收藏!836分钟的谷歌机器学习教程,10分钟带你看完!

- 为了尊重原意,部分名词不进行翻译。
- 为了更通俗易懂的解释概念,使用低维度的情况来解释。
1 机器学习概念
1.1 主要术语
标签预测的事物,即 y = ax + b 中的 y 变量,如房价、动物种类、是否垃圾邮件等。
特征输入变量,即 y = ax + b 中的 x 变量,x 可以是一个,也可以是多个,用 {x1, x2, ..., xn} 组成的向量来表示。比如电子邮件的文本字词、邮箱地址、发送时间等
样本具体某一个示例,比如一封邮件。有标签样本:邮件(x) + 是否垃圾邮件(y)无标签样本:邮件(x)
模型模型定义了特征与标签之间的关系。简单的理解为 y = ax + b 中的 a和 b。训练:输入(0, 1) , (1, 3) , (2, 5) 求出 a = 2, b = 1预测:输入 x = 10, 推断出 y = 10*2 +1 = 13
回归预测连续值, 如:
- 加利福尼亚州一栋房产的价值是多少?
- 用户点击此广告的概率是多少?
分类预测离散值, 如:
- 某个指定电子邮件是垃圾邮件还是非垃圾邮件?
- 这是一张狗、猫还是仓鼠图片?
- 这是 Jinkey(公众号 jinkey-love) 写的文章还是其他人写的文章?
损失预测值和目标值的差距。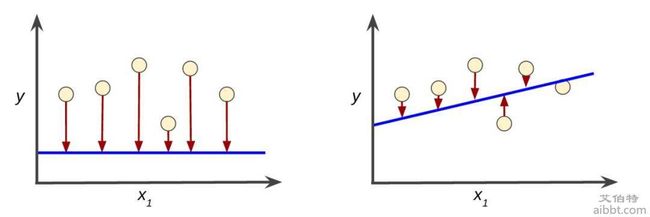 一种常见的损失函数就是我们的义务教育阶段都学过的"两点间的直线距离",其中 x1=x2:
一种常见的损失函数就是我们的义务教育阶段都学过的"两点间的直线距离",其中 x1=x2:
1.2 降低损失
大家都玩过猜数字游戏,主持人出一个 1-100 内的数字,其他人轮流猜测,玩家 A 提出一个数字,主持人只会说大了还是小了。这个过程靠猜测不停地逼近真实值(也就是不停地缩小损失的过程)
Gradient Descent其中一个常见的降低损失的方法就是梯度下降(Gradient Descent),用高中知识就可以理解了。假如损失函数 loss = x^2 + 2x + 1 的梯度函数就是 loss' = 2x + 2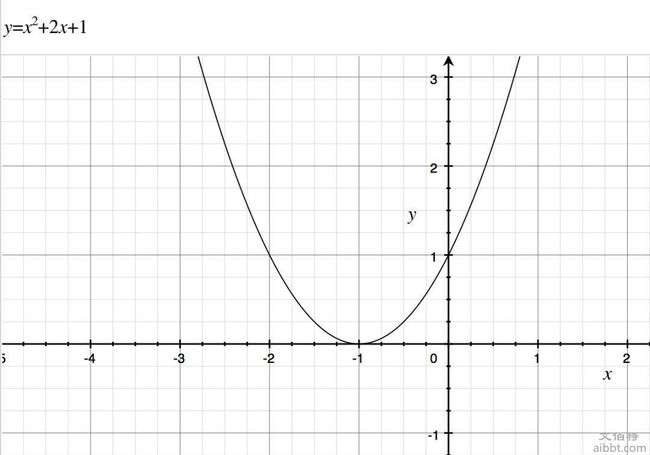
假如一开始输入x 等于 -3, -2, -1, 1, 2, 3是,y’即梯度分别等于 -4, -2, 0, 2, 4,所以如果输入的样本是(-2, ?) 则梯度下降的方向就是从 -2 -> -1移动,如果输入的样本是 (2, ?)就是从 -2 -> -1 来降低损失函数的值,慢慢移动到 -1 得到了损失函数的极小值。
看到这里你是否觉得直接通过高中的知识求导得到极小值就可以了?但如果变量不止一个,如果上述垃圾邮件样本包含的特征:文本内容包含“贷款”的数量、邮箱地址、发送时间等等,损失函数就可能是三维甚至多维的,存在一个或多个“局部最低小”,并且导数或偏导数不能求出的情况下,只能通过“有技巧地猜数字”来逼近真实值: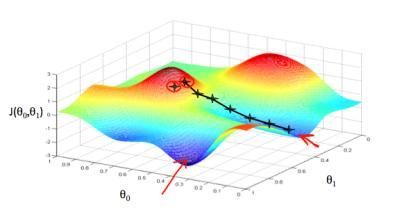 梯度下降方法有 随机梯度下降 SGD 和 小批量梯度下降 mini-batch SGD。至于具体差异,本文不展开说明,谷歌的教程也是为了速成。一般采用 mini-batch SGD 会更加高效。
梯度下降方法有 随机梯度下降 SGD 和 小批量梯度下降 mini-batch SGD。至于具体差异,本文不展开说明,谷歌的教程也是为了速成。一般采用 mini-batch SGD 会更加高效。
你可能会问不知道算法怎么写代码?在谷歌的 Tensorflow 框架里面,梯度下降就是一行代码而已, 所以初学者有个初步概念即可:
tf.train.GradientDescentOptimizer()
Learning Rate上面所说
从
-2 -> -1来降低损失函数的值
