卷积神经网络(CNNs)的体系结构揭秘
介绍
我将从坦白开始 - 有一段时间我并不真正理解深度学习。我会看一下关于这个主题的研究论文和文章,觉得这是一个非常复杂的话题。我尝试了解神经网络及其各种类型,但看起来仍然很困难。
然后有一天,我决定一步一步。我决定从基础开始并以它们为基础。我决定打破这些技术中应用的步骤并手动执行步骤(和计算),直到我理解它们是如何工作的。这是时间和努力 - 但结果是惊人的。
现在,我不仅可以理解深度学习的范围,还可以想象事物,并提出更好的方法,因为我的基本原理很清楚。盲目地应用神经网络是一回事,而另一方面是了解发生了什么以及后面发生了什么事情。
今天,我将与你分享这个秘方。我将向您展示我如何使用卷积神经网络并对其进行研究直到我理解它们为止。我将引导您完成旅程,以便您深入了解CNN如何工作。
在本文中,我将讨论卷积神经网络背后的架构,它旨在解决图像识别和分类问题。
我假设您对神经网络的工作原理有基本的了解。
目录:
- 机器如何看待图像?
- 我们如何帮助神经网络识别图像?
- 定义卷积神经网络
- 卷积层
- 池层
- 输出层
- 把它们放在一起
- 使用CNN对图像进行分类
1.机器如何看待图像?
人脑是一台非常强大的机器。我们每秒看到(捕获)多个图像并处理它们,而没有意识到处理是如何完成的。但是,机器并非如此。图像处理的第一步是了解如何表示图像以便机器可以读取它?
简单来说,每个图像是以特殊顺序排列的点(像素)的排列。如果更改像素的顺序或颜色,图像也会更改。让我们举个例子。让我们说,你想存储和读取一个写有数字4的图像。
机器将基本上将该图像分成像素矩阵,并将代表位置处的每个像素的颜色代码存储起来。在下面的表示中 - 数字1是白色,256是最暗的绿色(为了简单起见,我将示例限制为只有一种颜色)。
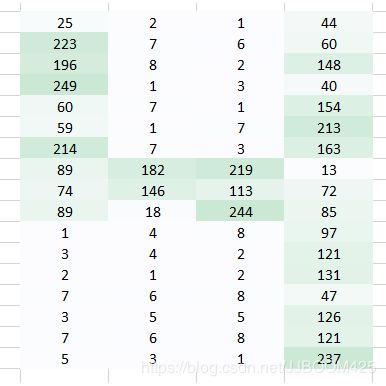
一旦您以这种格式存储图像,下一个挑战是让我们的神经网络理解排列和模式。
2.我们如何帮助神经网络识别图像?
通过使像素以特定方式排列来形成数字。
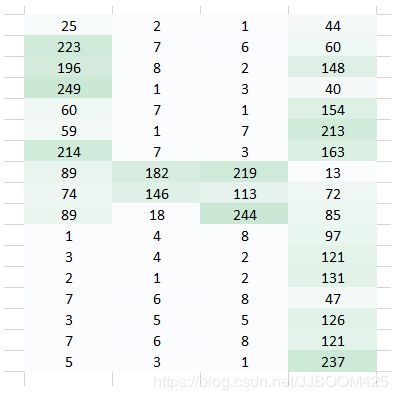
假设我们尝试使用完全连接的网络来识别它?它有什么作用 ?
