深度学习: GoogleNet 网络
Introduce
提出了 Inception_v1,开启了伟大的Inception系列,并刷新了网络的深度新记录。
这是一种 类似于 网中网(Network In Network)的结构,即原来的结点也是一个网络。
Paper:Going Deeper with Convolutions
Structure


伟大的Inception系列从那之后一直在不断发展,目前已经V2、V3、V4了。现今浪潮之巅的ResNeXt便是集ResNet与Inception大成者。
Inception的结构如下图所示:
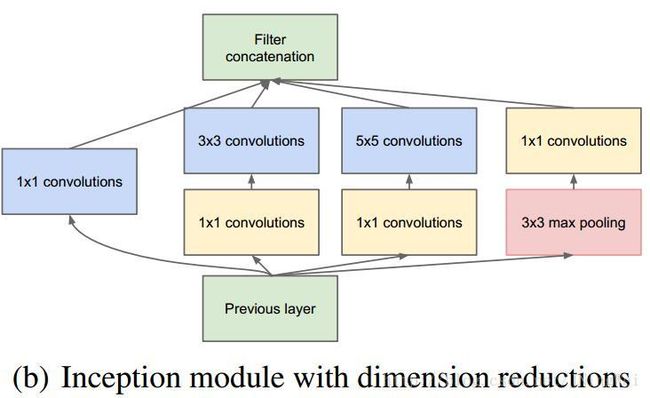
其中1*1卷积主要用来降维,用了Inception之后整个网络结构的宽度和深度都可扩大,能够带来2-3倍的性能提升。
Code
BVLC/caffe/models/bvlc_googlenet/deploy.prototxt:
name: "GoogleNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 224 dim: 224 } }
}
layer {
name: "conv1/7x7_s2"
type: "Convolution"
bottom: "data"
top: "conv1/7x7_s2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 3
kernel_size: 7
stride: 2
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "conv1/relu_7x7"
type: "ReLU"
bottom: "conv1/7x7_s2"
top: "conv1/7x7_s2"
}
layer {
name: "pool1/3x3_s2"
type: "Pooling"
bottom: "conv1/7x7_s2"
top: "pool1/3x3_s2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "pool1/norm1"
type: "LRN"
bottom: "pool1/3x3_s2"
top: "pool1/norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2/3x3_reduce"
type: "Convolution"
bottom: "pool1/norm1"
top: "conv2/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "conv2/relu_3x3_reduce"
type: "ReLU"
bottom: "conv2/3x3_reduce"
top: "conv2/3x3_reduce"
}
layer {
name: "conv2/3x3"
type: "Convolution"
bottom: "conv2/3x3_reduce"
top: "conv2/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 192
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "conv2/relu_3x3"
type: "ReLU"
bottom: "conv2/3x3"
top: "conv2/3x3"
}
layer {
name: "conv2/norm2"
type: "LRN"
bottom: "conv2/3x3"
top: "conv2/norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool2/3x3_s2"
type: "Pooling"
bottom: "conv2/norm2"
top: "pool2/3x3_s2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "inception_3a/1x1"
type: "Convolution"
bottom: "pool2/3x3_s2"
top: "inception_3a/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_1x1"
type: "ReLU"
bottom: "inception_3a/1x1"
top: "inception_3a/1x1"
}
layer {
name: "inception_3a/3x3_reduce"
type: "Convolution"
bottom: "pool2/3x3_s2"
top: "inception_3a/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_3a/3x3_reduce"
top: "inception_3a/3x3_reduce"
}
layer {
name: "inception_3a/3x3"
type: "Convolution"
bottom: "inception_3a/3x3_reduce"
top: "inception_3a/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_3x3"
type: "ReLU"
bottom: "inception_3a/3x3"
top: "inception_3a/3x3"
}
layer {
name: "inception_3a/5x5_reduce"
type: "Convolution"
bottom: "pool2/3x3_s2"
top: "inception_3a/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_3a/5x5_reduce"
top: "inception_3a/5x5_reduce"
}
layer {
name: "inception_3a/5x5"
type: "Convolution"
bottom: "inception_3a/5x5_reduce"
top: "inception_3a/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_5x5"
type: "ReLU"
bottom: "inception_3a/5x5"
top: "inception_3a/5x5"
}
layer {
name: "inception_3a/pool"
type: "Pooling"
bottom: "pool2/3x3_s2"
top: "inception_3a/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_3a/pool_proj"
type: "Convolution"
bottom: "inception_3a/pool"
top: "inception_3a/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_pool_proj"
type: "ReLU"
bottom: "inception_3a/pool_proj"
top: "inception_3a/pool_proj"
}
layer {
name: "inception_3a/output"
type: "Concat"
bottom: "inception_3a/1x1"
bottom: "inception_3a/3x3"
bottom: "inception_3a/5x5"
bottom: "inception_3a/pool_proj"
top: "inception_3a/output"
}
layer {
name: "inception_3b/1x1"
type: "Convolution"
bottom: "inception_3a/output"
top: "inception_3b/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3b/relu_1x1"
type: "ReLU"
bottom: "inception_3b/1x1"
top: "inception_3b/1x1"
}
layer {
name: "inception_3b/3x3_reduce"
type: "Convolution"
bottom: "inception_3a/output"
top: "inception_3b/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3b/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_3b/3x3_reduce"
