TensorFlow学习笔记(6)读取数据
Overview 之前几次推送的全部例程,使用的都是tensorflow预处理过的数据集,直接载入即可。例如:
然而实际中我们使用的通常不会是这种超级经典的数据集,如果我们有一组图像存储在磁盘上面,如何以mini-batch的形式把它们读取进来然后高效的送进网络训练?这次推送我们首先用tensorflow最底层的API处理这个问题,后面推送介绍高层API。高层API是对底层的进一步封装,用户可以不必关心过多细节。不过了解一下比较底层的API还是有好处的。当你有一组自己的数据的时候,你需要经过以下两个步骤:(1)将全部数据写入一个后缀 .tfredords 的文件。
这个步骤涉及读入->预处理->写入tfrecords,对你的数据是什么格式没有要求。例如,如果你手中是图像数据,那用opencv/PIL等接口读入;如果是matlab数据(mat文件),那可以用h5py协议读入,等等。不管如何读入,最终都要写入到统一的tfrecords文件中,以便用tensorflow提供的接口高效读取。
(2)以mini-batch的形式从tfrecords中读取数据,送到模型的placeholder中支持网络训练。
实验设置 代码中使用的数据是存在磁盘中的400张png图像,也传到了github上面,存在my_data路径下面。部分如下:

代码实现以下功能:制备tfrecords形式的数据集,然后再以mini-batch读入,为了测试读入是否成功,把读入的数据显示在tensorboard上面。![]()
制备tfrecords数据集 在上次推送中(Tensorboard),大部分代码都是遵循API接口的固定“模式”写就可以,这次也主要以这种方式进行,而不过多讨论背后的理论细节。两个辅助函数定义这俩辅助函数的目的完全是不想让后面的代码太冗长
读取图像&写入tfrecords文件

几点说明(1)读取图像文件的时候用到了glob和opencv两个包。glob是将路径下全部文件名一次性存到一个list中,方面后面逐个读取;opencv则只是利用imread接口读取图像文件的。(2)和一切文件操作一样,向tfrecords文件中写入内容也需要建立一个writer对象,创建这个对象的是函数 tf.python_io.TFRecordWriter(3)feature是我们创建的一个字典对象,这里面可以包含你想记录的任何信息。在这里我们存入了三对键值(key: value):image_raw(图像数据,这个是核心内容),heigh(高),width(宽)。你也可以加入更多的信息,例如,通道数目,文件名等等。这些信息在后面读取数据的时候都可以一并读取出来。比如:在主程序中,你需要用到图像的尺寸参数,那么你可以将图像和尺寸参数一起读出。
(4)注意数据格式。图像数据本身是8bit的,因此我们用前面定义的辅助函数 _bytes_feature_ 把数据转化成tensorflow要求的tf.train.BytesList格式存入。实际中还会碰到图像本身是以float形式存储的,代码就需要相应的变动,这个下次推送再说。
从tfrecords中载入nimi-batch定义函数:读取一个样本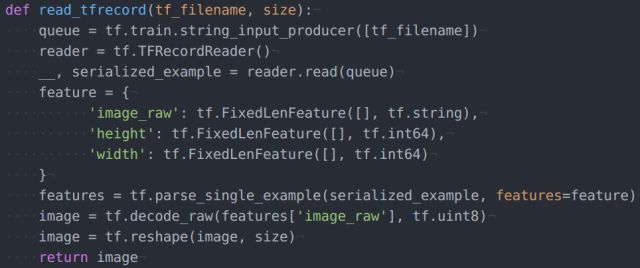
几点说明:(1)整个代码过程很烦杂,因为是调用的底层API,不过都是固定写法,其中的内部原理主页菌一知半解,不敢在这里随便讲(2)特别注意这里这个字典对象的定义方式首先,这里的三个key要和前面制备tfrecords时候一致;其次,注意数据格式,image_raw是8bit存储的,所以读取的时候限定tf.string类型,同理,height和width要限定tf.int64
(3)如前文所说,字典中存入的信息都可以通过key来读取,上面的代码只读取了图像信息,如果想获取height的值,可以补充这样一句代码:
height = tf.decode_raw(features['height'], tf.int64)
然后在函数返回值中把height也返回即可
(4)每一个样本是以一维的形式从数据流中抽取出来的,所以需要reshape成原始尺寸
定义mini-batch
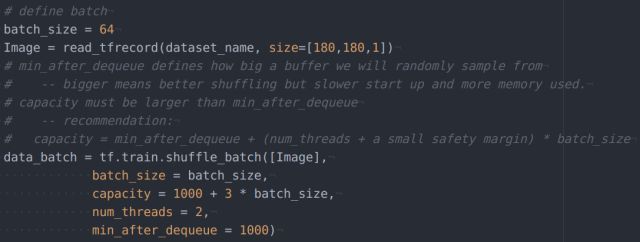
用前面定义的read_record获取一个样本,然后用tf.train.shuffle_batch来封装一个mini-batch。tf.train.shuffle_batch会多次通过read_record抽取样本,并且开辟一块内存空间建立队列(queue),将样本洗牌打乱,空间开辟越大,数据混乱度会越高。控制洗牌的参数是capacity和min_after_dequeue,官网文档中给出了这俩参数的取值建议,我粘贴到了代码注释中。注意:从最开始介绍tensorflow的时候主页菌就在强调一个事情:任何东西在用Session运行之前都是没有实际值的。这里也不例外。在主程序部分,每一个step都要这么一句代码:
batch = sess.run(data_batch)
这个batch才是实际的数据,是可以feed给placeholder的
主程序部分 我们的主程序是读取mini-batch然后用tensorboard显示。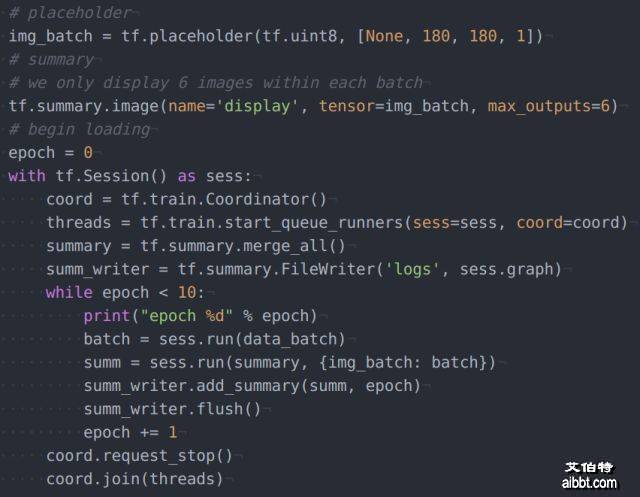
说明:有四行代码必不可少session开头的两行:coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
session结尾的两行
coord.request_stop()
coord.join(threads)
至于内部机理,文档写的太模糊,主页菌缺少计算机基础理论知识,并没有看懂
这次推送的数据是8bit的,然而如果我想用float格式存储怎么办?(或者原始数据就是float格式的,总不能截断成8bit来存储吧......)虽然这部分内容不多,但是由于这次推送信息量够大了,还是放到下次单独说吧。艾伯特(http://www.aibbt.com/)国内第一家人工智能门户
本次推送对应的源码:
http://www.aibbt.com/a/19073.html