Hadoop实践 | VMware搭建Hadoop伪分布模式
-
- 准备工作
- 设置java和hadoop环境变量
- SSH无密连接
- 配置Hadoop
- 启动hadoop
环境:物理机Win10 VMware14 虚拟机Ubuntu16.04LTS
准备工作
建立三台虚拟机,用户名需要相同(本文使用的jackherrick),主机名推荐master slave1 slave2
安装VMware Tools,一是为了虚拟机屏幕的自适应,二是为了使用共享文件夹
设置共享文件夹
切换到中国的软件源,更新软件源并升级软件
sudo vi /etc/apt/sources.list# deb cdrom:[Ubuntu 16.04 LTS _Xenial Xerus_ - Release amd64 (20160420.1)]/ xenial main restricted
deb-src http://archive.ubuntu.com/ubuntu xenial main restricted #Added by software-properties
deb http://mirrors.aliyun.com/ubuntu/ xenial main restricted
deb-src http://mirrors.aliyun.com/ubuntu/ xenial main restricted multiverse universe #Added by software-properties
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted multiverse universe #Added by software-properties
deb http://mirrors.aliyun.com/ubuntu/ xenial universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb http://mirrors.aliyun.com/ubuntu/ xenial multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverse #Added by software-properties
deb http://archive.canonical.com/ubuntu xenial partner
deb-src http://archive.canonical.com/ubuntu xenial partner
deb http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted multiverse universe #Added by software-properties
deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-security multiverse 下载好jdk-8u11-linux-x64.tar.gz hadoop-2.7.5.tar.gz,放到共享文件夹
将这两个文件夹解压到三台虚拟机
sudo tar -zxvf /mnt/hgfs/share/jdk-8u131-linux-x64.tar.gz -C /usr/lib
tar -zxvf /mnt/hgfs/share/hadoop-2.7.3.tar.gz -C ~/设置java和hadoop环境变量
写入环境变量
sudo vi /etc/profileexport JAVA_HOME=/usr/lib/jdk1.8.0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
export HADOOP_HOME=/home/jh/hadoop-2.7.3
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_MAPARED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/Hadoopsource /etc/profilejava-version
hadoop version重启虚拟机,接下来后面的工作
SSH无密连接
SSH连接和SSH无密连接的原理,小白可以先梳理过程
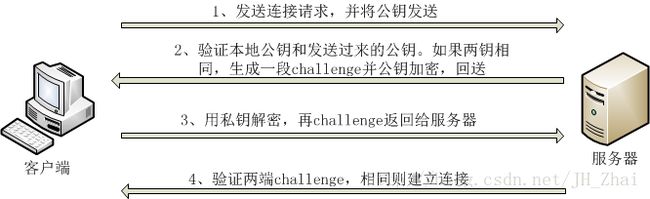
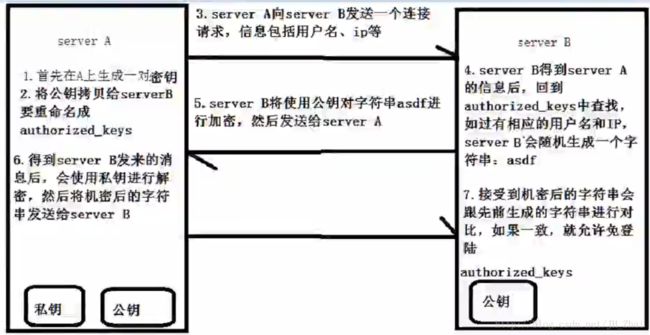
具体实施就是对三台虚拟机一台一台重复,
#安装openssh-server
sudo apt-get install openssh-server#生成密钥
ssh-keygen -t rsa -P ''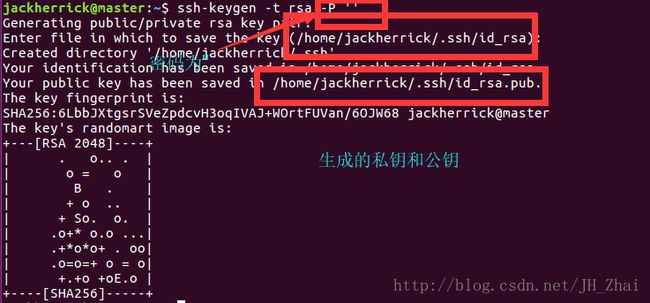
#三台虚拟机生成的公钥放到共享文件夹,然后写入authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
cat /mnt/hgfs/share/id_rsa1.pub >> ~/.ssh/authorized_keys
cat /mnt/hgfs/share/id_rsa2.pub >> ~/.ssh/authorized_keys测试,在虚拟机master连接虚拟机slave1
ssh slave1 配置Hadoop
#建立文件夹
mkdir ~/dfs ~/tmp
mkdir ~/dfs/data ~/dfs/name配置文件1:environment
vi /etc/environment
#在文件的结尾""之内加上
:/home/jackherrick/hadoop-2.7.3/bin
:/home/jackherrick/hadoop-2.7.3/sbin这样执行start-dfs.sh等脚本就不用输路径前缀了
配置文件件2:hadoop-env.sh
vi ~/hadoop-2.7.3/etc/hadoop/hadoop-env.sh# The java implementation to use.
export JAVA_HOME=/usr/lib/jdk1.8.0_131配置文件3:yarn-env.sh
vi ~/hadoop-2.7.3/etc/hadoop/yarn-env.shexport JAVA_HOME=/usr/lib/jdk1.8.0_131配置文件4:slaves (这个文件里面保存所有slave节点)
vi ~/hadoop-2.7.3/etc/hadoop/slavesslave1
slave2配置文件5:core-site.xml
vi ~/hadoop-2.7.3/etc/hadoop/core-site.xml<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/home/jh/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>hadoop.proxyuser.hduser.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.hduser.groupsname>
<value>*value>
property>
configuration>
配置文件6:hdfs-site.xml
vi ~/hadoop-2.7.3/etc/hadoop/hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:9001value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/home/jh/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/home/jh/dfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>
配置文件7:mapred-site.xml
这个文件之前没有,所以新建立的话还需要把文件头加上
vi ~/hadoop-2.7.3/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value> master:19888value>
property>
configuration>
配置文件8:yarn-site.xml
vi ~/hadoop-2.7.3/etc/hadoop/yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value> master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value> master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value> master:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value> master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value> master:8088value>
property>
configuration>
将配置直接复制到其他机器
scp -r ~/hadoop-2.7.3 slave1:~/
scp -r ~/hadoop-2.7.3 slave2:~/启动hadoop
格式化namenode:hadoop namenode –format(不是hdfs namenode –format) 真的是日了泰迪,查了半天错
只有第一次需要格式化
启动hdfs: start-dfs.sh
小插曲
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决方案是在文件hadoop-env.sh中增加:
export HADOOP_OPTS=”-Djava.library.path=${HADOOP_HOME}/lib/native”
使用命令jps查看进程
此时在master上面运行的进程有:namenode secondarynamenode
slave1和slave2上面运行的进程有:datanode
启动yarn: ./sbin/start-yarn.sh
此时在master上面运行的进程有:namenode secondarynamenode resourcemanager
slave1和slave2上面运行的进程有:datanode nodemanaget
关闭hadoop
/usr/local/hadoop-2.7.5/sbin/stop-all.sh
也可以通过浏览器访问,比如
http://192.168.201.128:9001/status.html