完全连接的网络将该图像作为阵列进行展平,并将像素值视为预测图像数量的特征。毫无疑问,网络很难理解底层正在发生的事情。
![]()
即使是人类也不可能确定这是4号的表示。我们完全失去了像素的空间排列。
我们可以做些什么?让我们尝试从原始图像中提取特征,以便保留空间排列。
情况1:
这里我们使用权重来乘以初始像素值。
肉眼确实更容易识别出这是4.但是再次将此图像发送到完全连接的网络,我们必须将其展平。我们无法保留图像的空间排列。
![]()
案例2:
现在我们可以看到,压平图像完全破坏了它的排列。我们需要设计一种方法将图像发送到网络而不会使它们变平并保留其空间排列。我们需要发送像素值的2D / 3D排列。
让我们一次尝试拍摄图像的两个像素值,而不是只拍摄一个像素值。这将使网络非常好地了解相邻像素的外观。现在我们一次采用两个像素,我们也将采用两个权重值。
我希望你注意到图像现在变成了最初的4列排列的3列排列。图像变得更小,因为我们现在一次移动两个像素(像素在每个移动中被共享)。我们使图像更小,我们仍然可以理解它在很大程度上是4。另外,要实现的一个重要事实是我们采用两个连续的水平像素,因此这里只考虑水平排列。
这是从图像中提取特征的一种方法。我们能够很好地看到左侧和中间部分,但右侧不是那么清晰。这是因为以下两个问题 -
- 图像的左右角仅与权重相乘一次。
- 左侧部分仍保留,因为重量值较高,而右侧部分由于重量较轻而略微丢失。
现在我们有两个问题,我们将有两个解决方案来解决它们。
案例3:
遇到的问题是图像的左右角只有一次通过重量。我们需要做的是我们需要网络像其他像素一样考虑角落。
我们有一个简单的解决方案来解决这个问 沿着重量运动的两侧放置零。
您可以看到,通过添加零,保留了角落中的信息。图像的大小也更高。这可以在我们不希望图像尺寸减小的情况下使用。
案例4:
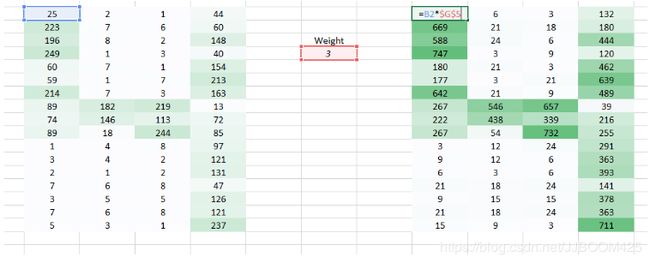
我们在这里要解决的问题是,右侧角落的较小权重值会降低像素值,从而使我们难以识别。我们能做的是,我们在一个转弯中采用多个重量值并将它们组合在一起。
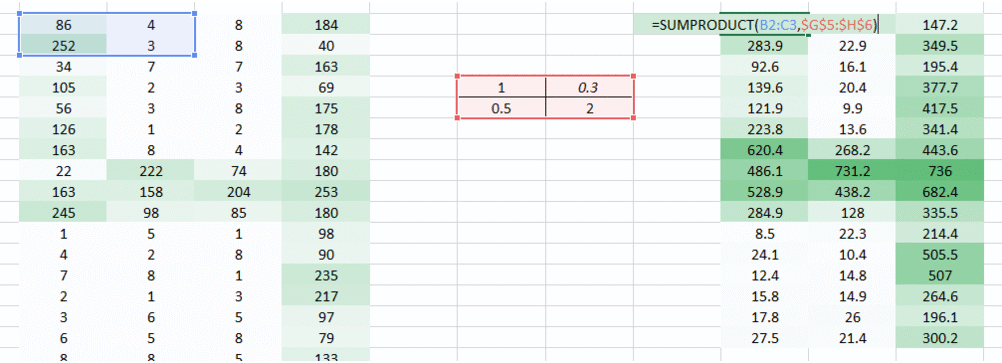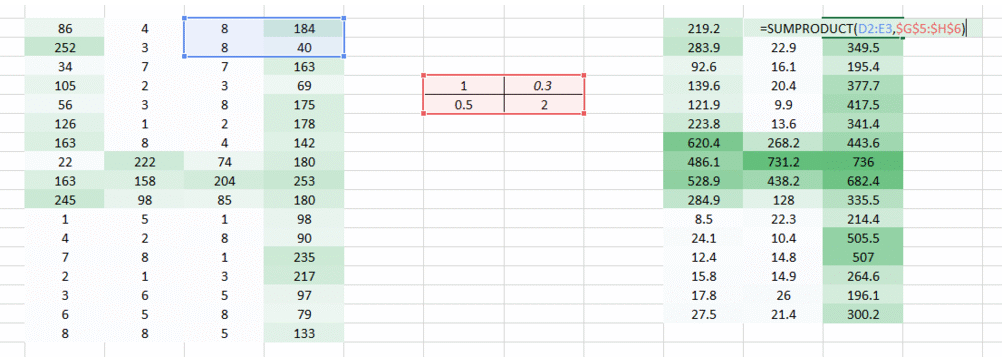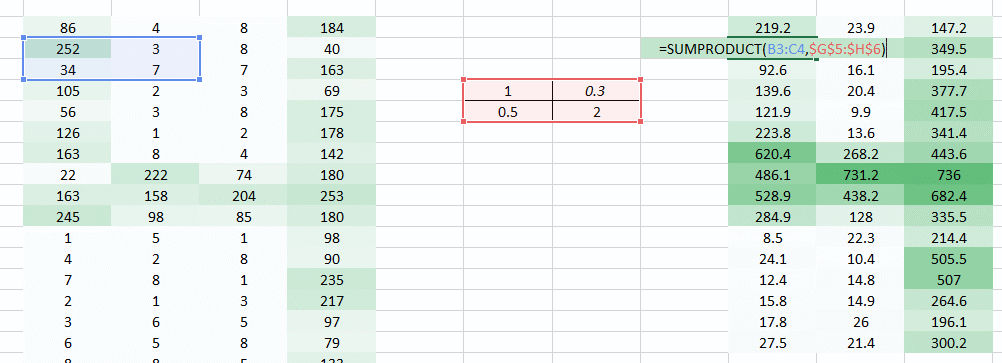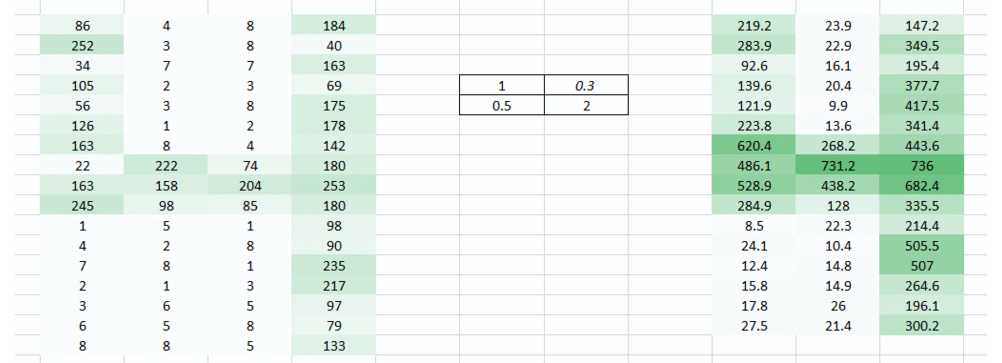
权重值(1,0.3)给出了表格的输出
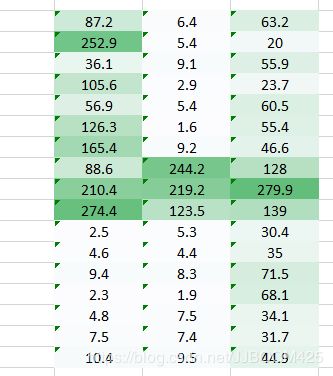
而形式的重量值(0.1,5)将为我们提供表格的输出
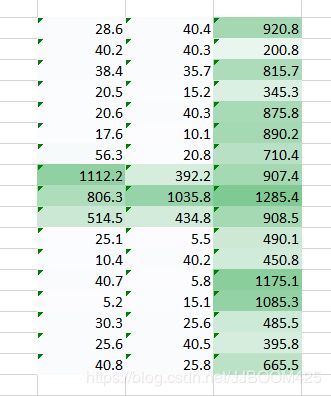
