【数据分析与数据挖掘】三、单因子探索分析与可视化(下)
目录
1.函数讲解
(1)matplotlib.pyplot.xticks(ticks, [labels], **kwargs)
2.柱状图
3.直方图
4.箱线图
5.折线图
6.饼图
python可视化工具:matplotlib、seaborn、plotly.
1.函数讲解
(1)matplotlib.pyplot.xticks(ticks, [labels], **kwargs)
(a)作用
- 设置x轴的刻度位置和刻度对应的标签;
(b)参数
- ticks:传入的是array类型,表示在哪个位置设置刻度,例如传入[1,2,3],那么会把x轴分为三等份,
- lables: 可选,传入的是array类型,对每个刻度的描述;
- kwargs:意思是可以传入matplotlib.text.Text类的属性来控制显示的样式,例如rotation=17表示刻度上的标签倾斜程度。
(c)返回值
- 返回x轴的刻度位置和对应的标签;
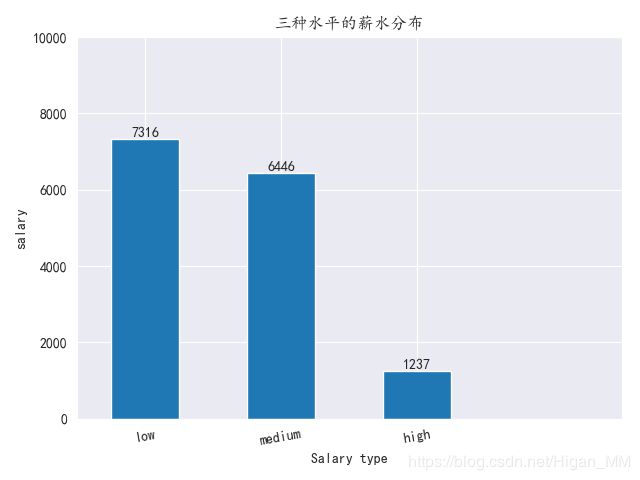
2.柱状图
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 设置中文字体
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.serif'] = ['KaiTi']
# 读入数据
file = pd.read_csv("D:/HR.csv")
# 使用seaborn可以改变样式,设置成darkgrid,灰底白条纹
# 注意要放在前面,否则显示不出效果
# {"font.sans-serif":['KaiTi', 'Arial']} 设置字体,否则显示不出中文
# sns.set_style(style="darkgrid")
sns.set_style("darkgrid", {"font.sans-serif": ['KaiTi', 'Arial']})
# sns.set_context(context="poster") 设置字体
plt.title("三种水平的薪水分布")
plt.xlabel("Salary type")
plt.ylabel("salary")
# 一共有多少个数据,转为array形式,[1,2,3]
len = np.arange(len(file["salary"].value_counts()))
# 将图形平移一些,因为是这一个numpy类型的array,所以可以直接加
len_new = len + 0.5
# 得到salary的种类:low、medium、high
lables = file["salary"].value_counts().index
# 分别得到salary的三种收入水平的数据
data = file["salary"].value_counts()
# 设置x轴刻度
plt.xticks(len_new, lables, rotation=10)
# 设置x、y轴的显示范围,x范围0-4,y轴范围0-10000
plt.axis([0, 4, 0, 10000])
# 把数字标在图表上
for x, y in zip(len_new, data):
plt.text(x, y, y, ha="center", va="bottom")
# 画直方图
# 设置柱状图的宽度 width=0.5
plt.bar(len_new, data, width=0.5)
plt.show()
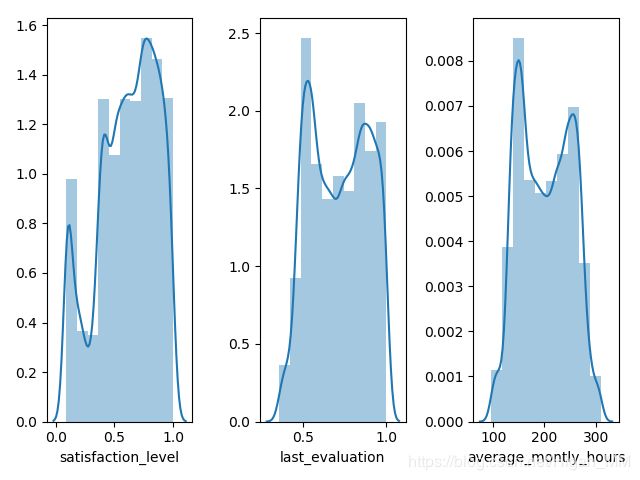
3.直方图
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读入数据
file = pd.read_csv("D:/HR.csv")
f = plt.figure()
sl = file["satisfaction_level"]
# 把为空的数据删除,否则直方图会报错
sl = sl.dropna()
f.add_subplot(1, 3, 1)