top: "inception_3b/3x3_reduce"
}
layer {
name: "inception_3b/3x3"
type: "Convolution"
bottom: "inception_3b/3x3_reduce"
top: "inception_3b/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 192
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3b/relu_3x3"
type: "ReLU"
bottom: "inception_3b/3x3"
top: "inception_3b/3x3"
}
layer {
name: "inception_3b/5x5_reduce"
type: "Convolution"
bottom: "inception_3a/output"
top: "inception_3b/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3b/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_3b/5x5_reduce"
top: "inception_3b/5x5_reduce"
}
layer {
name: "inception_3b/5x5"
type: "Convolution"
bottom: "inception_3b/5x5_reduce"
top: "inception_3b/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3b/relu_5x5"
type: "ReLU"
bottom: "inception_3b/5x5"
top: "inception_3b/5x5"
}
layer {
name: "inception_3b/pool"
type: "Pooling"
bottom: "inception_3a/output"
top: "inception_3b/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_3b/pool_proj"
type: "Convolution"
bottom: "inception_3b/pool"
top: "inception_3b/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3b/relu_pool_proj"
type: "ReLU"
bottom: "inception_3b/pool_proj"
top: "inception_3b/pool_proj"
}
layer {
name: "inception_3b/output"
type: "Concat"
bottom: "inception_3b/1x1"
bottom: "inception_3b/3x3"
bottom: "inception_3b/5x5"
bottom: "inception_3b/pool_proj"
top: "inception_3b/output"
}
layer {
name: "pool3/3x3_s2"
type: "Pooling"
bottom: "inception_3b/output"
top: "pool3/3x3_s2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "inception_4a/1x1"
type: "Convolution"
bottom: "pool3/3x3_s2"
top: "inception_4a/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 192
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_1x1"
type: "ReLU"
bottom: "inception_4a/1x1"
top: "inception_4a/1x1"
}
layer {
name: "inception_4a/3x3_reduce"
type: "Convolution"
bottom: "pool3/3x3_s2"
top: "inception_4a/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_4a/3x3_reduce"
top: "inception_4a/3x3_reduce"
}
layer {
name: "inception_4a/3x3"
type: "Convolution"
bottom: "inception_4a/3x3_reduce"
top: "inception_4a/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 208
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_3x3"
type: "ReLU"
bottom: "inception_4a/3x3"
top: "inception_4a/3x3"
}
layer {
name: "inception_4a/5x5_reduce"
type: "Convolution"
bottom: "pool3/3x3_s2"
top: "inception_4a/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_4a/5x5_reduce"
top: "inception_4a/5x5_reduce"
}
layer {
name: "inception_4a/5x5"
type: "Convolution"
bottom: "inception_4a/5x5_reduce"
top: "inception_4a/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 48
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_5x5"
type: "ReLU"
bottom: "inception_4a/5x5"
top: "inception_4a/5x5"
}
layer {
name: "inception_4a/pool"
type: "Pooling"
bottom: "pool3/3x3_s2"
top: "inception_4a/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_4a/pool_proj"
type: "Convolution"
bottom: "inception_4a/pool"
top: "inception_4a/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_pool_proj"
type: "ReLU"
bottom: "inception_4a/pool_proj"
top: "inception_4a/pool_proj"
}
layer {
name: "inception_4a/output"
type: "Concat"
bottom: "inception_4a/1x1"
bottom: "inception_4a/3x3"
bottom: "inception_4a/5x5"
bottom: "inception_4a/pool_proj"
top: "inception_4a/output"
}
layer {
name: "inception_4b/1x1"
type: "Convolution"
bottom: "inception_4a/output"
top: "inception_4b/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 160
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4b/relu_1x1"
type: "ReLU"
bottom: "inception_4b/1x1"
top: "inception_4b/1x1"
}
layer {
name: "inception_4b/3x3_reduce"
type: "Convolution"
bottom: "inception_4a/output"
top: "inception_4b/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 112