这里引入了学习率的概念-2到-1移动说明学习率是1。如果从-2移动到-1.8,学习率则是0.2。

学习率太大容易跳过最小值(or 极小值),如蓝线所示,学习率太小导致学习时间很长。
学习率 Playground:https://developers.google.com/machine-learning/crash-course/fitter/graph
1.3 过拟合
损失很低,但仍然是糟糕的模型,因为过度拟合了训练集数据,导致在测试集或训练集等新样本上效果很差。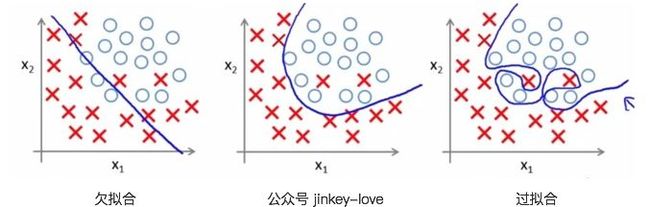
1.4 拆分数据
训练集和测试集 (Training and Test Sets)
- 训练集 - 用于训练模型的子集。
- 测试集 - 用于测试训练后模型的子集。
训练集和测试集 Playground:https://developers.google.cn/machine-learning/crash-course/training-and-test-sets/playground-exercise
某些情况下为了防止不小心在训练过程引入对测试集的拟合,引入验证集(就是把数据分成三份)

1.5 特征工程
所有类型的数据,最终都要转换为数字的形式,计算机才能学习。使用的特征要注意:
- 在数据集中出现大约 5 次以上,比如不能用数据的唯一 id 作为特征
- 具有清晰明确的含义
- 不包含超出范围的异常断点或“神奇”的值,比如电影评分为 -1 或 NaN
- 特征的定义不应随时间发生变化,比如
地点:北京是固定的,但不要用地点:219
特征组合 Playground:https://developers.google.cn/machine-learning/crash-course/feature-crosses/playground-exercises
1.5.1 数据类型
数值数据
离散数据(直接用或者先离散化)0、1、2连续数据 0.001、0.2、1.0、2.2
文本数据
作为分类标签{'Netherlands', 'Belgium', 'Luxembourg'}转换为 {0, 1, 2}
作为自然语言学习A = “Jinkey 是中国人”B = “Jinkey 是中国的学生”A + B 的词列表:(Jinkey, 是, 中国, 人, 的, 学生)如果具有某个词就用1表示、不具有就用0表示,这样就把 A 表示成:A = (1, 1, 1, 1, 0, 0)B = (1, 1, 1, 0, 1, 1)
图像数据
彩色图片是分开 RGBA 四通道的值作为图片特征,灰度图把灰度作为图片特征,黑白图黑色的像素为1白色为0。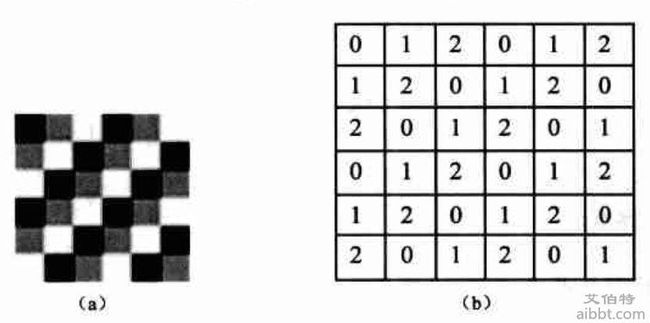
1.5.2 数据清洗
缩放特征值有一个特征 A (字段)的值是500000, 有一个特征B(字段)的值是0.1,这时候需要根据所有样本的 A 特征的最大值和最小值把特征值缩放到[0, 1]之间:
缩放值 = (真实值 - 平均值)/ 标准差
处理极端值
- 对每个值取对数
- 对大于某个值的特征值进行截断,比如 (1, 2, 3, 666, 2,3)-> (1, 2, 3, 3, 2,3)
分箱其实就是把数值离散化成一个个区间,然后用某个符号来标识 比如纬度37.4可以转换成两种形式:
比如纬度37.4可以转换成两种形式:
- 6(第6个区间)
- [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0] (作为一个11维张量,37.4属于第6个区间,所以为1)
这种方式也成为 one-hot 编码(具有一个特征为1,否则为0)
特征组合特征组合是指通过将两个或多个输入特征相乘来对特征空间中的非线性规律进行编码的合成特征。[A X B]:将两个特征的值相乘形成的特征组合。[A x B x C x D x E]:将五个特征的值相乘形成的特征组合。[A x A]:对单个特征的值求平方形成的特征组合。
其他
- 遗漏值。 例如,有人忘记为某个房屋的年龄输入值。
- 重复样本。 例如,服务器错误地将同一条记录上传了两次。
- 不良标签。 例如,有人错误地将一颗橡树的图片标记为枫树。
- 不良特征值。 例如,有人输入了多余的位数,或者温度计被遗落在太阳底下。
1.5.3 正则化
L2 正则
为什么要正则化?惩罚复杂的模型(过拟合的模型)
机器学习训练目标是损失函数最小化,如果复杂模型也算是一种损失,那么可以把模型复杂度加入到损失函数的公式里面。
如何衡量一个模型的复杂程度?各变量权重的平方和(L2正则)
效果:
- 使权重值接近于 0(但并非正好为 0)
- 使权重的平均值接近于 0,且呈正态(钟形曲线或高斯曲线)分布

Lambda正则系数在正则项前加系数 Lambda,其对权重的影响如图: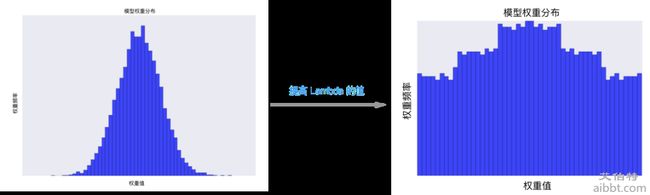
lambda 值过高 -> 模型会非常简单 -> 欠拟合lambda 值过低 -> 模型会非常复杂 -> 过拟合
L1 正则
为什么有 L2 正则 还要 L1 正则L2 正则化可以使权重变小,但是并不能使它们正好为 0.0,这样高维度特征矢量会消耗大量的内存
L1 正则项是绝对值
正则化 Playground:L2 https://developers.google.cn/machine-learning/crash-course/regularization-for-simplicity/playground-exercise-overcrossingL1 https://developers.google.cn/machine-learning/crash-course/regularization-for-sparsity/playground-exercise
1.6 逻辑回归 (Logistic Regression)
怎么分析一个句子属于褒义还是贬义?把从句子推倒出(褒义词数量,贬义词数量)二维向量做为特征 X,把人工标记的特征标为 Y,就进行逻辑回归。
比如我们有一系列人工标记的样本:

通过一个神奇的公式,机器学习到一些规律,比如机器学习到罩杯是 C 的女生是美女的概率为0.5; 腿长 为 1m 的女生被判断为美女的概率是 0.5。
当输入一个新的样本,系统就能根据学习到的模型1 / (1+exp(w0+w1*x1+w2*x2+...+wm*xm)),算出新加入的女生属于美女的概率是多少,比如说算出来是0.6的概率,那么如果定义阈值为 0.5, 那么0.6>0.5,所以就认为她是个美女。
0.5 称为分类阈值 classification threshold,为了将逻辑回归值(是美女的概率)映射到二元类别(是美女/不是美女),您必须指定分类阈值。
逻辑回归的损失函数
和线性回归采用平方损失不同,逻辑回归的损失函数是对数损失函数Log Loss,定义如下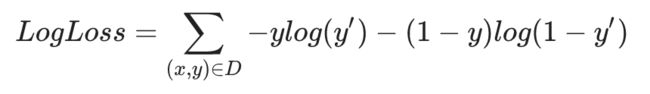 入门的你,你大可不必记住这个公司,因为在 tensorflow 里面要使用这个损失函数,只需要一行代码:
入门的你,你大可不必记住这个公司,因为在 tensorflow 里面要使用这个损失函数,只需要一行代码:
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=model_output, labels=y_target))
混淆矩阵 Confusion Matrix
对于二分类,我们使用混淆矩阵来表示所有可能的分类结果。

以《狼来了》的故事为例:
精确率 Precision
在被识别为正类别的样本中,确实为正类别的比例是多少?
