注意力机制模块解析(附带代码链接)——SGE(Spatial Group-wise Enhance)
《Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks》
arXiv:https://arxiv.org/abs/1905.09646
github:https://github.com/implus/PytorchInsight
本篇是轻量attention模块的系列之作,它的一个重要的亮点就是同时几乎不增加参数量和计算量的情况下也能让分类与检测性能得到极强的增益。同时,与其他attention模块相比,它是首个利用local与global的相似性作为attention mask的generation source,同时具有非常强的语义表示增强的可解释性。作者认为一个完整的feature是由许多sub feature组成的,并且这些sub feature会以group的形式分布在每一层的feature里,但是这些子特征会经由相同方式处理,且都会有背景噪声影响。这样会导致错误的识别和定位结果。所以作者提出了SGE模块,它通过在在每个group里生成attention factor,这样就能得到每个sub feature的重要性,每个group也可以有针对性的学习和抑制噪声。这个attention factor仅由各个group内全局和局部特征之间的相似性来决定,所以SGE非常轻量级。经由训练之后发现,SGE对于一些高阶语意非常有效。由作者实验发现,它可以显著提高图像识别任务性能。
文章的思路很简单,类似于SENet(可看我之前的解析https://blog.csdn.net/ITOMG/article/details/88804936),除了对通道进行attention,还对空间进行attention。顺序为:
(1)先从channel维度分为group;(2)对每个group进行spacial维度的attention操作。
一句话来概括本文的技术:在每个特征语义组内,利用local与global feature的相似性来指导增强语义特征的空间分布。我们来看核心技术图:
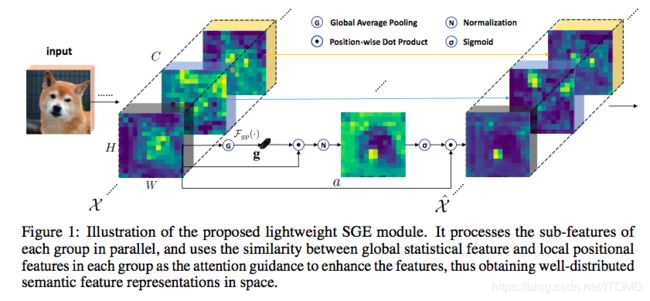
除了将channel划分为多个子特征来表示不同的语义外,还需要考虑卷积特征图中的另一个重要维度:空间。对于特定的语义group,在原始图像的正确空间位置生成相应的语义特征是合理的,也是有益的。但是,由于缺乏对特定区域细节的监控以及图像中可能存在的噪声,语义特征的空间分布会出现一定的混沌,这大大削弱了学习的表示性,使得层次理解的构建变得困难(见图1中的X)。为了使每个特征都能鲁棒,并且在空间上都能产生作用,作者在所有的feature上都做了attention mask。这个attention mask可以减少噪声,并且提高特征语义区域的正确性。不同于其他的attention,作者使用了全局和局部特征的相关性来生成attention mask,所以这个模块几乎没有多余的运算量。具体操作如下:
1、将feature map按channel维度分为G个group;
2、对每个group单独进行attention;
3、对group进行global average pooling得到g;
4、进行pooling之后的g与原group feature进行element-wise dot;
5、在进行norm;
6、再使用sigmoid进行激活;
7、再与原group feature进行element-wise dot。
首先将特征分组,每组feature在空间上与其global pooling后的feature做点积(相似性)得到初始的attention mask,在对该attention mask进行减均值除标准差的normalize,并同时每个组学习两个缩放偏移参数使得normalize操作可被还原,然后再经过sigmoid得到最终的attention mask并对原始feature group中的每个位置的feature进行scale。每个SGE模块引入大约2倍组数个参数,组数一般在32或64,这个数量级基本在大几十。相比于百万级别的CNN而言基本上参数量的增加基本可忽略不计。
