chapter-1:课程介绍
什么是计算机视觉
当今世界,随着智能手机及各类计算机硬件的发展,视觉传感器已经广泛地遍布于我们的世界。我们如何能利用这些传感器来获得有价值的信息呢?为了解决这一问题,计算机视觉学应运而生。
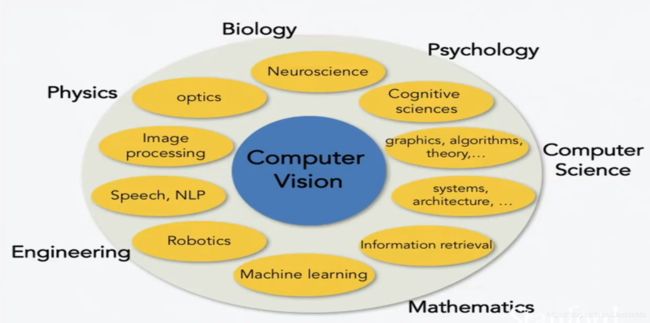
计算机视觉并不是独属于计算机学的学科,而是计算机学与生物学、物理学、工程学、数学、甚至心理学的交叉学科,如下图所示:
计算机视觉的历史
计算机视觉可能是地球上最为源远流长的学科,因为它试图模仿及超越的视觉能力,来源于5亿4千万年前。
在那个时候,生物发生了生物学家们至今仍在争议其起因的爆发式进化。目前最具有说服力的一个说法是,在那个时刻,生物突然进化出了视觉。是视觉让生物获得了远胜以往的捕食能力,为了对抗捕食者,被捕食者也被迫发生各种进化。于是,物种大爆发发生了。
从那时开始到现在,视觉已经成为了智慧生命最重要的感知方式。我们人类大脑皮层内部约一半的神经元与视觉有关。
以上是生物视觉的历史,那么让机器获得视觉的历史呢?
人类开始试图用机器模仿生物视觉的历史,始于照相机的发明。17世纪,第一台照相机被发明了。它和动物早期的视觉原理很相似:有一个能透光的小孔,以及小孔后的平板收集信息并成像。
之后生物学家们也开始研究视觉的机理。最有名的是hubel和wiesel的研究。他们把一根电极插入猫的初级视觉皮层,并给猫看各种各样的图片,观察电信号的变化。有趣的是,他们发现,猫的视觉皮层在看到不同的图片时并不会产生很大的变化,然而在他们切换图片时产生了变化。经过一番研究,他们得出了影响后世很久的结论:生物在处理图像信息时,优先处理图像的边缘。
1966年,MIT组建了一个暑假项目,它计划用一个暑假的时间,试图有效地利用暑假的时间,来研究清楚视觉的原理,以及解决大部分视觉问题。但显然研究人员们并没能够有效地利用ta们的暑假时间,以至于ta们试图在那个暑假解决的问题至今仍悬而未决,且一路发展,成为了人工智能领域增长最快的方向。
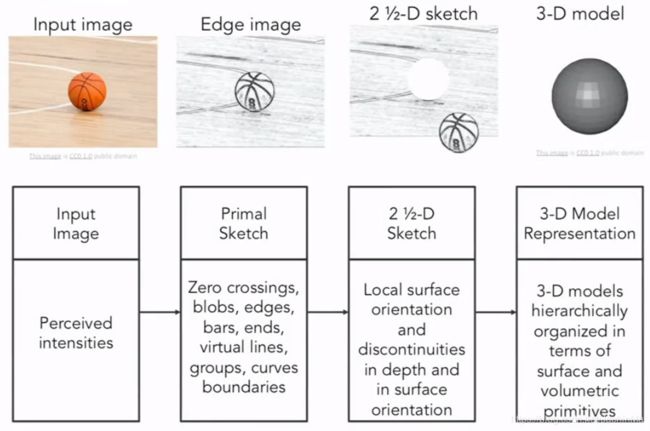
70年代后期,David Marr写了一本书。他在书中写道,为了得到图像中的物体的3D模型,必须经历以下几个过程:首先是原始草图,即我们的原始图像;其次从原始草图中得到边缘、端点和虚拟线条,并用其它元素替代。然后将表面、和深度的不连续信息拼凑在一起,形成一个2.5D的图像;最后利用表面和体积信息分等级地组合起来,形成一个3D模型(其实没听懂…)。过程如下图所示:
在之后,也有不少目标识别的方法被提出,但均未能取得理想的效果。直到后来有一个新的思想诞生了:既然目标识别这个问题太难了,那我们不妨先解决它简单一些的前置问题:图像分割。这个任务是将一张图片中的像素点归类到有意义的区域内:
与此同时,Paul Viola利用AdaBoost算法,成功实现了实时的人脸检测。考虑到他们使用的是奔腾Ⅱ芯片,这确实是一件非常难得的工作。