这两个图像的组合版本将给我们一个非常清晰的画面。因此,我们所做的只是使用多个权重而不仅仅是一个来保留有关图像的更多信息。最终输出将是上述两个图像的组合版本。
案例5:
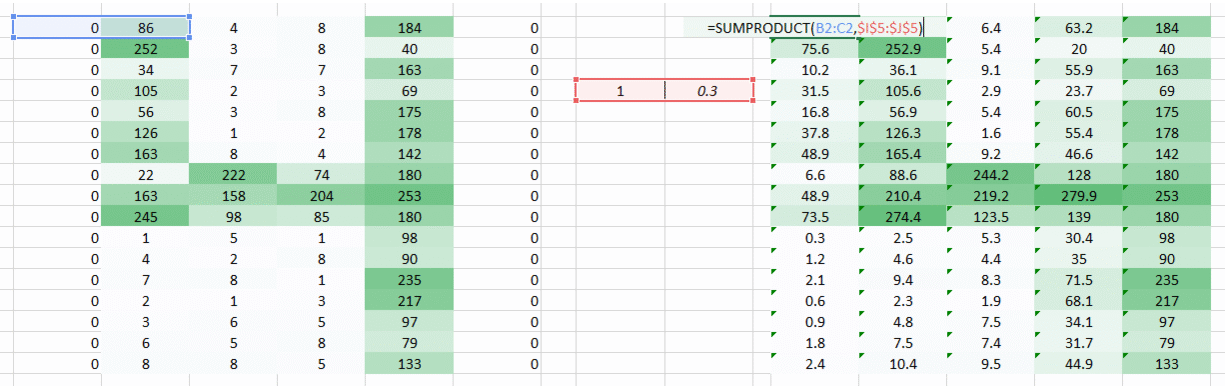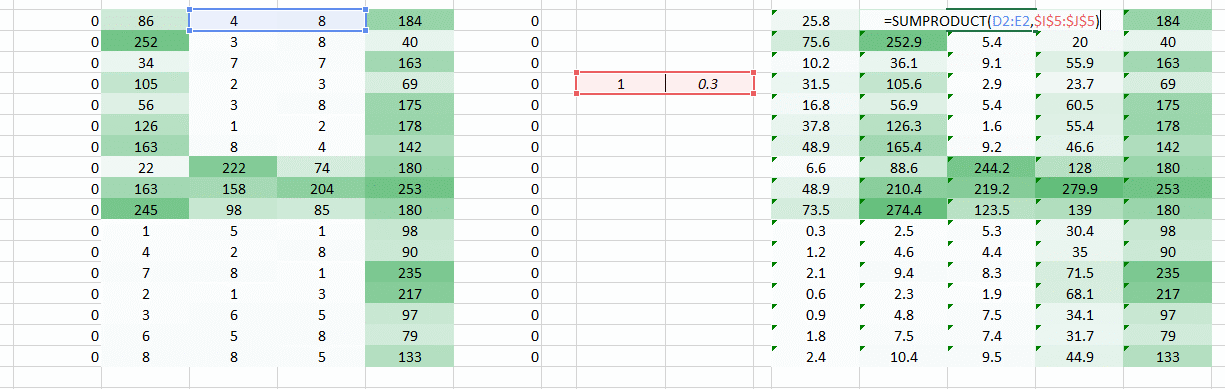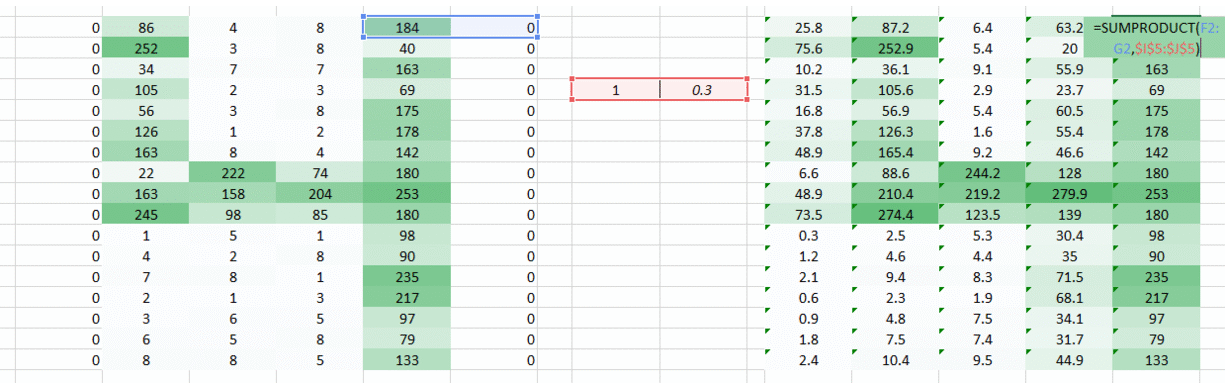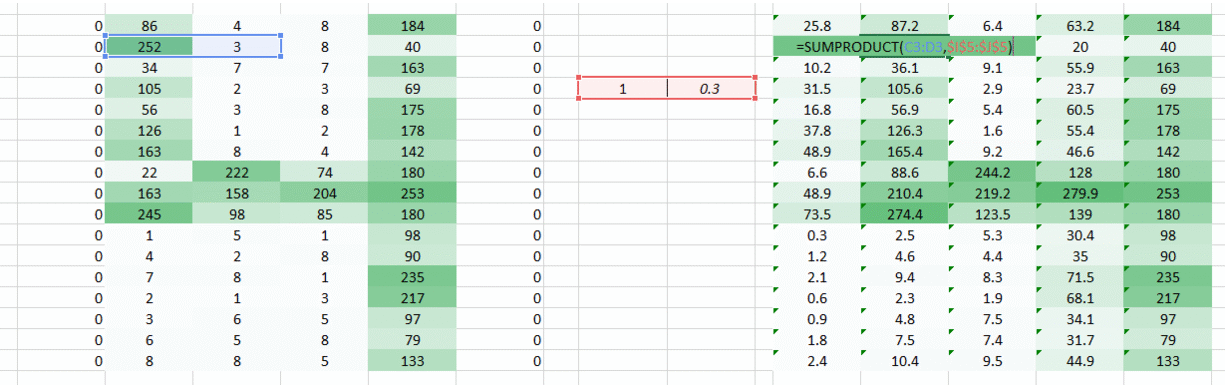
直到现在我们已经使用了试图将水平像素放在一起的权重。但在大多数情况下,我们需要保持水平和垂直方向的空间布局。我们可以将权重作为2D矩阵,在水平和垂直方向上将像素聚集在一起。另外,请记住,由于我们已经进行了权重的水平和垂直移动,因此输出在水平和垂直方向上都低一个像素。
那我们做了什么?
