secondaryNameNode的http访问地址和端口号,因为在规划中,我们将hadoop3规划为SecondaryNameNode服务器。
7、配置slaves
vim etc/hadoop/slaveshadoop1
hadoop2
hadoop38、配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop2
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
106800
根据规划yarn.resourcemanager.hostname这个指定resourcemanager服务器指向hadoop2。
yarn.log-aggregation-enable是配置是否启用日志聚集功能。
yarn.log-aggregation.retain-seconds是配置聚集的日志在HDFS上最多保存多长时间。
9、配置mapred-site.xml
从mapred-site.xml.template复制一个mapred-site.xml文件。
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop3:10020
mapreduce.jobhistory.webapp.address
hadoop3:19888
10、设置SSH无密码登录
在hadoop1上生成公钥,不断回车即可。
[root@hadoop1 hadoop-2.9.2]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:j3UJ6KS7FajeLVCd3/KS62GjA9ANPDWZDRftgcn6RSo root@hadoop1
The key's randomart image is:
+---[RSA 2048]----+
| . .+*o= |
| + o+= + |
| . =oo.+ . |
| . o=E ..o. |
| oo S+.oo |
| .... =+.. |
| ....o =+ |
| . ..+.ooo. |
| . o.oooo |
+----[SHA256]-----+
在hadoop1分发公钥,分别分发给三台主机。(如下,操作中需要回复yes确认以及登录密码)
[root@hadoop1 hadoop-2.9.2]# ssh-copy-id hadoop1
The authenticity of host 'hadoop1 (192.168.100.10)' can't be established.
ECDSA key fingerprint is SHA256:D/yWgW1PoFwxoBex4pbN4LqUAUfheZ2CRJ8ejEeregk.
ECDSA key fingerprint is MD5:79:25:23:98:0c:c2:6d:a1:6d:56:1b:5f:ce:32:62:4e.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop1'"
and check to make sure that only the key(s) you wanted were added.
[root@hadoop1 hadoop-2.9.2]# ssh-copy-id hadoop2
The authenticity of host 'hadoop2 (192.168.100.11)' can't be established.
ECDSA key fingerprint is SHA256:D/yWgW1PoFwxoBex4pbN4LqUAUfheZ2CRJ8ejEeregk.
ECDSA key fingerprint is MD5:79:25:23:98:0c:c2:6d:a1:6d:56:1b:5f:ce:32:62:4e.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop2'"
and check to make sure that only the key(s) you wanted were added.