关于如何得到更好的目标识别的问题,在1990年到21世纪的前十年有一种很有影响力的思想:基于特征的目标识别。例如下面这幅图片:

虽然相机的角度、光线、颜色等信息都变化了,但有些可供判别的特征是具有不变性,通过这些特征就可以进行判别。
计算机视觉还有一个研究领域:识别整幅图的场景。以空间金字塔算法为例,其思想是,图片具有各种能够告诉我们其所处场景的特征,计算机从各个像素中抽取特征,并将其聚合,构成一个特征描述符,然后构建一个支持向量机并上进行识别。
虽然目标识别的方向早已被提出,但在21世纪早期标注数据集出现之前,人们都没有一个能够有效衡量标记效果的方法。其中最有影响力的数据集是叫PASCAL Visual Object Challenge。它共有20个类别,每个类别都包含成千上万幅图片,以供研究人员们测试自己算法的准确度。
与此同时,一个新的问题被提出:我们是否已经具备了识别真实世界中物体的能力?为了解决这个问题,以及解决目标识别中常遇到的问题:由于图片的维度过高,而训练数据量过少导致的过拟合现象较为严重,ImageNet诞生了。
它包含了几千万的图片,22k类别的物体或场景。利用人工对图片进行标注,一经推出就成为了当时最大的图片数据集。
为了有效利用它,ImageNet大规模目标识别竞赛诞生了。参赛者们使用自己的算法对ImageNet中的数据进行分类,并根据错误率进行评比。以下是各年比赛冠军的错误率:

可以看到,现在计算机的错误率已经低于人类了,这只用了短短几年的时间。图上另外值得注意的一点是,在2012年,识别的错误率有了一个非常明显的下降,远远超过其它年的变化。那一年的冠军所用的算法就是这门课所要研究的算法:卷积神经网络(conventional neural network,CNN)。
那些尚未解决的
目前在计算机视觉领域还有很多问题仍待解决:
语义分割或知觉分组:理解每个像素的意义而不是标记图片。
动作识别:有效识别视频中的动作。
图片理解:不仅是明白图片里有什么,而是理解图片中在发生什么。更进一步地,甚至编写一个关于图片的故事。
除此之外,在医学诊断、自动驾驶、机器人技术等方向,还有许多有趣的悬而未决的问题。
虽然计算机视觉已经经历了迅猛的发展,但距离它的终极目标——即使是当下的我们所能想象的终极目标,还有很长的一段距离。我们还需要付出很多努力,来推进它的进步,来对人类及人类社会的进步产生积极的影响。
PS.在写这篇文章的时候,我正好看到了一篇文章,讲目前已经有一种体型和人类差不多的应用计算机视觉技术和机器人技术设计的垃圾分拣机器人已经能够很好地商用了。一个这样的机器人可以代替48个人类,且能够以007的方式进行工作。
虽然这会让我们担心,也许这类机器人会使一些工人失业,但我想随着包含计算机视觉技术在内的AI技术继续进步下去,这类违反人性的工作迟早会有一天全部被人类创造的机器人消灭,而原来负责这些工作的人们,在那个能够靠机器人创造数倍于人类员工价值的社会,过着无所事事,随心所欲的生活。