我们上面做的是我们试图通过使用图像的空间排列从图像中提取特征。要理解图像,网络对于了解像素的排列方式至关重要。我们上面所做的是卷积神经网络究竟是做什么的。我们可以获取输入图像,定义权重矩阵,并对输入进行卷积以从图像中提取特定特征,而不会丢失有关其空间排列的信息。
这种方法的另一个好处是它减少了图像中的参数数量。如上所述,与原始图像相比,卷积图像具有较小的像素。这大大减少了我们需要为网络训练的参数数量。
3.定义卷积神经网络
我们需要三个基本组件来定义基本的卷积网络。
- 卷积层
- Pooling层[可选]
- 输出层
让我们更详细地看一下这些内容
2.1卷积层
在这一层中,所发生的正是我们在上面的案例5中看到的。假设我们有一个大小为6 * 6的图像。我们定义一个权重矩阵,从图像中提取某些特征
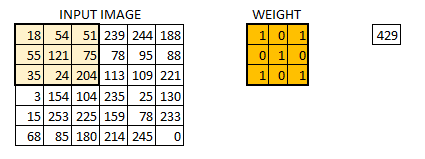
我们将重量初始化为3 * 3矩阵。现在,该权重将在图像上运行,使得所有像素至少被覆盖一次,以给出卷积输出。上面的值429是通过将权重矩阵的元素乘法和输入图像的突出显示的3 * 3部分相加而获得的值。
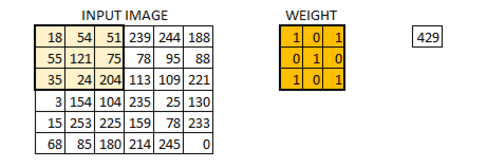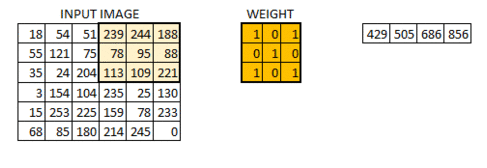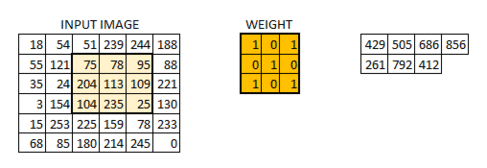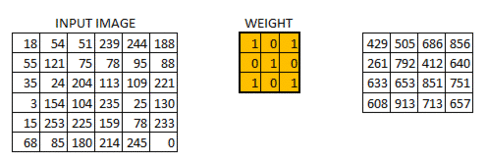
6 * 6图像现在转换为4 * 4图像。把重量矩阵想象成画在墙上的画笔。画笔首先水平地绘制墙壁,然后下降并水平地绘制下一行。当权重矩阵沿图像移动时,再次使用像素值。这基本上使得能够在卷积神经网络中进行参数共享。
让我们看看它在真实图像中的样子。

权重矩阵表现得像是从原始图像矩阵中提取特定信息的图像中的滤波器。权重组合可能是提取边缘,而另一个可能是特定颜色,而另一个可能只是模糊不需要的噪音。
学习权重使得损失函数与MLP类似地最小化。因此,学习权重以从原始图像中提取特征,这有助于网络进行正确的预测。当我们有多个卷积层时,初始层提取更多通用特征,而随着网络越来越深入,权重矩阵提取的特征越来越复杂,越来越适合手头的问题。
步幅和填充的概念
如上所述,滤镜或权重矩阵在整个图像中移动,一次移动一个像素。我们可以将其定义为超参数,以及我们希望权重矩阵如何在图像上移动。如果权重矩阵一次移动1个像素,我们将其称为1的步幅。让我们看看2的步幅如何。
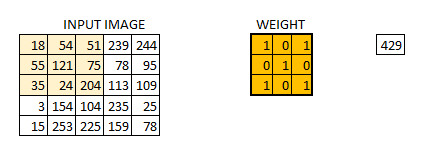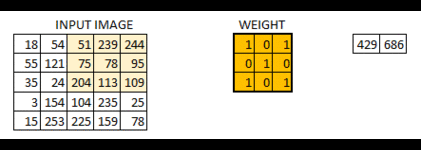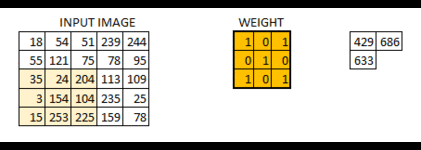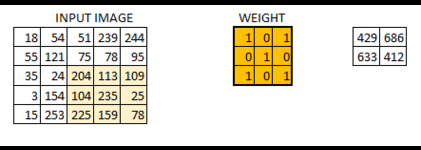
正如您所看到的那样,随着我们增加步幅值,图像的大小会不断减小。用输入的零填充输入图像为我们解决了这个问题。如果步幅值较高,我们还可以在图像周围添加多个零。
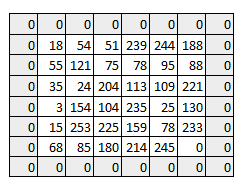
我们可以看到在用零填充图像后如何保留图像的初始形状。这被称为相同的填充,因为输出图像具有与输入相同的大小。