[root@hadoop1 hadoop-2.9.2]# ssh-copy-id hadoop3
The authenticity of host 'hadoop3 (192.168.100.12)' can't be established.
ECDSA key fingerprint is SHA256:D/yWgW1PoFwxoBex4pbN4LqUAUfheZ2CRJ8ejEeregk.
ECDSA key fingerprint is MD5:79:25:23:98:0c:c2:6d:a1:6d:56:1b:5f:ce:32:62:4e.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop3's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop3'"
and check to make sure that only the key(s) you wanted were added.
同样的在hadoop2、hadoop3上生成公钥和私钥后,将公钥分发到三台机器上。
11、分发Hadoop文件
通过Scp分发hadoop安装包到两个从站。
scp -r /usr/local/hadoop-2.9.2 hadoop2:/usr/local/
scp -r /usr/local/hadoop-2.9.2 hadoop3:/usr/local/启动集群
1、在主站格式化NameNode
${HADOOP_HOME}/bin/hdfs namenode –format注意:
如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错,NameNode和DataNode所在目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。
2、在hadoop1上启动HDFS
${HADOOP_HOME}/sbin/start-dfs.sh[root@hadoop1 hadoop-2.9.2]# ${HADOOP_HOME}/sbin/start-dfs.sh
Starting namenodes on [hadoop1]
hadoop1: starting namenode, logging to /usr/local/hadoop-2.9.2/logs/hadoop-root-namenode-hadoop1.out
hadoop1: starting datanode, logging to /usr/local/hadoop-2.9.2/logs/hadoop-root-datanode-hadoop1.out
hadoop2: starting datanode, logging to /usr/local/hadoop-2.9.2/logs/hadoop-root-datanode-hadoop2.out
hadoop3: starting datanode, logging to /usr/local/hadoop-2.9.2/logs/hadoop-root-datanode-hadooop3.out
Starting secondary namenodes [hadoop3]
hadoop3: starting secondarynamenode, logging to /usr/local/hadoop-2.9.2/logs/hadoop-root-secondarynamenode-hadooop3.out
查看进程启动情况:
[root@hadoop1 hadoop-2.9.2]# jps
7030 DataNode
6888 NameNode
7276 Jps
[root@hadoop2 hadoop-2.9.2]# jps
3385 DataNode
3434 Jps
[root@hadooop3 hadoop-2.9.2]# jps
3668 DataNode
3764 SecondaryNameNode
3807 Jps
3、在hadoop2 启动YARN
${HADOOP_HOME}/sbin/start-yarn.sh[root@hadoop2 hadoop-2.9.2]# ${HADOOP_HOME}/sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.9.2/logs/yarn-root-resourcemanager-hadoop2.out
hadoop3: starting nodemanager, logging to /usr/local/hadoop-2.9.2/logs/yarn-root-nodemanager-hadooop3.out
hadoop1: starting nodemanager, logging to /usr/local/hadoop-2.9.2/logs/yarn-root-nodemanager-hadoop1.out
hadoop2: starting nodemanager, logging to /usr/local/hadoop-2.9.2/logs/yarn-root-nodemanager-hadoop2.out
查看进程启动情况:
[root@hadoop1 hadoop-2.9.2]# jps
7347 NodeManager
7030 DataNode
6888 NameNode
7469 Jps
[root@hadoop2 hadoop-2.9.2]# jps
3652 NodeManager
3974 Jps
3385 DataNode
3551 ResourceManager
[root@hadooop3 hadoop-2.9.2]# jps
3668 DataNode
3764 SecondaryNameNode
4021 Jps
3896 NodeManager
4、 在hadoop1上启动日志服务器
${HADOOP_HOME}/sbin/mr-jobhistory-daemon.sh start historyserver查看进程:
[root@hadooop1 hadoop-2.9.2]# jps
4115 Jps
3668 DataNode
3764 SecondaryNameNode
3896 NodeManager
4074 JobHistoryServer
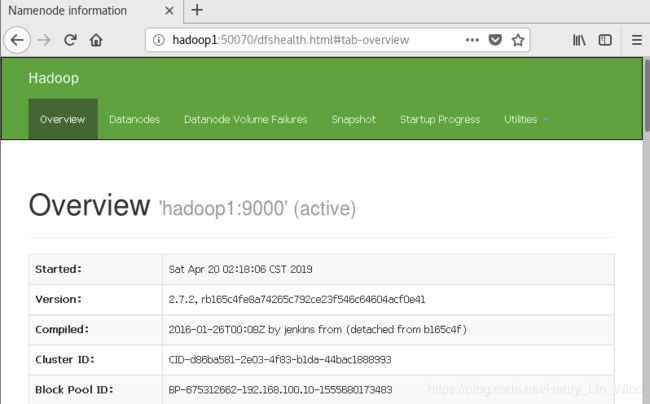
5、 查看HDFS Web页面
根据规划,我们部署在主站,所以访问路径为 //hadoop1:50070
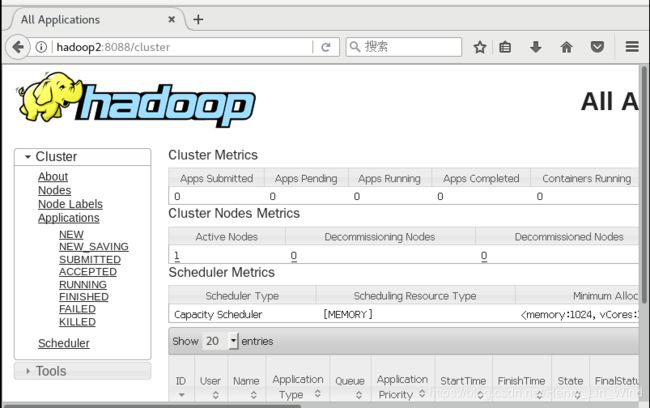
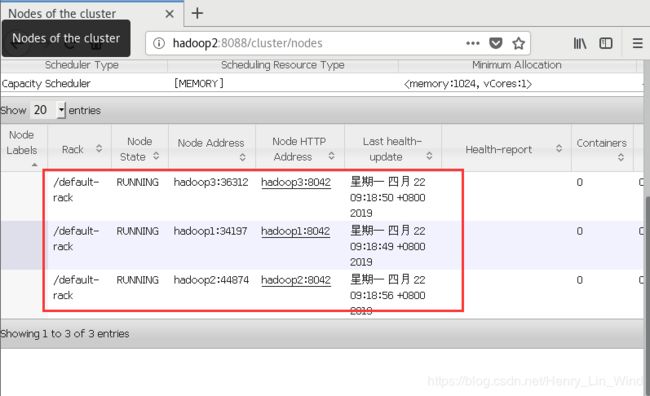
6、 查看YARN Web 页面
根据规划,我们部署在从站 hadoop2,所以访问路径为 //hadoop2:8088
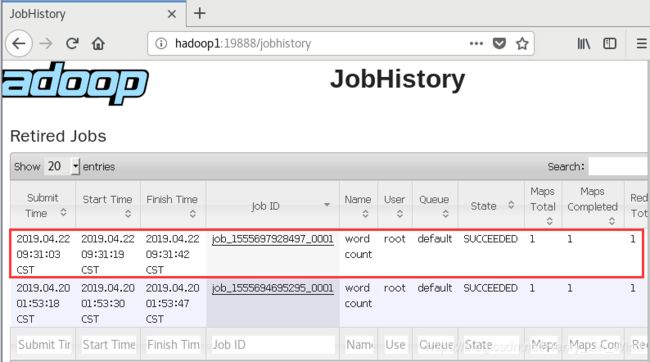
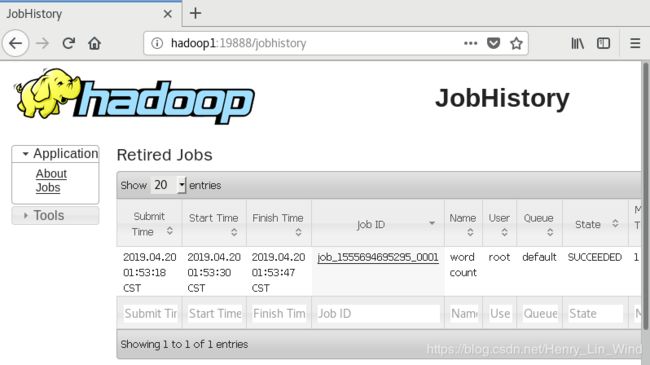
7、查看日志历史服务 Web页面
测试
接下来运行自带的 wordcounter 来验证
1、 创建测试用的Input文件
${HADOOP_HOME}/bin/hdfs dfs -mkdir -p /wordcountdemo/input2、上传一个测试文件到input文件夹
${HADOOP_HOME}/bin/hdfs dfs -put ${HADOOP_HOME}/etc/hadoop/core-site.xml /wordcountdemo/input3、运行WordCount MapReduce Job
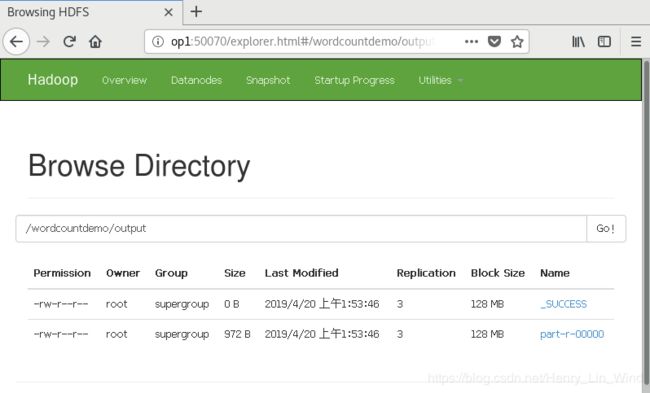
${HADOOP_HOME}/bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wordcountdemo/input /wordcountdemo/output4、查看结果
http://hadoop1:50070/explorer.html#/wordcountdemo/output
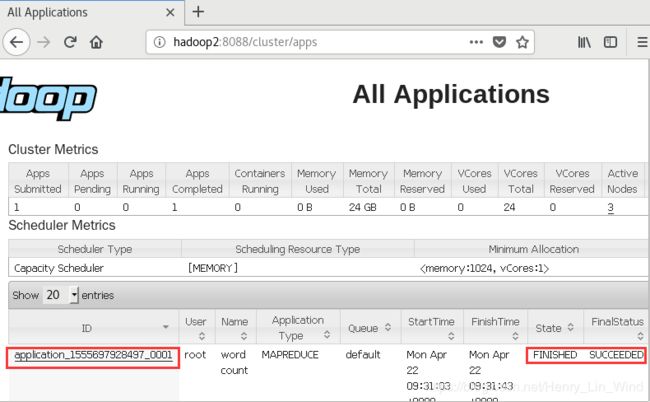
http://hadoop2:8088/cluster/apps
http://hadoop1:19888/jobhistory