SqueezeDet:一种应用于自动驾驶实时目标检测中的标准、小型、低功耗的全卷积神经网络(二)
论文原文:SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving
源代码:https://github.com/BichenWuUCB/squeezeDet
论文翻译:XJTU_Ironboy
时间:2017年8月
3. 方法描述
3.1 检测管道(Detection Pipeline)
受到YOLO(You Only Look Once)的启发,我们采用单级的检测管道(detection pipeline),把 region proposition和分类器同时放在一个单独的网络中去实现,正如我们在图1所示:一个卷积神经网络首先将一张图片作为输入,并且从图片中提取一个低分辨率、高维度的特征图,然后这个特征图输入到ConvDet中,来计算在 W×H 空间中均匀分布网格的边界框,此处,W和H是沿水平轴和垂直轴的网格数。

图1 SqueezeDet detection pipeline。一个卷积神经网络从输入图片中提取一个特征图,并且将其输入到ConvDet层中,然后ConvDet层计算在W×H空间中均匀分布网格的边界框,每个边界框和一个置信评分、C个条件分类概率相联系,然后我们保留前N个具有最高置信评分的边界框,并且使用NMS(非最大值抑制)过滤得到最后的检测结果。
每个边界框和C+1个值相联系,其中C是用来分类的概率向量,另外一个值是置信评分(表征边界框中实际包含一个对象的概率)。和YOLO相似,我们将置信评分理解为一个高的置信评分意味着边界框中存在对象的概率较高,预测情况与真实情况吻合程度较高。其他的C个值是假定边界框中有对象存在时该对象的条件分类概率,更正式地说,我们定义这个条件概率为: Pr(classc|Object),c∈[0,1] ,我们将条件概率最大的种类作为这个边界框的标签(lable),并且将 maxcPr(classc|Object)∗Pr(Object)∗IOUpredtruth 作为计算边界框置信度评分的度量。
最后我们保留前N个具有最高置信评分的边界框,使用NMS(非最大值抑制)的方法过滤多余的边界框以获得最终的检测结果。在整个训练过程中,整个检测管道(detection pipeline)仅由一个神经网络的一个前向传递组成,后期处理很少。
3.2 ConvDet
SqueezeDet 的检测管道(detection pipeline)是受YOLO的启发而提出的。但是正如我们在这节所描述,ConvDet层的设计使得SqueezeDet与YOLO相比,能够在更少的模型参数下生成成千上万张 region proposals。
ConvDet层实际上是用来训练输出边界框坐标和分类概率的一个卷积层,它的工作原理类似一个滑动窗口, 在特征图上的每个空间位置移动,在每一个位置,它会计算K x (4+1+C) 个值来对边界框预测情况进行编码。此处,K是具有预先选定形状的引用边界框的数目。使用Girshick 提出的概念,我们称这些引用边界框为锚(anchor) ,特征图的每一个位置在原图上对应一个网格,所以每个anchor可由四个标量来描述 (xˆi,yˆj,wˆk,hˆk) 。此处, xˆi,yˆj 是网格中心(i , j)的坐标, wˆk,hˆk 是引用边界框的宽和高。我们用参考文献[2]中所描述的方法来选定符合数据分布的引用边界框的形状。
对于每一个anchor( i, j, k),我们计算四个相关的坐标 (δxijk,δyijk,δwijk,δhijk) 来将anchor转换成可预测的边界框,正如图2所示,这种转换由以下的数学公式来描述:
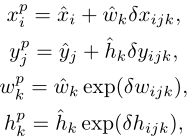
其中 xG,yG,wG,hG 是预测边界框框的坐标。
正如前面的解释,对于每个 anchor的其他 C+1个输出实质是将置信评分和分类概率进行了编码。

图2 边界框转换,每一个网格中心都有已经确定形状的K个anchor,然后使用 ConvDet 层计算的相对坐标将每个锚点转换为新的位置和形状。每一个anchor与一个置信评分和分类概率联系。
