重试机制,CAP原则
前言
经过上几篇文章学习,我们已经搭建了一个基本的微服务架构,在上一篇文章的基础上,我来讲重试机制,熔断器。
上篇文章:负载均衡Ribbon底层实现
我们已经搭建了负载均衡Ribbon,但是有个问题,如果我们UserService服务器,一个崩了,因为Eureka中还注册了它的端口,尽管有心跳续约保护服务,但是Eureka宁可放过1000,不愿错杀一个服务的机制,使得我们系统并不知道要访问的某个服务器挂了,所以,我们要引入一个机制——重试机制
讲重试机制的前面,我们先了解一个概念——CAP
一、CAP
1. CAP原则:
CAP原则又称CAP定理,指的是在一个分布式系统中,
-
Consistency(一致性)
-
Availability(可用性)
-
Partition tolerance(分区容错性)
三者不可兼得
2. 分区容错性
参考文章:CAP 定理的含义 尤雨溪
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。
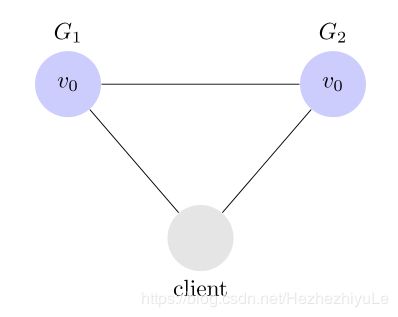
上图中,G1 和 G2 是两台跨区的服务器。G1 向 G2 发送一条消息,G2 可能无法收到。系统设计的时候,必须考虑到这种情况。
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,剩下的 C 和 A 无法同时做到。
3. 一致性
Consistency 中文叫做"一致性"。意思是,写操作之后的读操作,必须返回该值。举例来说,某条记录是 v0,用户向 G1 发起一个写操作,将其改为 v1。
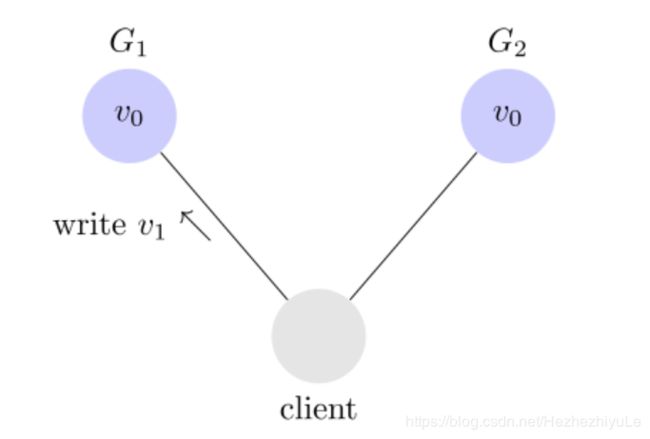
接下来,用户的读操作就会得到 v1。这就叫一致性。

问题是,用户有可能向 G2 发起读操作,由于 G2 的值没有发生变化,因此返回的是 v0。G1 和 G2 读操作的结果不一致,这就不满足一致性了。

为了让 G2 也能变为 v1,就要在 G1 写操作的时候,让 G1 向 G2 发送一条消息,要求 G2 也改成 v1。
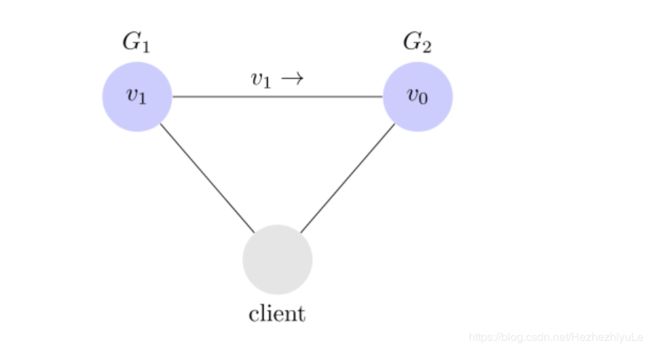
这样的话,用户向 G2 发起读操作,也能得到 v1。

4. 可用性
Availability 中文叫做"可用性",意思是只要收到用户的请求,服务器就必须给出回应。
用户可以选择向 G1 或 G2 发起读操作。不管是哪台服务器,只要收到请求,就必须告诉用户,到底是 v0 还是 v1,否则就不满足可用性。
5. 一致性和可用性的矛盾
一致性和可用性,为什么不可能同时成立?答案很简单,因为可能通信失败(即出现分区容错)。
如果保证 G2 的一致性,那么 G1 必须在写操作时,锁定 G2 的读操作和写操作。只有数据同步后,才能重新开放读写。锁定期间,G2 不能读写,没有可用性不。
如果保证 G2 的可用性,那么势必不能锁定 G2,所以一致性不成立。
综上所述,G2 无法同时做到一致性和可用性。系统设计时只能选择一个目标。如果追求一致性,那么无法保证所有节点的可用性;如果追求所有节点的可用性,那就没法做到一致性。
6. 总结:
- 一致性:在分布式系统中的所有数据,在同一时刻是否同样的值
- 可用性:在集群中一部分节点故障后,集群整体是否还能稳定的响应请求。
- 分区容错性/可靠性:
CP:一致性+可靠性
AP:可用性+可靠性
二、重试机制
Eureka的服务治理强调了CAP原则中的AP,即可用性和可靠性。它与Zookeeper这一类强调CP(一致性,分区容错)的服务治理框架最大的区别在于:Eureka为了实现更高的服务可用性,牺牲了一定的一致性,极端情况下它宁愿接收故障实例也不愿丢掉健康实例,正如我们上面所说的自我保护机制。
但是,此时如果我们调用了这些不正常的服务,调用就会失败,从而导致其它服务不能正常工作!这显然不是我们愿意看到的。
启动服务
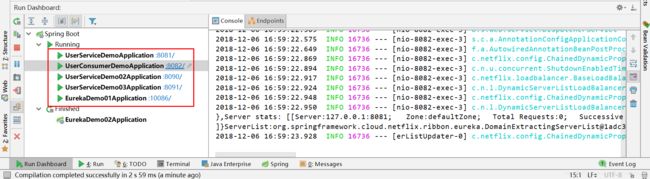
测试访问 正常
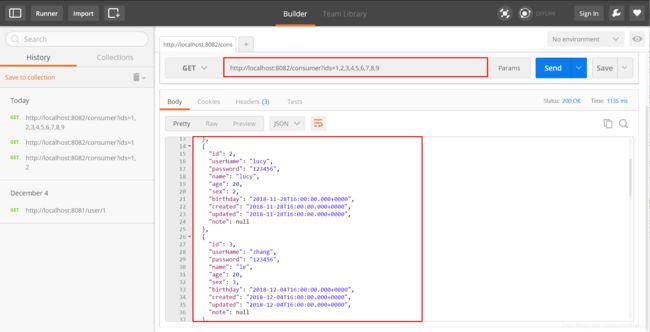
我们现在关闭一个user-service实例:
因为服务剔除的延迟,consumer并不会立即得到最新的服务列表,此时再次访问你会得到错误提示:
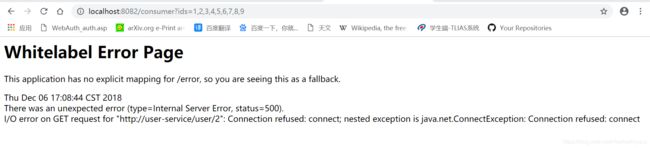

但是此时,8081服务其实是正常的。
因此Spring Cloud 整合了Spring Retry 来增强RestTemplate的重试能力,当一次服务调用失败后,不会立即抛出异常,而是再次重试另一个服务。
只需要(user-consumer)简单配置即可实现Ribbon的重试:
spring:
cloud:
loadbalancer:
retry:
enabled: true # 开启Spring Cloud的重试功能
user-service:
ribbon:
ConnectTimeout: 250 # Ribbon的连接超时时间
ReadTimeout: 1000 # Ribbon的数据读取超时时间
OkToRetryOnAllOperations: true # 是否对所有操作都进行重试
MaxAutoRetriesNextServer: 1 # 切换实例的重试次数
MaxAutoRetries: 1 # 对当前实例的重试次数
根据如上配置,当访问到某个服务超时后,它会再次尝试访问下一个服务实例,如果不行就再换一个实例,如果不行,则返回失败。切换次数取决于MaxAutoRetriesNextServer参数的值
引入spring-retry依赖
<dependency>
<groupId>org.springframework.retrygroupId>
<artifactId>spring-retryartifactId>
dependency>
我们重启user-consumer-demo,测试,发现即使user-service2宕机,也能通过另一台服务实例获取到结果!
页面

Postman

祝你幸福
送你一首歌《往后余生》王贰浪
附图:我的朋友圈