Python图片文字识别入门级环境安装
第一步:下载安装
下载安装tesseract-ocr。
链接:https://pan.baidu.com/s/1_n8LMOpfdNGXmd1-aB82_A 提取码:pann
点击下一步,下一步进行安装,记住安装的目录。
第二步:环境变量配置
配置环境变量,我安装在G:\tesseract-ocr\Tesseract-OCR,如图所示

配置系统环境变量,在path后面新增上面路径:G:\tesseract-ocr\Tesseract-OCR
新增一个系统变量名:TESSDATA_PREFIX 值为:G:\tesseract-ocr\Tesseract-OCR\tessdata(否则访问不到)
第三步:自测使用
使用
打开命令终端,输入:tesseract -v,可以看到版本信息

用命令tesseract --list-langs来查看Tesseract-OCR支持语言。

将命令行切换至目标图像文件目录,比如我们转换文件为test.png(图片文件允许多种格式),位于C:\Users\Lian\Desktop\test;然后在命令行中输入
tesseract test.png output_1 –l eng
【语法】: tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
imagename为目标图片文件名,需加格式后缀;outputbase是转换结果文件名;lang是语言名称(在Tesseract-OCR中tessdata文件夹可看到以eng开头的语言文件eng.traineddata),如不标-l eng则默认为eng。
打开文件output_1.txt,发现tesseract成功的将图像转换成文字。
第四步:中文包安装
下载安装包
链接:https://pan.baidu.com/s/1FE--WDVoVZf_l3kv-HL-Rg
提取码:ld98
复制到tessdata目录,如图所示: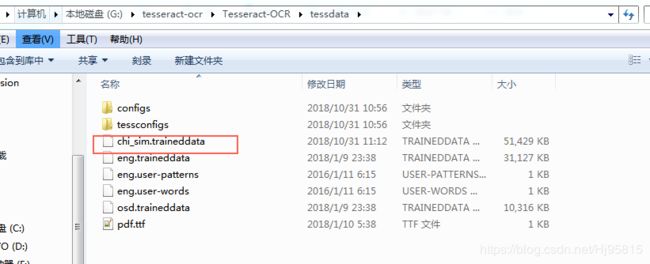
第五步:python中的使用
找到pythone环境下的pytesseract.py文件,打开并修改
tesseract_cmd的内容为tesseract.exe的相关路径,如
tesseract_cmd = 'G:/tesseract-ocr/Tesseract-OCR/tesseract.exe'
编写测试代码,运行,代码如下:
#! /usr/bin/env python
from PIL import Image
import pytesseract
#上面都是导包,只需要下面这一行就能实现图片文字识别
text=pytesseract.image_to_string(Image.open("hello.jpg"),lang='chi_sim')
print(text)