ConvDet和Faster R-CNN中RPN的最后一层相似。主要的区别就是,RPN 被认为是一个很弱的检测器,它只能检测目标是否存在并且为这个对象生成边界框,分类就交给了全连接层(全连接层被视为是一种很强的分类器),但实际上,卷积层也是足够强大,可以同时检测、定位和分类对象。
为了简单起见,我们将YOLO的检测层视为FcDet(只计算最后两个全连接层),与 FcDet 相比, ConvDet 层具有数量较少的参数, 并且仍然能够生成更高空间分辨率的区域方案, ConvDet 和 FcDet的对比在图3中。
假定输入的特征图的尺寸是 (Wf,Hf,Chf) ,其分别是长、宽、通道数,ConvDet的滤波器的宽和高为 (Fw,Fh) ,通过适当的padding/strides策略, 可以使得ConvDet 的输出与特征保持相同的空间维度。为了去计算每个引用网格的 K×(4+1+C) 个输出,ConvDet层需要的参数的数量是 Fw×Fh×Chf×K×(C+5) 。
FcDet 是由两个全连接层组成。假定 Fc1 层的输出特征图的数量记为 Ffc1 ,则Fc1层参数的数量为 Wf×Hf×Chf×Ffc1 ,第二个全连接层生成C个分类概率、 K×(4+1) 个边界框和给每一个 W×H 的网格生成的置信评分,因此 Fc2 层参数的数量为 Ffc1×W0×H0×(5K+C) ,两层参数的总的数量为 Ffc1×(Wf×Hf×Chf+W0×H0×(5K+C)) 。

在YOLO中,其输入特征图的尺寸是 7×7×1024 , Ffc1=4096 , K=2 , C=20 , W=H=7 ,因此这两层全连接层的总数量大约是 212×106 ,如果我们保持特征图的大小,输出网格的数量,分类数目和anchor不变,并且使用3 x 3的ConvDet,将需要 0.46×106 个参数,比FcDet小460倍, RPN、ConvDet 和 FcDet的具体描述在图3中,其对比结果的总结在上面的表1中。
3.3 训练方法
和 Faster R-CNN不一样,Faster R-CNN需要部署一个(4-step)的交替训练策略(来训练RPN)和探测器网络,而我们的SqeezeDet检测网络和YOLO相似,可以实现端对端训练。
为了训练ConvDet层来学习检测、定位、分类,我们定义了一个多任务的损失函数:
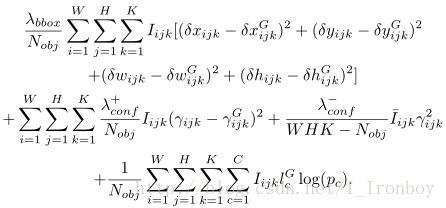
这损失函数的第一部分是边界框回归函数,各变量的微分形式对应于位于网格中心 (i,j) 的 anchor-k 的相对坐标,它们是 ConvDet层的输出,对应于真实情况的边界框可以如下计算:
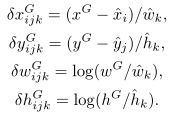
这个等式其实是第一个等式的反变换,各个变量表示的是对应于真实情况的边界框的坐标。在训练过程中, 我们将真实边界框与所有的锚点( anchor)进行比较, 并将它们分配给具有最大重叠 ( IOU) 的 anchor。原因是, 我们要选择 “最接近” 的 anchor匹配的真实边界框, 这样的转换需要减少到最低。如果在位置 (i,j) 上的第K个 anchor与真实边界框有最大的重叠,那么相应的 Iijk 评价为1,否则为0。这样, 我们只需要包括由 “ responsible” 的 anchor产生的损失。由于每个图像可以有多个对象, 因此我们通过将它除以对象数来规范化损失。
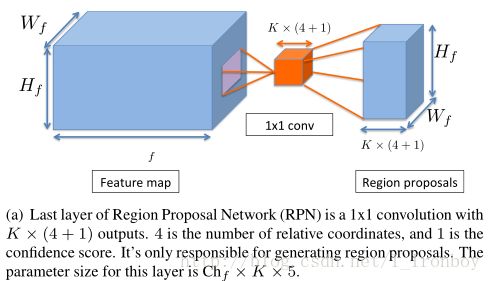
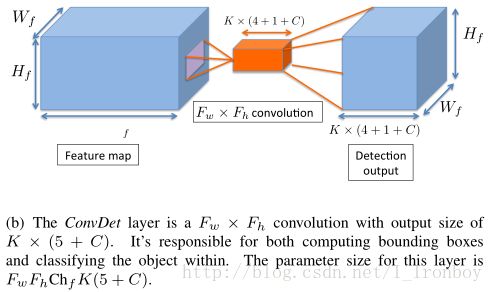
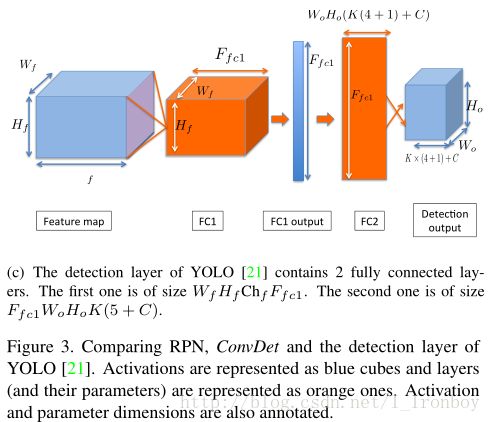
图3 和RPN相比,YOLO的ConvDet和Detection 层。Activations 表示为蓝色立方体,层 (及其参数) 表示为橙色的。Activations 和参数尺寸也被标注。
这个损失函数的第二部分是置信评分回归函数, γijk 是ConvDet层的输出,表示在位置 (i,j) 上的第K个anchor的置信评分的预测值, γijk 是通过计算预测边界框和真实边界框之间的重叠部分中得到的。和上面相同,我们只包括由anchor产生的损失与真实情况的最大重叠。对于那些在检测中不可信的anchor,我们用 I¯ijkγ2ijk 项来惩罚他们,其中 I¯ijk=1−Iijk 。通常情况下,有大量的anchor没有包括任何对象,为了平衡他们的影响,我们引入了 λ+conf 和 λ−conf 项来调整这两个损失函数的权重,通过定义可以,置信评分的取值范围是[0,1]。为了保证 γijk 的值能落入这个区间,我们将ConvDet层的输出通过一个sigmoid函数来使其标准化。
这个损失函数的最后一部分是分类的交叉熵函数(cross entropy), lcG 是真实标签, pc 是网络预测,我们用softmax来使相应的ConvDet层的输出标准化来保证 pc 的值都落在[0,1]。
公式2中的超参数都是经过实际赋值的,在我们的实验中, λbbox=5 , λ+conf=75 , λ−conf=100 ,损失函数使用BP算法进行优化。
3.4 神经网络结构设计
在这节之前,我们已经介绍了检测管道、ConvDet层、端对端的训练方法。这些方法都是通用的,并且和各种不同的CNN结构,包括 VGG16、ResNet等等。当选择核心的CNN结构的时候,我们的关注点主要在于模型的大小和能量利用效率,那么SqueezeNet是我们的首选。
Model size: SqueezeNet的建立基于Fire模块(由一个作为输入的squeeze层和两个并联作为输出的expand层构成),其中squeeze层是由1 x 1的卷积层构成,其作用是将具有大的通道数的输入张量压缩成同样batch和空间维度,但具有更少通道数的输出张量。而expand层是由1 x 1的卷积核与3 x 3的卷积核混合而成,他们将前面压缩的张量作为输入,重新恢复其中的丰富特征,并且输出一个具有更大通道数的 activation tensor ,squeeze层和expand层交替使用的方法在不损失较大准确度的情况下非常高效地降低了模型的参数量。
Energy efficiency: 在神经网络前向运行过程中,不同的操作对能耗的需求是不一样的。其中资源消耗最大的是DRAM的连接,它是SRAM能量消耗的100倍并且执行浮点运算,因此我们尽可能希望减少DRAM的连接。
减少DRAM连接的最简单的方法是使用小的模型,从而减少参数的存储。一个减少模型参数的高效的方法是尽可能使用卷积层而不是全连接层,卷积层的参数只需要访问一次, 并可在输入数据 (如果 batch>1) 的所有邻区重复使用。然而,全连接层只在“batch”的维度下才能重复使用参数,它的每个参数仅在输入数据的一个邻域中使用。除了模型大小之外,另一个很重要的方面是控制中间激活层的大小。假定计算硬件的SRAM的大小是16MB,SqueezeNet模型的大小是5MB,如果任何两个连续层的激活输出的总大小小于11MB,则所有内存访问都可以在 SRAM 中完成, 不需要 DRAM 访问。详细的能效讨论将在本文末尾的补充材料提供(不予翻译,可参考原文文末,望见谅)。
在这篇论文中,我们采用了两种版本的SqueezeNet结构。第一种结构是SqueezeNet v1.1模型,模型大小是4.72MB, 在ImageNet top-5上的准确度超过80.3%。第二个是一个更强大版本的SqueezeNet结构,它的挤压比是0.75,模型大小是19MB,在ImageNet top-5上的准确度为86%。在本论文中,我们把第一种结构称为SqueezeNet,第二种结构是SqueezeNet+。我们预先在ImageNet分类数据库中训练了这两种结构,并且把两个随机初始化权重的fire模块放在预先训练的模型的最上层,然后将它和ConvDet层连接。
由于本论文较长,中文翻译分为几个部分连载:
SqueezeDet:一种应用于自动驾驶实时目标检测中的标准、小型、低功耗的全卷积神经网络(一)
SqueezeDet:一种应用于自动驾驶实时目标检测中的标准、小型、低功耗的全卷积神经网络(三)
注:第一次写博客,且水平有限,有些地方翻译的很不到位,望谅解!
如有问题需要讨论,可发送问题到我的邮箱:[email protected]