利用sklearn.cluster实现k均值聚类
一、k-mean算法介绍
1.主要思想:在给定聚类簇数(K值)【n_clusters】和K个初始类簇中心(通常从数据集中随机选取k个数据)的情况下,历遍数据集中的每个数据点,而数据点距离哪个类簇中心(cluster centers)最近,就把该数据点分配到这个类簇中心点所代表的类簇中;所有数据点分配完毕之后,根据类簇内的所有点重新计算每个类簇的中心点(计算簇中的所用点的均值并将均值作为新的簇质心),然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小,或者达到指定的迭代次数【max_iter】。
注意:簇中心=簇质心
2.算法使用说明:
优点:容易实现
缺点:可能收敛到局部最小值(受到初始簇中心的影响),在大规模数据集上收敛较慢(每次迭代均需要历遍数据集中的每一个数据样本,且迭代次数默认值为300)
使用数据类型:数值型数据
二、sklearn库的使用:
关于如何使用sklearn.cluster.KMeans的官方文档:
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
在scikit-learn中,包括两个K-Means的算法,一个是传统的K-Means算法,对应的类是KMeans。
另一个是基于采样的Mini Batch K-Means算法,对应的类是MiniBatchKMeans。
1.1 KMeans类主要参数
sklearn.cluster.KMeans()

参数说明:
1.输入参数
n_clusters:数据集将被划分成 n_clusters个‘簇’即k值以及(int, optional, default: 8)。一般需要选取多个k值进行运算,并用评估标准判断所选k值的好坏,以获得较好的聚类效果。
max_iter : 最大迭代次数( int, default: 300)一般如果是凸数据集的话可以不管这个值,如果数据集不是凸的,可能很难收敛,此时可以指定最大的迭代次数让算法可以及时退出循环。(较难理解待解决中)
init: 簇中心初始值的选择方式 {‘k-means++’, ‘random’ or an ndarray} defaults to ‘k-means++’:random:从数据集中随机选取k个样本;an ndarray:人为选定
random_state:随机状态。integer or numpy 默认是None.任意填写一个整数值或numpy,每次产生的随机数都相同(If an integer is given, it fixes the seed,也就是匹配随机种子:保留了当前获取随机数的原始信息,当你想产生和该次获取随机数的效果一样的时候,你可以申明一下随机种子,也就是拿可以长出相同类型植物的种子,进行培养以得到你希望得到的植物,这是一种形象的命名,当时要注意取值,取值相当于告诉你这颗种子最终会长出的植物类型),这样你每次运行程序的时候,获得的数据都是一样的。
参考:https://www.zhihu.com/question/56315846
2.属性
cluster_centers_ : 每个簇中心的坐标 array, [n_clusters, n_features]
labels_ :每个样本的标签
inertia_ : float Sum of distances of samples to their closest cluster center.
3.方法
fit(X[, y]) Compute k-means clustering. 执行k均值聚类
fit_predict(X[, y]) Compute cluster centers and predict cluster index for each sample.
计算簇的中心并且预测每个样本对应的簇类别,相当于先调用fit(X)再调用predict(X),提倡这种方法
三、程序:
#-*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
plt.figure()
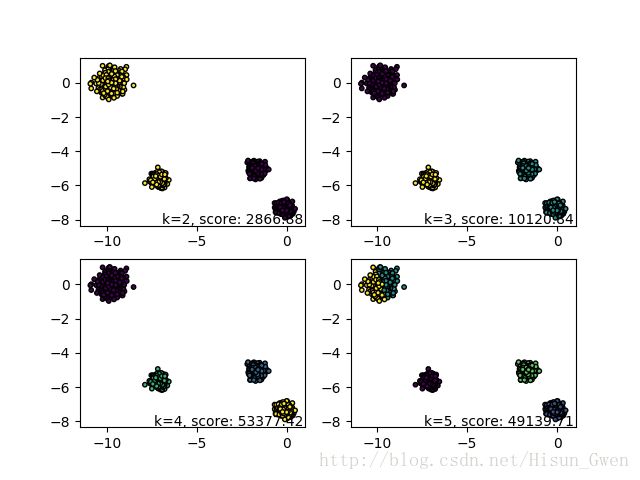
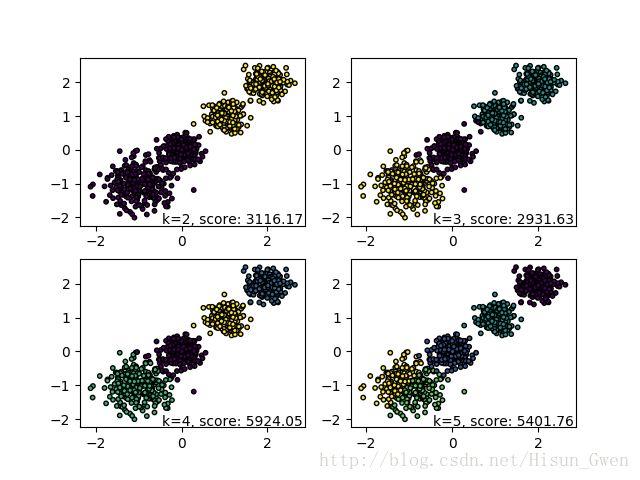
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.2, 0.2, 0.2], random_state =9) #生成测试数据
for index,k in enumerate((2,3,4,5)):
plt.subplot(2,2,index+1)
y_pred = KMeans(n_clusters=k, random_state=9).fit_predict(X) #预测值
score=metrics.calinski_harabaz_score(X, y_pred)
plt.scatter(X[:, 0], X[:, 1], c=y_pred,s=10,edgecolor='k')
plt.text(.99, .01, ('k=%d, score: %.2f' % (k,score)), #文本注释,标注关键信息
transform=plt.gca().transAxes, size=10,horizontalalignment='right')
plt.show()
效果图:
编程大致框架:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
#载入数据
dataMat=np.mat(loadDataSet("testSet.txt"))
#k均值聚类
y_pred=KMeans(n_clusters=4,random_state=9).fit_predict(dataMat)
plt.scatter(dataMat[:, 0], dataMat[:, 1], c=y_pred,s=10,edgecolor='k')
plt.show()四.程序说明
4.1 sklearn.datasets.make_blobs 聚类数据生产器
作用:用来生成聚类算法的测试数据
参数说明:
1.输入参数
n_samples:待生成的样本的总数 int, optional (default=100)
n_features:每个样本的特征数 int, optional (default=2)
centers: :簇质心的数目int(此时质心的位置随机分配)或者其位置 array of shape [n_centers, n_features], optional (default=3)
cluster_std:每个簇的标准差,衡量某簇数据点的分散程度(见效果图) float or sequence of floats, optional (default=1.0)
random_state:
2.输出:
X : 生成的样本数据集 array of shape [n_samples, n_features]
y : 每个样本的整数型簇标签 array of shape [n_samples]
centers=4的情况: