新显卡出世,谈谈与深度学习有关的显卡架构和相关技术
欢迎访问Oldpan博客,分享人工智能有趣消息,持续酝酿深度学习质量文。
老婆,我想要煤气炉

显卡的香气
新显卡出世了,就在前几天。
可以说是万众期待下,老黄发布了消费级(民用级)显卡RTX2070、RTX2080、RTX2080TI,作为“大多数人”,不得不说在发布会即将结束的那一刻,真的很想预订一块。真的很有诱惑力啊,毕竟价格摆在那里,RTX2080TI显卡相比1080TI可是贵了许多,Founder Edition 版 京东上预订9999差不多1w了。
好了,先不论价格,来简单看下其参数对比(from https://en.wikipedia.org/wiki/GeForce_20_series)。

重点关注红色剪头指向的指标:
从左到右:流处理器、Tensor Core数量、最低\最高频率、带宽、TFLOP。
详细衡量一下:
最顶级的当然是RTX 2080 Ti,4352个CUDA核心,核心基准频率1350MHz,加速频率公版1545MHz、FE公版超频1635MHz,搭配352-bit 11GB GDDR6显存,带宽616GB/s,整卡功耗260W,8+8针供电,光线追踪性能10 Giga Rays/s、78T RTX-OPS。
接下来是RTX 2080,2944个CUDA核心,核心基准频率1515MHz,加速频率公版1710MHz、FE公版超频1800MHz,搭配256-bit 8GB GDDR6显存,,带宽448GB/s,整卡功耗225W,8+6针供电,光线追踪性能8 Giga Rays/s、60T RTX-OPS。
最后是RTX 2070,2304个CUDA核心,核心基准频率1410MHz,加速频率公版1410MHz、FE公版超频1710MHz,搭配256-bit 8GB GDDR6显存,带宽448GB/s,整卡功耗175W,8针供电,光线追踪性能6 Giga Rays/s、45T RTX-OPS。
大概可以得出这样的结论:流处理器普遍相比上一代多了些,显存大小与上一代一致,显存频率和带宽相比上一代涨了一些。
再看下之前1080TI与1080的报道:
1、二者同为16nm制程、Pascal架构,不同的是GTX 1080为GP104-400核心,GTX 1080 Ti为GP102-350核心。核心面积上GTX 1080 Ti比GTX 1080大了50%,CUDA核心数量也多了近67%,光栅、纹理单元也都有近40%的提升。
2、频率方面:GTX 1080 Ti就没有GTX 1080高了,基础频率1480MHz,Boost频率1584MHz,比GTX 1080低了9%左右。显存方面GTX 1080 Ti和GTX 1080同为GDDR5X,不过显存容量、频率、位宽都有大幅的增长,这也使得GTX 1080 Ti的显存带宽到达了惊人的484GB/s,比Titan X Pascal还高了4GB/s。
3、功耗方面:GTX 1080 Ti额定250W,比GTX 1080多了70W,因此需要8+6 Pin的外接辅助供电来额外提供除PCI-E插槽 75W以外的225W(150+75)。
4、价格方面:GTX 1080 Ti可谓诚意十足,规格上的大幅领先却只比GTX 1080贵了400元,再看和GTX 1080 Ti规格近似的Titan X Pascal就要贵出4000元。不过在GTX 1080 Ti上市后,NVIDIA选择让GTX 1080降价100美元,也算是与GTX 1080 Ti拉开差距。
说完配置,那我们到底需不需要升级2080TI,让我们来讨论下吧。
与深度学习相关
这里我们不讨论最新出的显卡对游戏的提升有多大…blablabla,只知道上2080TI玩游戏玩的更爽就够了,前提是得适配并且用上最新的光线追踪技术(效果见下图)。

光线追踪惊人的“效果”
废话不多少,进入正题,提到显卡,与深度学习相关的也就是并行计算架构、Tensor RT技术以及最近新出的TensorCore了,而流处理的数量以及频率以及带宽则是常规参数,当然是越大越多越硬越好,这里也就不再赘述了。
提提架构
我们平时利用显卡来跑深度学习程序的时候,对显卡架构来说并不用很关心,大部分关于显卡架构的工作,我们的CUDA库和所使用的深度学习库都帮我们处理了,我们平时用的GTX 1080ti、GTX 1080以及所有10系列的显卡,使用的是 Pascal 架构,而最新出来的RTX 2080、RTX 2080ti则使用的是Turning(图灵架构),而之前的服务器级别显卡P100则使用的是Volta架构。
架构不同,计算能力也就不同,计算能力不同显卡支持的运算操作也就不同,我们从NVIDIA的CUDA-document中摘出这么一张图:

其中10系的计算能力是6.1、专业的计算卡P100是6.0、而V100是7.0,最新出来的图灵架构的显卡官网还有没有更新,应该跟CUDA-ToolKit10.0一块出来吧。
很显然上图可以看出,专业的计算卡,在单精度(32-bit)和半精度(16-bit)浮点型计算上都很出众,而我们平时的消费级显卡,例如1080TI(6.1),虽然说支持半精度浮点型计算,但是这数值..相比左右两边的就很寒蝉了。
再看下图,显然,1080TI的F16那一项直接就是N/A,而且,也没有TensorCore。

总结下,虽然说1080TI对16-bit精度的计算支持度并不是很强,但是我们平时训练大部分使用的还是32-bit的精度,只有在inference的时候才会使用16-bit或者8-bit浮点精度,对于我们研究来说,预测的速度区别影响并不是很大。
目前暂时还不知道RTX2080TI的具体参数,如果RTX2080TI对半精度的支持比较强的话,那么都可以和专业的计算卡媲美了。
Tensor Core
之前已经提到了Tensor Core,这个是什么东西,说白了就是比流处理器更强大的专门针对矩阵操作有特别优化的一个运算核。
每个 Tensor Core 包含一个 4x4x4 的矩阵处理阵列来完成 D=A x B + C 的运算,其中 A、B、C、D 是 4×4 的矩阵,如下图。矩阵相乘的输入 A 和 B 是 FP16 矩阵,相加矩阵 C 和 D 可能是 FP16 矩阵或 FP32 矩阵。
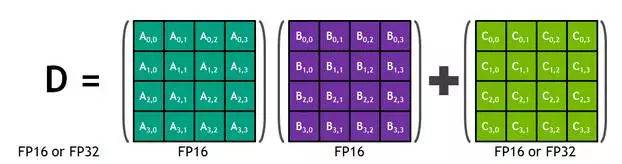
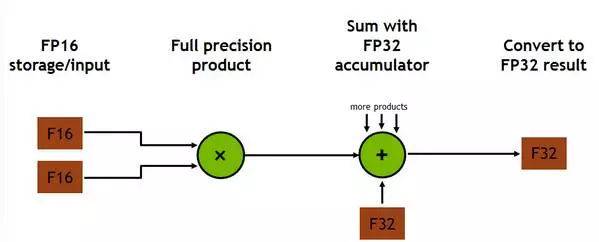
每个 Tensor Core 每个时钟可执行 64 次浮点 FMA 混合精度运算(FP16 乘法与 FP32 累加),一个 SM 单元中的 8 个 Tensor Core 每个时钟可执行共计 1024 次浮点运算。相比于使用标准 FP32 计算的 Pascal GP100 而言,单个 SM 下的每个深度学习应用的吞吐量提升了 8 倍,所以这最终使得 Volta V100 GPU 相比于 Pascal P100 GPU 的吞吐量一共提升了 12 倍。Tensor Core 在与 FP32 累加结合后的 FP16 输入数据之上操作。FP16 的乘法得到了一个全精度结果,该结果在 FP32 和其他给定的 4x4x4 矩阵乘法点积的乘积运算之中进行累加。
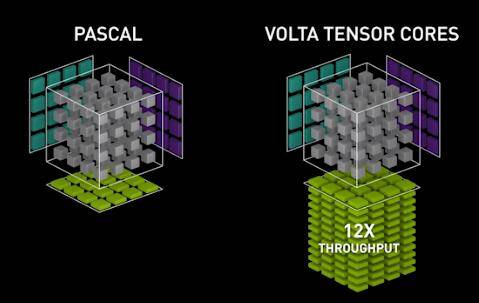
新的Volta GPU架构的显著特征是它的Tensor Core,而最新的Turning架构也拥有Tensor Core,这也大概是为什么这一代RTX比较贵的原因了吧(1080TI没有哦)。
有多快呢?官方宣称有Tensor Core的显卡架构比普通的没有Tensor Core的显卡训练(train)速度最多提升12倍,预测(inference)速度提升6倍。平均差不多3倍的提速,而且这个提速是对32-bit和64-bit精度操作的。

可以说是很强了,速度进一步提升,理论上Tensor Core可以提升计算速度,但是目前的TensorFlow-1.10.0以及Pytorch-0.4.1对Tensor Core的支持有限,还不能完全发挥作用,期待之后的更新吧。
想知道深度学习框架是否支持Tensor Core可以到官方的GITHUB上的release界面查看更新信息。
TensorRT
如果说Tensor Core是一个硬件核,那么TensorRT就相当于一个软件库了,通常作为一个高性能的深度学习推断(inference)的优化器和运行的引擎,是NVIDIA自家开发的。
TensorRT主要的目的是加快推断(inference)的速度,我们在训练模型的时候可以在大型的设备上进行训练,但是如果投入生产实际,我们更多关注的是推断的速度而不是精度,在牺牲一点精度的同时如果可以增加几倍的速度那么就是成功的。
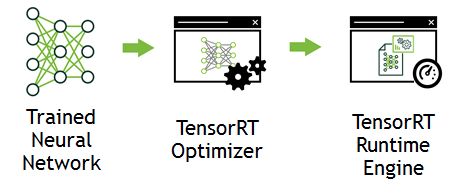
我们把设计好的神经网络利用TensorRT去重新优化设计,变成统一高效的推断网络,对部署阶段有着很好的优化。
当然,作为一个软件核,大部分的显卡都是支持的,但是官方还是建议使用最新的原生支持FP16和INT8型运算的显卡,TensorRT 3版本也开始支持Tensor Core,两者叠加起来,加速能力简直不要不要的。
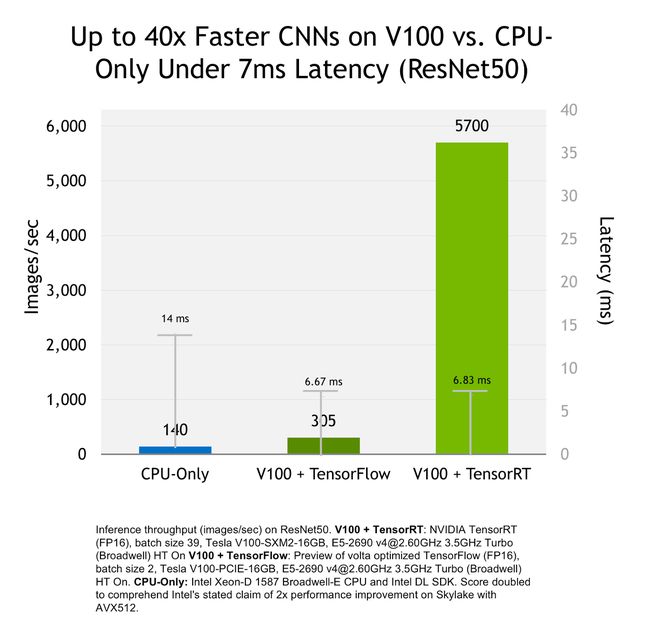
想具体了解的,可以看看 https://yq.aliyun.com/articles/580307 这篇文件,介绍的还是比较详细的。

32-bit和16-bit精度训练推断速度比较
总结
总的来说,如果想要用到最新的Tensor Core技术,那么只有购买服务器级别显卡或者最新出的RTX系列。但是是不是刚需呢? 其实不然,新技术固然可以增加我们训练或推断神经网络的速度,但是提升的这些速度对于我们学生党来说影响并不是很大(当然有钱的除外),更何况兼容性和优化还没有落实到位,我们可以再等一等。
GTX 1080TI和RTX2080TI都是拥有11G显存,RTX 2080TI出世后,如果1080TI适当降价的话,性价比还是非常高的,组个双卡1080TI或许是不错的选择。
参考文章:
http://timdettmers.com/2018/08/21/which-gpu-for-deep-learning/
https://github.com/u39kun/deep-learning-benchmark
https://developer.nvidia.com/tensorrt
https://www.nvidia.com/en-us/data-center/tensorcore/
欢迎关注Oldpan博客微信公众号,同步更新博客深度学习文章。