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4b/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_4b/3x3_reduce"
top: "inception_4b/3x3_reduce"
}
layer {
name: "inception_4b/3x3"
type: "Convolution"
bottom: "inception_4b/3x3_reduce"
top: "inception_4b/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 224
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4b/relu_3x3"
type: "ReLU"
bottom: "inception_4b/3x3"
top: "inception_4b/3x3"
}
layer {
name: "inception_4b/5x5_reduce"
type: "Convolution"
bottom: "inception_4a/output"
top: "inception_4b/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4b/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_4b/5x5_reduce"
top: "inception_4b/5x5_reduce"
}
layer {
name: "inception_4b/5x5"
type: "Convolution"
bottom: "inception_4b/5x5_reduce"
top: "inception_4b/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4b/relu_5x5"
type: "ReLU"
bottom: "inception_4b/5x5"
top: "inception_4b/5x5"
}
layer {
name: "inception_4b/pool"
type: "Pooling"
bottom: "inception_4a/output"
top: "inception_4b/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_4b/pool_proj"
type: "Convolution"
bottom: "inception_4b/pool"
top: "inception_4b/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4b/relu_pool_proj"
type: "ReLU"
bottom: "inception_4b/pool_proj"
top: "inception_4b/pool_proj"
}
layer {
name: "inception_4b/output"
type: "Concat"
bottom: "inception_4b/1x1"
bottom: "inception_4b/3x3"
bottom: "inception_4b/5x5"
bottom: "inception_4b/pool_proj"
top: "inception_4b/output"
}
layer {
name: "inception_4c/1x1"
type: "Convolution"
bottom: "inception_4b/output"
top: "inception_4c/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4c/relu_1x1"
type: "ReLU"
bottom: "inception_4c/1x1"
top: "inception_4c/1x1"
}
layer {
name: "inception_4c/3x3_reduce"
type: "Convolution"
bottom: "inception_4b/output"
top: "inception_4c/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4c/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_4c/3x3_reduce"
top: "inception_4c/3x3_reduce"
}
layer {
name: "inception_4c/3x3"
type: "Convolution"
bottom: "inception_4c/3x3_reduce"
top: "inception_4c/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4c/relu_3x3"
type: "ReLU"
bottom: "inception_4c/3x3"
top: "inception_4c/3x3"
}
layer {
name: "inception_4c/5x5_reduce"
type: "Convolution"
bottom: "inception_4b/output"
top: "inception_4c/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4c/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_4c/5x5_reduce"
top: "inception_4c/5x5_reduce"
}
layer {
name: "inception_4c/5x5"
type: "Convolution"
bottom: "inception_4c/5x5_reduce"
top: "inception_4c/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4c/relu_5x5"
type: "ReLU"
bottom: "inception_4c/5x5"
top: "inception_4c/5x5"
}
layer {
name: "inception_4c/pool"
type: "Pooling"
bottom: "inception_4b/output"
top: "inception_4c/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_4c/pool_proj"
type: "Convolution"
bottom: "inception_4c/pool"
top: "inception_4c/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4c/relu_pool_proj"
type: "ReLU"
bottom: "inception_4c/pool_proj"
top: "inception_4c/pool_proj"
}
layer {
name: "inception_4c/output"
type: "Concat"
bottom: "inception_4c/1x1"
bottom: "inception_4c/3x3"
bottom: "inception_4c/5x5"
bottom: "inception_4c/pool_proj"
top: "inception_4c/output"
}
layer {
name: "inception_4d/1x1"
type: "Convolution"
bottom: "inception_4c/output"
top: "inception_4d/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 112
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4d/relu_1x1"
type: "ReLU"
bottom: "inception_4d/1x1"
top: "inception_4d/1x1"
}
layer {
name: "inception_4d/3x3_reduce"
type: "Convolution"
bottom: "inception_4c/output"
top: "inception_4d/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 144
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4d/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_4d/3x3_reduce"
