正则表达式使用总结
正则表达式使用总结
正则表达式是什么
- 正则表达式是用来简洁表达一组字符串的表达式。
- 正则表达式是通用的字符串表达框架。
- 正则表达式是简洁表达一组字符串的表达式。
- 正则表达式是针对字符串表达“简洁”和“特征”思想的工具。
- 正则表达式可以用来判断某字符串的特征归属。
另外正则表达式在文本处理中十分常用:
- 正则表达式用来表达文本类型的特征如,病毒、入侵等。
- 正则表达式可以表达一组字符串,用于查找替换。
- 正则表达式可以匹配字符串的全部或一部分。
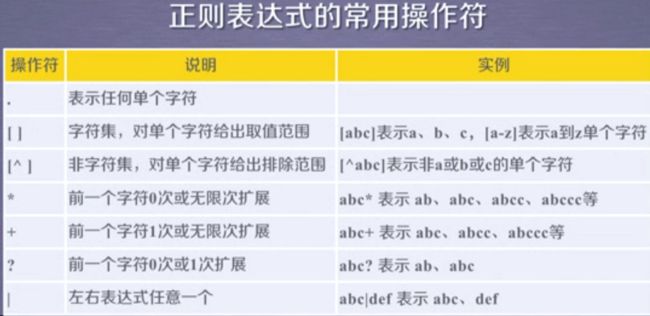
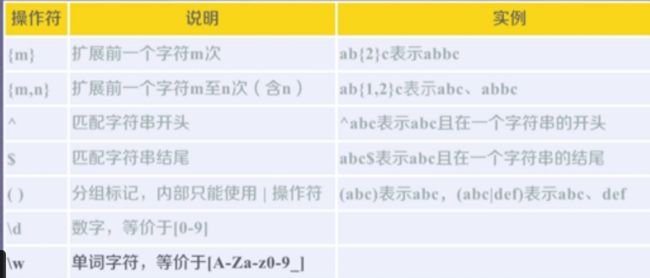
正则表达式的语法
正则表达式是由字符和操作符构成的。
正则表达式的常用操作符
常规例子:
P(Y|YT|YTH|YTHO)?N "PN","PYN","PYTN","PYTHN","PYTHON"
PYTHON+ "PYTHON","PYTHONN","PYTHONNN..."
PY[TH]ON "PYTON","PYHON"
PY[^TH]?ON "PYON","PYAON","PYXON"
PY{:3}N "PN","PYN","PYYN","PYYYN"^[A-Za-z]+$ 由26个字母组成的字符串
^[A-Za-z0-9]+$ 由26个字母和数字组成的字符串
^-?\d+$ 整数形式的字符串
^[0-9]*[1-9][0-9]*$ 正整数形式的字符串
[1-9]\d{5} 中国境内邮政编码,6位
[\u4e00-\u9fa5] 匹配中文字符 #采用utf8编码约定中文字符取值范围
\d{3}-\d{8}|\d{4}-\d{7} 国内电话号码,010-68913536 11位啊匹配IP地址的正则表达式,(IP地址分4段,每段是0-255)
精确的写法:
0-99: [1-9]?\d
100-199:1\d{2}
200-249:2[0-4]\d
250-255:25[0-5]
ip地址:
(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5])
Re库的基本使用
re库是Python的的标准库,主要用于字符串匹配。
调用方式:
import re
正则表达式的表示类型
re库采用raw string类型,也就是原生字符串类型。
原生字符串类型是指:斜杠\ 不会转意。因为正则表达式中操作符有些是和斜杠一起构成的,使用原生字符串就可以防止转意了。
在字符串前加一个小写字母r就可以了。
如:
r"[1-9]?\d"
所以:
当正则表达式中包含转意符号时,使用原生字符串。
re库的功能函数

函数的具体说明:
re.search(pattern,string,flags=0)
作用:
在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象。
参数说明:
- pattern:正则表达式的字符串或原生字符串
- string:需要和这个正则表达式匹配的字符串
- flags:正则表达式使用时的控制标记
flags:正则表达式使用时的控制标记
- re.I 忽略正则表示是的大小写,[a-z]可以匹配大写
- re.M 正则表达式中的^操作符能够将给定的字符串的每行当做匹配的开始
- re.S 正则表达式中的.点操作符能够匹配所有的字符,默认匹配除换行符外的所有字符
例子:
>>> import re #导入re库
>>> match = re.search(r'[1-9]\d{5}','GHF345326 GHF525300') #匹配邮政编码,返回的是一个match对象
>>> if match:
print(match.group(0))
345326作用:
从一个字符串的开始位置起匹配正则表达式,返回match对象。
参数:
同search
例子:
>>> import re
>>> match1 = re.match(r'[1-9]\d{5}','GHF535343')
>>> if match1:
print(match1.group(0))
#match()方法是从字符串的起始位置开始匹配,开始字符串不是,所有match对象为空。
>>> match1.group(0) #要对返回的match对象进行打印时,需要判断match对象是否为空,不为空才能调用group(0)方法。
Traceback (most recent call last):
File "", line 1, in
match1.group(0)
AttributeError: 'NoneType' object has no attribute 'group'
>>> match2 = re.match(r'[1-9]\d{5}','525300 GHT')
>>> if match2:
match2.group(0)
'525300' 作用:
搜索字符串,以列表的形式返回所有能够匹配的子串。
参数同search
例子:
>>> import re
>>> ls =re.findall(r'[1-9]\d{5}','234323gg GHT838476ff535243')
>>> ls
['234323', '838476', '535243']作用:
将一个字符串按照正则表达式匹配的结果进行分割,返回列表类型。
pattren\string\flags和search、match、findall方法一样,
maxsplit:最大分割数,剩余部分作为最后一个元素输出
例子:
>>> import re
>>> ls = re.split(r'[1-9]\d{5}','FG123456JJJ213456 234567SDF')
>>> ls
['FG', 'JJJ', ' ', 'SDF'] #返回一个列表
>>> ls1 = re.split(r'[1-9]\d{5}','FJD324538HJH879045',maxsplit=1) #最大分割是1,所有只分割1个,剩下的原路返回
>>> ls1
['FJD', 'HJH879045']
>>> 作用:
搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素都是match对象。
参数和search、match、findall方法一样
例子:
>>> import re
>>> srting = 'ere123456kij234567pl345435'
>>> ls = re.finditer(r'[1-9]\d{5}',srting)
>>> type(ls)
>>> for i in ls:
if i :
print(i.group(0))
123456
234567
345435 作用:
在一个字符串中替换所有匹配正则表达式的子串,返回被替换后的字符串。
参数pattern、string、flags和search、match、findall的参数一样。
repl:替换匹配字符串的字符串
count:匹配的最大替换次数
例子:
>>> import re
>>> re.sub(r'[1-9]\d{5}','repl111','GHT212123GTY345673',count=2)
'GHTrepl111GTYrepl111'
>>> re.sub(r'[1-9]\d{5}','+test+','GTH787878GHU898789')
'GTH+test+GHU+test+'
>>> re.sub(r'[1-9]\d{5}','+test+','GTH787878GHU898789',count=1)
'GTH+test+GHU898789'
>>> 
以上通过.调用的方法使用re的方法是函数式用法:一次性操作
正则表达式还有另外一种方法:
面向对象用法:编译后多次操作
>>> import re
>>> pat = re.compile(r'[1-9]\d{5}')
>>> rst = pat.search('GHT 525343')
>>> rst
<_sre.SRE_Match object; span=(4, 10), match='525343'>
>>> if rst:
print(rst.group(0))
525343没经过compile的字符串只是正则表达式的一种表现形式,经过compile后的才是正则表达式。
优点:一次编译可以多次使用该正则表达式进行匹配。
pat = compile(pattern,flags=0)
作用:
将一个正则表达式编译成一个正则表达式对象。
参数说明:
pattern:正则表达式字符串或原生字符串;
flags:正则表达式使用时的控制标记;
re库的match对象
re的search()、match()、finditer()返回的是一个match对象,search、match只返回匹配到的第一个字符串,需要返回全部匹配的字符串使用finditer,for循环全部打印出来。
match对象是:一次匹配的结果,它包含了很多匹配的相关信息。
match对象的属性
- .string 待匹配的的文本
- .re 匹配时使用的pattern对象(正则表达式)
- .pos 正则表达是搜索文本的开始位置
- .endpos 正则表达式搜索文本的结束位置
>>> import re
>>> i = re.search(r'[1-9]\d{5}','GTR343435')
>>> if i :
print(i.group(0))
343435
>>> i.string #待匹配的文本
'GTR343435'
>>> i.re #正则表达式
re.compile('[1-9]\\d{5}')
>>> i.pos #搜索文本的开始位置
0
>>> i.endpos #搜索文本的结束位置
9- .group(0) 获得匹配后的字符串
- .start() 匹配字符串在原字符串的开始位置
- .end() 匹配字符串在原字符串的结束位置
- .span() 返回(.start(),.end())元组结构
>>> i.start() #匹配字符串在原字符串的开始位置
3
>>> i.end() #匹配字符串在原字符串的结束位置
9
>>> i.span() #返回一个元组,包括匹配字符串在原字符串的开始位置和结束位置
(3, 9)
>>> i.group(0) #返回匹配后的字符串
'343435'正则表达式的贪婪匹配和最小匹配
re库默认采用贪婪匹配的方式,也就是返回匹配的最长项,如:
>>> import re
>>> i = re.search(r'py.*n','pyanbncndnfngn')
>>> if i:
i.group(0)
'pyanbncndnfngn' #默认采用贪婪匹配,返回最长的只要在*的后面增加一个?问号:
>>> ii = re.match(r'py.*?n','pyanbncndnfngn')
>>> if ii :
ii.group(0)
'pyan'
当有操作符可以匹配不同长度时,我们都可以在操作符后面增加一个问号?来获取最小匹配。
什么时候采用BeautifulSoup库?
什么时候采用re库?
什么样的网站适合定向爬虫实现爬取?数据写在html页面中,可以通过定位到元素,一般的静态页面,但那种有js生成的页面,源代码没有显示页面,不适合定向爬虫。
淘宝定向爬虫实例
从众多的文本信息中提取我们需要的信息,使用正则表达式是最好的。
当不使用BeautifulSoup库进行信息提取,通过搜索的方式提取信息,使用re库是最合适的。
新知识点:
- 使用r.encoding = "utf-8" 比使用r.encoding = r.apparent_encoding节约时间
- 字符串中引入双引号,需要在前面加反斜杠,r'\"view_price\"\:\"[\d\.]*\"'
- eval()函数能够将字符串最外层双引号或单引号去掉
- for 循环遍历range()是从0开始的,for i in plt:也可以的,但是下面也要再次遍历tlt、重复了。使用range(len(list)),获得列表的每个元素的序号,再通过下标可以得到列表元素了。
- continue语句只是结束本次循环,而不会终止循环的执行。break语句则是终止整个循环过程。
- {}定义槽函数,{:4}第一个位置长度为4,中间8,最后是16。参考代码。
- 字符串的.format()函数使用