这么设计的出发点也很容易理解,作者希望能够增强CNN学到的feature的语义分布,使得在正确语义的region,特征能够突出,而在无关语义的region,特征向量能够尽可能接近0。概念上受Capsule等启发,首先将特征分组,并认为每组特征在学习地过程中能够捕捉到某一个特定的语义。自然地,可以将global的平均feature代表该组学习到的语义向量(至少是接近的,否则该组就都被noise feature dominate了,那后续操作就没有意义了)。接下来,我们用每个position的feature与该global feature做点积,那么根据点积的定义,那些本身模长大的feature以及与global feature向量方向接近的feature就会得到一个较大的初始attention mask数值,这也是我们所期望的。因为不同样本在同一组上求得的attention mask分布差异很大,所以我们需要归一到同样的范围来给出准确的attention。最后,每一个location的feature都会scale上最终的0-1之间的数值。该方法的名称也准确地反应了核心操作:是group-wise地在spatial上enhance了语义feature的分布。
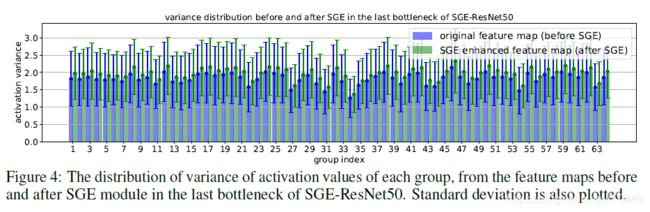
在引入SGE模块后,作者研究了特征图分布的变化以及各组激活值的方差统计。结果表明,SGE显著改善了组内不同语义子特征的空间分布,并产生较大的统计方差,增强了语义区域的特征学习,压缩了噪声和干扰。正如为什么resnext比resnet效果好,resnext也用了group,它的param减少了,Flops增加了。因为很多个group用平行堆叠相同拓扑结构的方式(aggregated transformations)类似于模型融合,所以效果更好。
模块结构
作者把channel分成多个group,每个group都有sub feature,但是我们也注意到,由于噪声和相似特征,特征很难有良好的分布。所以作者利用全局信息来进一步加强关键区域的语义特征学习。在这里作者提到,因为整个空间的特征不受噪声的支配(否则模型从这个组中什么也学不到)。因此用GAP来近似语义向量。(不明白的同学可以看一下SENet的原理解释)
1.所有feature求GAP;
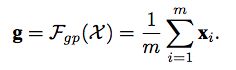
2.得到每个位置的attention;
![]()
3. BN:为了避免不同样本间系数的偏置大小造成的影响;
4. sigmoid,激活赋予权重;
5.对原始输入进行权重点乘;
![]()
该模块放置的位置和SEnet一样,都是每个bottleneck最后一个BN层之后,同时group设为64;
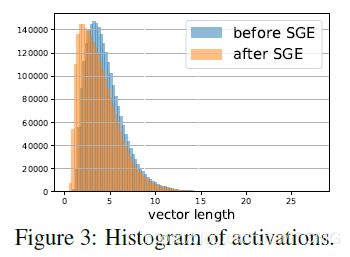
接下来看这个操作是否真的增强了分布。作者用模长代表响应值,将SGE-ResNet50在第4个stage的图像plot出来:
结果显示,尽管只有label的监督,CNN的确非常精准地学习到了一些语义特征,如狗的鼻子,舌头,耳朵,眼睛等等。而且,被SGE增强后的feature map能够更加精准地凸显这些语义区域,完全达到了建模预期的效果。令人惊叹的是,4,7行连闭眼的眼睛SGE都能很好地给capture住。
同时,在最高语义层上,SGE在ImageNet validation set所有50k样本上的统计分布完全符合我们的建模预期:更大的variance,较大的激活保留,较小的激活向0偏移:
接下来就是一波在ImageNet和COCO上的实验了,为了公平比较,统一用pytorch的框架实现,每个实验都是现跑的。在ImageNet上,用ResNet50,ResNet101做backbone,与state-of-the-art的attention module比,性价比非常可观。
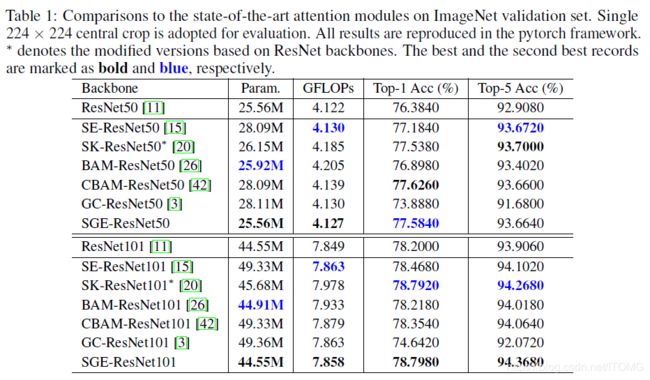
Ablation study告诉我们3个knowledge:
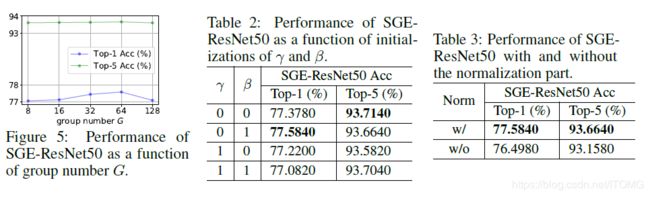
1. Group参数取适中,Top-1性能可到最高;
2. 初始化建议将缩放的参数初始化为0,目的是在attention起到作用前先让网络脱离attention自己学一会,先学习到一个基本的semantic的表示,然后学着学着缩放参数经过梯度下降变成非0之后再渐渐使得attention起到作用;
3. Normalization非常必要,不可去除;
最后是COCO上的实验,首先是在Two-Stage detector上的增益在1~2% AP,相当可观,同时SGE竟然还表现出了遇强则强的状态,在Cascade RCNN的较高的ResNet101的baseline上还能涨接近2个AP:
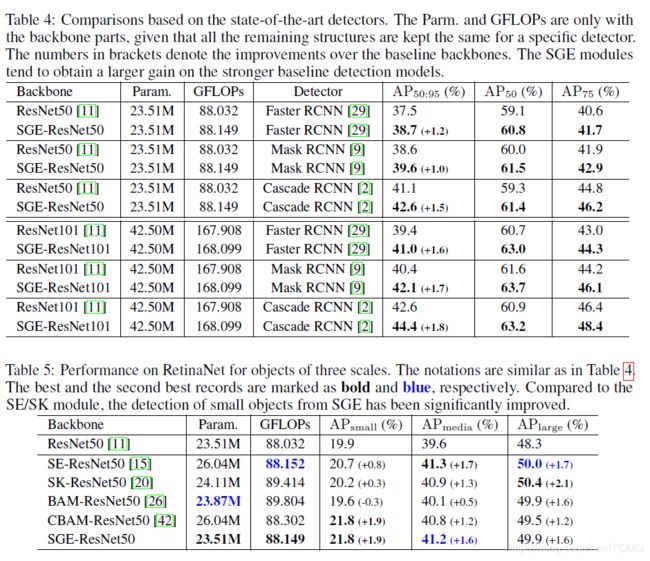
在one-stage的RetinaNet上,在保持media和large与最强的attention module接近的情况下,small object的增益超过了SE/SK 1个点以上,可见其对小区域的空间分布增强带来了非常大的好处。