top: "inception_4d/3x3_reduce"
}
layer {
name: "inception_4d/3x3"
type: "Convolution"
bottom: "inception_4d/3x3_reduce"
top: "inception_4d/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 288
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4d/relu_3x3"
type: "ReLU"
bottom: "inception_4d/3x3"
top: "inception_4d/3x3"
}
layer {
name: "inception_4d/5x5_reduce"
type: "Convolution"
bottom: "inception_4c/output"
top: "inception_4d/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4d/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_4d/5x5_reduce"
top: "inception_4d/5x5_reduce"
}
layer {
name: "inception_4d/5x5"
type: "Convolution"
bottom: "inception_4d/5x5_reduce"
top: "inception_4d/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4d/relu_5x5"
type: "ReLU"
bottom: "inception_4d/5x5"
top: "inception_4d/5x5"
}
layer {
name: "inception_4d/pool"
type: "Pooling"
bottom: "inception_4c/output"
top: "inception_4d/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_4d/pool_proj"
type: "Convolution"
bottom: "inception_4d/pool"
top: "inception_4d/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4d/relu_pool_proj"
type: "ReLU"
bottom: "inception_4d/pool_proj"
top: "inception_4d/pool_proj"
}
layer {
name: "inception_4d/output"
type: "Concat"
bottom: "inception_4d/1x1"
bottom: "inception_4d/3x3"
bottom: "inception_4d/5x5"
bottom: "inception_4d/pool_proj"
top: "inception_4d/output"
}
layer {
name: "inception_4e/1x1"
type: "Convolution"
bottom: "inception_4d/output"
top: "inception_4e/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4e/relu_1x1"
type: "ReLU"
bottom: "inception_4e/1x1"
top: "inception_4e/1x1"
}
layer {
name: "inception_4e/3x3_reduce"
type: "Convolution"
bottom: "inception_4d/output"
top: "inception_4e/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 160
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4e/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_4e/3x3_reduce"
top: "inception_4e/3x3_reduce"
}
layer {
name: "inception_4e/3x3"
type: "Convolution"
bottom: "inception_4e/3x3_reduce"
top: "inception_4e/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 320
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4e/relu_3x3"
type: "ReLU"
bottom: "inception_4e/3x3"
top: "inception_4e/3x3"
}
layer {
name: "inception_4e/5x5_reduce"
type: "Convolution"
bottom: "inception_4d/output"
top: "inception_4e/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4e/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_4e/5x5_reduce"
top: "inception_4e/5x5_reduce"
}
layer {
name: "inception_4e/5x5"
type: "Convolution"
bottom: "inception_4e/5x5_reduce"
top: "inception_4e/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4e/relu_5x5"
type: "ReLU"
bottom: "inception_4e/5x5"
top: "inception_4e/5x5"
}
layer {
name: "inception_4e/pool"
type: "Pooling"
bottom: "inception_4d/output"
top: "inception_4e/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_4e/pool_proj"
type: "Convolution"
bottom: "inception_4e/pool"
top: "inception_4e/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4e/relu_pool_proj"
type: "ReLU"
bottom: "inception_4e/pool_proj"
top: "inception_4e/pool_proj"
}
layer {
name: "inception_4e/output"
type: "Concat"
bottom: "inception_4e/1x1"
bottom: "inception_4e/3x3"
bottom: "inception_4e/5x5"
bottom: "inception_4e/pool_proj"
top: "inception_4e/output"
}
layer {
name: "pool4/3x3_s2"
type: "Pooling"
bottom: "inception_4e/output"
top: "pool4/3x3_s2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "inception_5a/1x1"
type: "Convolution"
bottom: "pool4/3x3_s2"
top: "inception_5a/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_1x1"
type: "ReLU"
bottom: "inception_5a/1x1"
top: "inception_5a/1x1"
}
layer {
name: "inception_5a/3x3_reduce"
type: "Convolution"
bottom: "pool4/3x3_s2"
top: "inception_5a/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 160
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_5a/3x3_reduce"