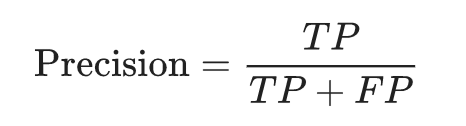
召回率 Recall
在所有正类别样本中,被正确识别为正类别的比例是多少?

精确率和召回率往往是此消彼长的情况。也就是说,提高精确率通常会降低召回率值
ROC 曲线Receiver Operating Characteristic Curve, 用于绘制采用不同分类阈值时的 TPR 与 FPR。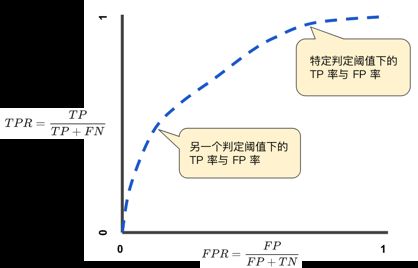
AUC 面积ROC 曲线下面积,Area under the ROC Curve。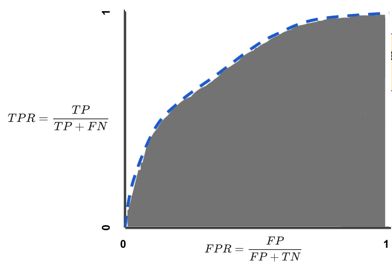
1.7 神经网络
为什么有逻辑回归等传统机器学习方法还要神经网络?处理非线性问题(y = ax + b 这种叫做线性模型)
彩色小球代表神经元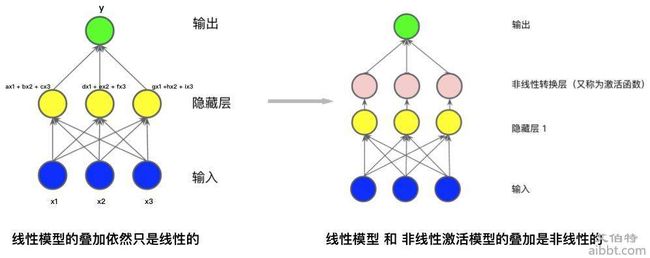
神经网络 Playground:https://developers.google.cn/machine-learning/crash-course/introduction-to-neural-networks/playground-exercises
1.7.1 激活函数
把y = ax + b的 结果作为自变量输入激活函数: f(ax+b) 来作为神经元的输出值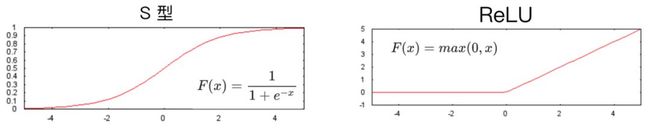
1.7.2 训练神经网络
方法:反向传播
具体过程你可以拿起笔,自己按照本文作者(公众号jinkey-love)之前翻译的文章来推演一遍:《用笔一步步演示人工神经网络的反向传播算法——Jinkey 翻译》
可能出现的异常:
 上图是之前网络很流行的图,说每天进步一点点,一年就会有很大收获;每天退步一点点,一年就会落后很多。这里就可以引出梯度消失和梯度爆炸的概念。
上图是之前网络很流行的图,说每天进步一点点,一年就会有很大收获;每天退步一点点,一年就会落后很多。这里就可以引出梯度消失和梯度爆炸的概念。
梯度消失
在深度网络中,计算这些梯度时,可能涉及许多小项的乘积。
当较低层的梯度逐渐消失到 0 时,这些层的训练速度会非常缓慢,甚至不再训练。
梯度爆炸
网络中的权重过大,则较低层的梯度会涉及许多大项的乘积。
在这种情况下,梯度就会爆炸:梯度过大导致难以收敛。
批标准化可以降低学习速率,因而有助于防止梯度爆炸。
随机失活 Dropout
在梯度下降法的每一步中随机丢弃一些网络单元。丢弃得越多,正则化效果就越强:
- 0.0 = 无丢弃正则化
- 1.0 = 丢弃所有内容。模型学不到任何规律
- 0.0 和 1.0 之间的值更有用
1.7.3 多类别神经网络
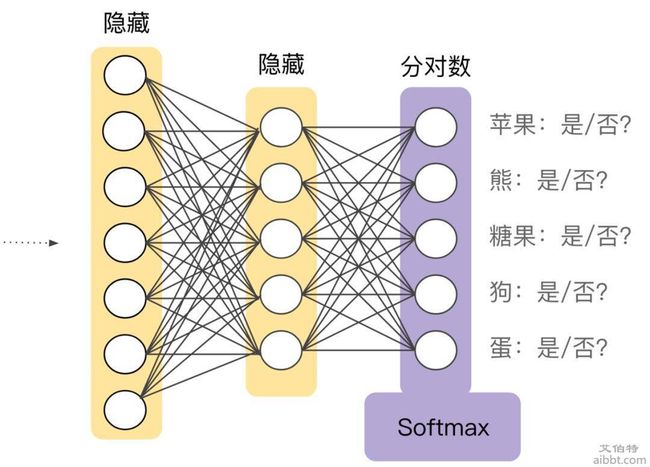
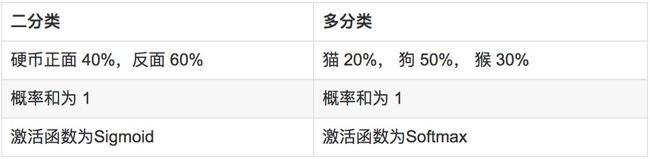
1.7.4 嵌套 (Embedding)
高维空间向低维空间的转换,用于计算两个实体的相似度。比如电影类别有科幻、成人、卡通那么,《小猪佩奇》就可以转换成one-hoting编码(0,0,1)《星球大战》就可以转换成one-hoting编码(1,1,0)《喜爱夜蒲》就可以转换成one-hoting编码(0,1,0)
《小猪佩奇》和《星球大战》的距离3,《星球大战》和 《喜爱夜蒲》的距离为1,所以当一个用户看了电影《星球大战》,可以给他推荐《喜爱夜蒲》而不是《小猪佩奇》。
2 机器学习工程
2.1 生产环境机器学习系统
- 尽可能重复使用常规机器学习系统组件。
- Google CloudML 解决方案包括 Dataflow 和 TF Serving
- 可以在 Spark、Hadoop 等其他平台中找到组件
- 了解机器学习系统的一些范例及其要求,找到自己需要哪些组件?
2.2 训练方法
静态模型 - 离线训练
- 易于构建和测试 - 使用批量训练和测试,对其进行迭代,直到达到良好效果。
- 仍然需要对输入进行监控
- 模型容易过时
动态模型 - 在线训练
- 随着时间推移不断为训练数据注入新数据,定期同步更新版本。
- 使用渐进式验证,而不是批量训练和测试
- 需要监控、模型回滚和数据隔离功能
- 会根据变化作出相应调整,避免了过时问题
2.3 预测方法
离线预测
使用 MapReduce 或类似方法批量进行所有可能的预测。记录到表格中,然后提供给缓存/查询表。
优点
- 不需要过多担心推理成本。
- 可以使用批量方法。
- 可以在推送之前对数据预测执行后期验证。
缺点
- 只能对我们知晓的数据进行预测,不适用于存在长尾的情况。
- 更新可能延迟数小时或数天。
在线预测
使用服务器根据需要进行预测。
优点
- 可在新项目加入时对其进行预测,非常适合存在长尾的情况。
- 计算量非常大,对延迟较为敏感,可能会限制模型的复杂度。
缺点
- 监控需求更多。
2.4 数据依赖关系
可靠性
信号是否始终可用?信号来源是否不可靠?