这称为相同的填充 (这意味着我们只考虑输入图像的有效像素)。中间4 * 4像素将是相同的。在这里,我们从边框保留了更多信息,并保留了图像的大小。
多个过滤器和激活映射
要记住的一件事是,重量的深度尺寸与输入图像的深度尺寸相同。重量延伸到输入图像的整个深度。因此,使用单个权重矩阵的卷积将导致具有单个深度维度的卷积输出。在大多数情况下,我们将多个相同尺寸的滤波器应用于一起,而不是单个滤波器(权重矩阵)。
来自每个滤波器的输出堆叠在一起,形成卷积图像的深度尺寸。假设我们有一个大小为32 * 32 * 3的输入图像。我们使用有效填充应用10个大小为5 * 5 * 3的过滤器。输出的尺寸为28 * 28 * 10。
您可以将其可视化为 -

2.2汇集层
有时当图像太大时,我们需要减少可训练参数的数量。然后期望在后续卷积层之间周期性地引入汇集层。进行池化的唯一目的是减小图像的空间大小。在每个深度维度上独立地进行池化,因此图像的深度保持不变。通常应用的最常见的池化层形式是最大池化。
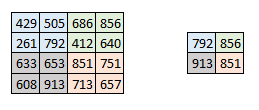
这里我们采取步幅为2,而池大小也为2.最大操作应用于卷积输出的每个深度维度。如您所见,在最大池操作之后,4 * 4卷积输出变为2 * 2。
让我们看看最大池在真实图像上的外观。

正如您所看到的,我已经采用了复杂的图像,并在其上应用了最大池。最大合并图像仍保留其在街道上的汽车信息。如果仔细观察,图像尺寸减半时的尺寸。这有助于在很大程度上减少参数。
类似地,也可以应用其他形式的池,如平均池或L2标准池。
输出尺寸
您可能会对每个卷积层末尾的输入和输出维度有所疑惑。我决定采用这几行来使您能够识别输出尺寸。三个超参数将控制输出量的大小。
- 过滤器的数量 - 输出量的深度将等于应用的过滤器的数量。记住我们如何堆叠每个过滤器的输出以形成激活图。激活图的深度将等于过滤器的数量。
- 跨步 - 当我们有一个跨步时,我们在一个像素上移动和移动。通过更高的步幅值,我们一次移动大量像素,从而产生更小的输出量。
- 零填充 - 这有助于我们保留输入图像的大小。如果添加单个零填充,则单个步幅滤镜移动将保留原始图像的大小。
我们可以应用一个简单的公式来计算输出尺寸。输出图像的空间大小可以计算为([W-F + 2P] / S)+1。这里,W是输入音量大小,F是滤波器的大小,P是应用的填充数,S是步幅数。假设我们有一个尺寸为32 * 32 * 3的输入图像,我们应用10个尺寸为3 * 3 * 3的滤波器,单步幅且没有零填充。
这里W = 32,F = 3,P = 0且S = 1。输出深度将等于应用的滤波器数量,即10。
输出音量的大小为([32-3 + 0] / 1)+1 = 30.因此输出音量为30 * 30 * 10。
2.3输出层
在多层卷积和填充之后,我们需要以类的形式输出。卷积和池化层只能提取特征并减少原始图像中的参数数量。但是,要生成最终输出,我们需要应用完全连接的层来生成一个等于我们需要的类数的输出。仅使用卷积层就很难达到这个数字。卷积层生成3D激活图,而我们只需要输出图像是否属于特定类。输出层具有类似于分类交叉熵的损失函数,以计算预测中的误差。一旦前向传递完成,反向传播就开始更新重量和偏差以减少误差和损失。
3.将所有内容放在一起 - 整个网络如何?
您现在可以看到的CNN由各种卷积和池化层组成。让我们看看网络是怎样的。

- 我们将输入图像传递给第一个卷积层。获得卷积输出作为激活图。在卷积层中应用的滤波器从输入图像中提取相关特征以进一步传递。
- 每个滤波器应提供不同的特征以帮助正确的类预测。如果我们需要保留图像的大小,我们使用相同的填充(零填充),使用其他明智的有效填充,因为它有助于减少功能的数量。
- 然后添加池化层以进一步减少参数的数量
- 在进行预测之前添加几个卷积和池化层。卷积层有助于提取特征。随着我们在网络中更深入,与提取的特征更通用的浅网络相比,提取了更具体的特征。
- 如前所述,CNN中的输出层是完全连接的层,其中来自其他层的输入被平坦化并被发送,以便将输出转换为网络所需的类的数量。
- 然后通过输出层生成输出,并将其与输出层进行比较以生成错误。在完全连接的输出层中定义损耗函数以计算均方损失。然后计算误差梯度。
- 然后反向传播该错误以更新滤波器(权重)和偏差值。
- 一个训练周期在单个前进和后退中完成。
4.使用CNN对KERAS中的图像进行分类
让我们尝试一个例子,我们输入几个猫和狗的图像,我们尝试将这些图像分类到各自的动物类别。这是图像识别和分类的经典问题。机器需要做的是它需要看到图像并通过各种功能来理解它是猫还是狗。
这些特征可以像提取边缘,或提取猫的胡须等。卷积层将提取这些特征。让我们来看看数据集。
这些是数据集中某些图像的示例。




我们首先需要调整这些图像的大小,使它们全部处于相同的形状。这是我们在处理图像时通常需要做的事情,因为在捕获图像时,不可能捕获相同大小的所有图像。
为了简化您的理解,我刚刚使用了单个卷积层和单个池化层,这通常在我们尝试进行预测时不会发生。使用的数据集可以从这里下载。
#import各种包
import osimport numpy as npimport pandas as pdimport scipyimport sklearnimport kerasfrom keras.models import Sequentialimport cv2from skimage import io%matplotlib inline
#Defining文件路径
cat=os.listdir("/mnt/hdd/datasets/dogs_cats/train/cat")dog=os.listdir("/mnt/hdd/datasets/dogs_cats/train/dog")filepath="/mnt/hdd/datasets/dogs_cats/train/cat/"filepath2="/mnt/hdd/datasets/dogs_cats/train/dog/"
#Loading the Images
images=[]label = []for i in cat: image = scipy.misc.imread(filepath+i) images.append(image) label.append(0) #for cat images
for i in dog: image = scipy.misc.imread(filepath2+i) images.append(image) label.append(1) #for dog images
#resizing所有图像
for i in range(0,23000): images[i]=cv2.resize(images[i],(300,300))
#将图像转换为数组
images=np.array(images)label=np.array(label)
#定义超参数
filters=10filtersize=(5,5)
epochs =5batchsize=128
input_shape=(300,300,3)
#将目标变量转换为所需的大小
from keras.utils.np_utils import to_categoricallabel = to_categorical(label)
#Defining模型
model = Sequential()
model.add(keras.layers.InputLayer(input_shape=input_shape))
model.add(keras.layers.convolutional.Conv2D(filters, filtersize, strides=(1, 1), padding='valid', data_format="channels_last", activation='relu'))model.add(keras.layers.MaxPooling2D(pool_size=(2, 2)))model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(units=2, input_dim=50,activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])model.fit(images, label, epochs=epochs, batch_size=batchsize,validation_split=0.3)
model.summary()

在这个模型中,我只使用了一个卷积和Pooling层,可训练的参数是219,801。想知道如果我在这种情况下使用了MLP,我会有多少人拥有。您可以通过添加更多卷积和池化层来进一步减少参数数量。我们添加的卷积层越多,提取的特征就越具体和复杂。