top: "inception_5a/3x3_reduce"
}
layer {
name: "inception_5a/3x3"
type: "Convolution"
bottom: "inception_5a/3x3_reduce"
top: "inception_5a/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 320
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_3x3"
type: "ReLU"
bottom: "inception_5a/3x3"
top: "inception_5a/3x3"
}
layer {
name: "inception_5a/5x5_reduce"
type: "Convolution"
bottom: "pool4/3x3_s2"
top: "inception_5a/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_5a/5x5_reduce"
top: "inception_5a/5x5_reduce"
}
layer {
name: "inception_5a/5x5"
type: "Convolution"
bottom: "inception_5a/5x5_reduce"
top: "inception_5a/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_5x5"
type: "ReLU"
bottom: "inception_5a/5x5"
top: "inception_5a/5x5"
}
layer {
name: "inception_5a/pool"
type: "Pooling"
bottom: "pool4/3x3_s2"
top: "inception_5a/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_5a/pool_proj"
type: "Convolution"
bottom: "inception_5a/pool"
top: "inception_5a/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_pool_proj"
type: "ReLU"
bottom: "inception_5a/pool_proj"
top: "inception_5a/pool_proj"
}
layer {
name: "inception_5a/output"
type: "Concat"
bottom: "inception_5a/1x1"
bottom: "inception_5a/3x3"
bottom: "inception_5a/5x5"
bottom: "inception_5a/pool_proj"
top: "inception_5a/output"
}
layer {
name: "inception_5b/1x1"
type: "Convolution"
bottom: "inception_5a/output"
top: "inception_5b/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5b/relu_1x1"
type: "ReLU"
bottom: "inception_5b/1x1"
top: "inception_5b/1x1"
}
layer {
name: "inception_5b/3x3_reduce"
type: "Convolution"
bottom: "inception_5a/output"
top: "inception_5b/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 192
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5b/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_5b/3x3_reduce"
top: "inception_5b/3x3_reduce"
}
layer {
name: "inception_5b/3x3"
type: "Convolution"
bottom: "inception_5b/3x3_reduce"
top: "inception_5b/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5b/relu_3x3"
type: "ReLU"
bottom: "inception_5b/3x3"
top: "inception_5b/3x3"
}
layer {
name: "inception_5b/5x5_reduce"
type: "Convolution"
bottom: "inception_5a/output"
top: "inception_5b/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 48
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5b/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_5b/5x5_reduce"
top: "inception_5b/5x5_reduce"
}
layer {
name: "inception_5b/5x5"
type: "Convolution"
bottom: "inception_5b/5x5_reduce"
top: "inception_5b/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5b/relu_5x5"
type: "ReLU"
bottom: "inception_5b/5x5"
top: "inception_5b/5x5"
}
layer {
name: "inception_5b/pool"
type: "Pooling"
bottom: "inception_5a/output"
top: "inception_5b/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_5b/pool_proj"
type: "Convolution"
bottom: "inception_5b/pool"
top: "inception_5b/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5b/relu_pool_proj"
type: "ReLU"
bottom: "inception_5b/pool_proj"
top: "inception_5b/pool_proj"
}
layer {
name: "inception_5b/output"
type: "Concat"
bottom: "inception_5b/1x1"
bottom: "inception_5b/3x3"
bottom: "inception_5b/5x5"
bottom: "inception_5b/pool_proj"
top: "inception_5b/output"
}
layer {
name: "pool5/7x7_s1"
type: "Pooling"
bottom: "inception_5b/output"
top: "pool5/7x7_s1"
pooling_param {
pool: AVE
kernel_size: 7
stride: 1
}
}
layer {
name: "pool5/drop_7x7_s1"
type: "Dropout"
bottom: "pool5/7x7_s1"
top: "pool5/7x7_s1"
dropout_param {
dropout_ratio: 0.4
}
}
layer {
name: "loss3/classifier"
type: "InnerProduct"
bottom: "pool5/7x7_s1"
top: "loss3/classifier"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 1000
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "loss3/classifier"
top: "prob"
}
[1] GoogLeNet系列解读
[2] Deep Learning回顾 之LeNet、AlexNet、GoogLeNet、VGG、ResNet