比如
- 信号是否来自因负载过重而崩溃的服务器?
- 信号是否来自每年 8 月去度假的人群?
版本控制
计算此数据的系统是否发生过变化?
比如
- 多久一次?
- 您如何知道系统发生变化的时间?
必要性
特征的实用性是否能证明值得添加此特征?
相关性
是否有任何特征密不可分,以至于需要采取额外策略来梳理它们?
反馈环
一个模型是否会影响另一个模型比如两个股价预测模型为例:
- 模型 A - 不理想的预测模型
- 模型 B
由于模型 A 有误,因此会导致错误地决定购买股票 X 的股票,而购买这些股票会抬高股票 X 的价格。模型 B 将股票 X 的股价用作输入特征,因此它很容易对股票 X 的价值得出错误结论。然后,模型 B 会根据模型 A 的错误行为购买或销售股票 X 的股份,反过来,模型 B 的行为会影响模型 A,而这样很可能会触发郁金香狂热效应或导致 X 公司的股价下滑。
3 机器学习系统在现实世界里的应用
3.1 癌症预测
特征:病人年龄、性别、 医疗状况、医院名称、生命体征、检验结果预测:是否会患有癌症
以上设定存在什么问题?
模型中包含的一个特征是医院名称,比如"癌症中心"等专门治疗癌症的机构,已经暗含了在医生的诊断结论,这叫做标签泄露**。当模型尝试取代医生去判断新样本时(还未就医 ),模型无法得知该信息,导致预测的结果非常糟糕。
3.2 文学
特征:文学语句预测:作者的政治派别
以上设定存在什么问题?
当我们创建测试训练和验证拆分内容时, 我们是通过逐句拆分样本来实现的。也就是说,同一个作者的语句会一部分会被编入训练集,一部分会编入测试集,这导致训练的模型可以了解某个作者在语言使用方面的特质, 而不仅仅是了解他使用的隐喻手法。所以应该在作者的层面,这个作者的所有语句要么都作为训练集,要么都作为测试集。
3.3 机器学习准则
- 确保第一个模型简单易用
- 着重确保数据管道的正确性
- 使用简单且可观察的指标进行训练和评估
- 拥有并监控您的输入特征
- 将您的模型配置视为代码:进行审核并记录在案
- 记下所有实验的结果,尤其是“失败”的结果
编程练习
Pandas 简介https://colab.research.google.com/notebooks/mlcc/intro_to_pandas.ipynb?hl=zh-cn
使用 TensorFlow 的起始步骤https://colab.research.google.com/notebooks/mlcc/first_steps_with_tensor_flow.ipynb?hl=zh-cn
合成特征和离群值https://colab.research.google.com/notebooks/mlcc/synthetic_features_and_outliers.ipynb?hl=zh-cn
验证:编程练习https://colab.research.google.com/notebooks/mlcc/validation.ipynb?hl=zh-cn
特征集:编程练习https://colab.research.google.com/notebooks/mlcc/feature_sets.ipynb?hl=zh-cn
特征组合编程练习https://colab.research.google.com/notebooks/mlcc/feature_crosses.ipynb?hl=zh-cn
逻辑回归编程练习https://colab.research.google.com/notebooks/mlcc/logistic_regression.ipynb?hl=zh-cn
稀疏性和 L1 正则化:编程练习https://colab.research.google.com/notebooks/mlcc/sparsity_and_l1_regularization.ipynb?hl=zh-cn
神经网络简介:编程练习https://colab.research.google.com/notebooks/mlcc/intro_to_neural_nets.ipynb?hl=zh-cn
提高神经网络性能:编程练习https://colab.research.google.com/notebooks/mlcc/improving_neural_net_performance.ipynb?hl=zh-cn
MNIST 数字分类编程练习https://colab.research.google.com/notebooks/mlcc/multi-class_classification_of_handwritten_digits.ipynb?hl=zh-cn
嵌套编程练习https://colab.research.google.com/notebooks/mlcc/intro_to_sparse_data_and_embeddings.ipynb?hl=zh-cn
艾伯特(http://www.aibbt.com/)让未来触手可及!