# kde=False表示图中那条参数不会出现
# hist=False 表示直方图不出现
# sns.distplot(sl, bins=10, kde=False,hist=False)
sns.distplot(sl, bins=10)
# 绘制第二个子图
f.add_subplot(1, 3, 2)
sns.distplot(file["last_evaluation"], bins=10)
# 绘制第三个子图
f.add_subplot(1, 3, 3)
sns.distplot(file["average_montly_hours"], bins=10)
plt.show()
4.箱线图
可以反映异常值和正常值的区间范围。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读入数据
file = pd.read_csv("D:/HR.csv")
sns.boxplot(y=file["time_spend_company"])
plt.show()
从图中可以看出:
上四分位数:4;
下四分位数:3 ;
分位数边界值2和5 ,不会取到小数,取到离小数最近的那个数,取整的意思;
异常值 : 图中那几个点。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读入数据
file = pd.read_csv("D:/HR.csv")
# 有两个参数需要注意saturation,whis
# saturation=0.75 表示4分位数
# whis=3 表示4分位数的k值为3
# 把file["time_spend_company"]赋值给了x
sns.boxplot(x=file["time_spend_company"],saturation=0.75, whis=3)
plt.show()
5.折线图
一般表示数据变化的趋势,所以x轴一般是时间,或者规模;
# 折线图
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读入数据
file = pd.read_csv("D:/HR.csv")
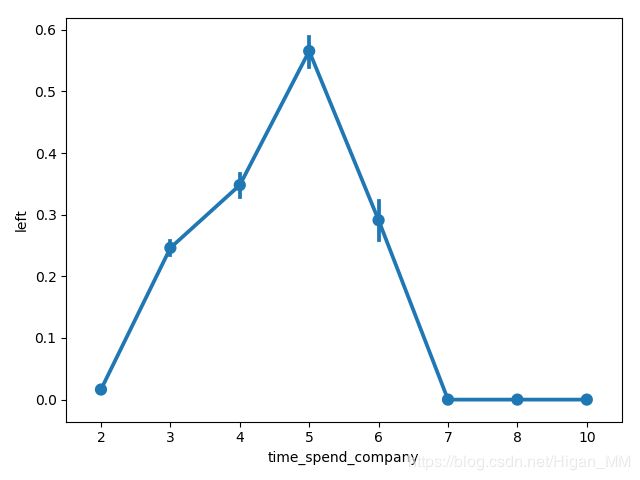
sub_file = file.groupby("time_spend_company").mean()
# 观察随着在公司呆的时间越长,员工离职情况
labels = sub_file.index
data = sub_file["left"]
sns.pointplot(labels, data)
plt.show()
# seaborn中画折线图的另一种画法
# x轴和y轴直接写出,再把整个data传进去
sns.pointplot(x="time_spend_company", y="left", data=file)
plt.show()由图中可以看出:
在第5年的时候,离职率最高,4年的时候也比较高;
在呆了5年之前,随着在公司呆的时间比较久,离职率也慢慢变高;
呆了7年左右的员工,离职率变低,基本保持不变;

seaborn另一种画法画出来的图:
6.饼图
# 饼图
# seaborn里没有饼图的画法,所以还是用matplotlib来画
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读入数据
file = pd.read_csv("D:/HR.csv")
# normalize 归一化
data = file["time_spend_company"].value_counts(normalize=True)
labels = data.index
# 着重强调某一个部分,着重强调3,数字不用引号,字符要引号
explodes = [0.1 if i==3 else 0 for i in labels]
# autopct="%1.1f%%" 显示百分比
# colors=sns.color_palette("Reds") 使用seaborn当中的色系
plt.pie(data,explode=explodes, labels=labels, autopct="%1.1f%%", colors=sns.color_palette("Reds"))
plt.show()