【Learning Notes】生成式对抗网络(Generative Adversarial Networks,GAN)
在 学 习 V a r i a t i o n a l A u t o - E n c o d e r 时 , 同 时 注 意 到 了 G A N 研 究 的 火 热 。 但 当 时 觉 得 G A N 非 常 不 成 熟 ( 训 练 不 稳 定 , 依 赖 各 种 说 不 清 的 t r i c k s ; 没 有 有 效 的 监 控 指 标 , 需 要 大 量 的 人 工 判 断 , 因 此 难 以 扩 展 到 图 像 之 外 的 高 维 数 据 ) 。 在 读 了 G o o d f e l l o w 的 t u t o r i a l 后 [ 2 ] , 开 始 黑 转 路 人 , 觉 得 G A N 虽 然 缺 点 不 少 , 但 优 点 也 很 明 显 。 W G A N [ 5 , 6 ] 等 工 作 出 现 后 , 开 始 逐 渐 路 人 转 粉 , 对 G A N 产 生 了 兴 趣 。
这 里 , 我 们 仅 仅 从 直 观 上 讨 论 G A N 框 架 及 相 关 变 种 , 将 理 论 留 待 将 来 讨 论 。
1. Basic GAN
本 质 上 , G A N 是 一 种 训 练 模 式 , 而 非 一 种 待 定 的 网 络 结 构 [ 1 ] 。

图 1 . G A N 基 本 框 架 【 s r c 】
G A N 的 基 本 思 想 是 , 生 成 器 和 判 别 器 玩 一 场 “ 道 高 一 尺 , 魔 高 一 丈 ” 的 游 戏 : 判 别 器 要 练 就 “ 火 眼 金 睛 ” , 尽 量 区 分 出 真 实 的 样 本 ( 如 真 实 的 图 片 ) 和 由 生 成 器 生 成 的 假 样 本 ; 生 成 器 要 学 着 “ 以 假 乱 真 ” , 生 成 出 使 判 别 器 判 别 为 真 实 的 “ 假 样 本 ” 。
竞 争 的 理 想 怦 是 双 方 都 不 断 进 步 — — ( 理 想 情 况 下 ) 判 别 器 的 眼 睛 越 发 “ 雪 亮 ” , 生 成 器 的 欺 骗 能 力 也 不 断 提 高 。 对 抗 的 胜 负 无 关 紧 要 , 重 要 的 是 , 最 后 生 成 器 的 欺 骗 能 力 足 够 好 , 能 够 生 成 与 真 实 样 本 足 够 相 似 的 样 本 — — 直 观 而 言 , 生 成 的 样 本 看 起 来 像 是 训 练 集 ( 如 图 片 ) 的 样 本 ; 形 式 化 的 , 生 成 器 生 成 样 本 的 分 布 , 应 该 与 训 练 集 样 本 分 布 接 近 。
理 论 上 可 以 , 在 理 想 条 件 下 , 生 成 器 是 可 以 通 过 这 种 对 抗 得 到 目 标 分 布 的 ( 即 生 成 足 够 真 实 的 样 本 ) 。
假 设 要 训 练 数 据 为 灰 度 M N I S T ( 归 一 化 为 [ 0 , 1 ] 之 间 ) , 生 成 器 ( g e n e r a t o r ) 可 以 为 任 意 输 入 为 隐 变 量 维 度 , 输 出 为 1 x 2 8 x 2 8 的 模 型 。 一 个 示 例 模 型 定 义 如 下 :
def build_generator(latent_size):
model = Sequential()
model.add(Dense(1024, input_dim=latent_size, activation='relu'))
model.add(Dense(28 * 28, activation='tanh'))
model.add(Reshape((1, 28, 28)))
return model判 别 器 ( d i s c r i m i n a t o r ) 可 以 为 任 意 输 入 1 x 2 8 x 2 8 , 输 出 为 1 维 且 在 [ 0 , 1 ] 之 间 ( 经 过 s i g m o i d 激 活 ) 的 模 型 。 一 个 示 例 模 型 定 义 如 下 :
def build_discriminator():
model = Sequential()
model.add(Flatten(input_shape=(1, 28, 28)))
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(1), activation='sigmoid')
return model输 出 值 表 示 判 别 器 判 别 输 入 样 本 为 真 的 概 率 。 即 输 出 值 越 接 近 1 , 判 别 器 越 确 信 样 本 为 真 ; 输 出 值 越 接 近 0 , 判 别 器 越 确 信 样 本 为 假 。
判别器
判 别 器 的 训 练 的 目 标 为 : 对 于 真 实 样 本 , 输 出 尽 量 接 近 1 ; 对 于 生 成 器 生 成 的 假 样 本 , 输 出 尽 量 接 近 0 。
也 即 训 练 判 别 器 时 , 真 实 样 本 的 标 签 为 1 , 生 成 样 本 的 标 签 为 0 。
生成器
判 别 器 的 训 练 的 目 标 为 生 成 的 假 样 本 , 使 判 别 器 的 输 出 尽 量 接 近 1 , 即 尽 量 以 假 乱 真 。
为 了 解 决 训 练 过 程 中 , 梯 度 消 失 的 问 题 , 一 般 使 用 如 下 损 失 函 数 ( T r i c k 2 ) :
为 使 用 这 个 损 失 函 数 , 只 需 要 将 生 成 样 本 的 标 签 为 1 , 同 时 使 用 变 通 的 交 叉 熵 损 失 函 数 。
G A N 的 训 练 流 程 如 下 [ 1 ] :

G A N 足 够 简 单 , 也 有 理 论 上 的 保 证 。 但 在 实 践 中 , 需 要 许 多 技 巧 和 运 气 才 能 正 常 把 “ 游 戏 玩 下 去 ” 。 这 里 , 我 们 不 考 虑 理 论 , 而 是 关 注 不 要 G A N 变 种 在 损 失 函 数 设 计 的 差 异 。
2. Least Squares GAN
我 们 以 [ 4 ] 中 E q ( 9 ) 为 例 来 介 绍 L S G A N 。 其 中 判 别 器 的 定 义 如 下 :
def build_discriminator():
model = Sequential()
model.add(Flatten(input_shape=(1, 28, 28)))
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(1), activation='linear') ## change 1
return model与 b a s i c G A N 唯 一 不 同 在 判 别 器 的 最 后 输 出 不 使 用 s i g m o i d 激 活 , 而 是 使 用 了 线 性 函 数 ( 也 即 不 使 用 激 活 ) ( 第 6 行 c h a n g e 1 ) 。
有 了 生 成 器 和 判 别 器 的 定 义 , 我 们 来 实 际 构 造 两 者 以 用 于 训 练 :
# 构造判别器
disc = build_discriminator()
disc.compile(optimizer=Adam(lr=lr),loss='mse')
# 构建生成器
generator = build_generator(latent_size)
latent = Input(shape=(latent_size,))
# 生成假图片
fake = generator(latent)
# 我们要训练生成器,因此固定判别的权值不变
disc.trainable = False
fake = disc(fake)
combined = Model(input=latent, output=fake)
combined.compile(optimizer=Adam(lr=lr), loss='mse')不 同 于 b a s i c G A N , L S G A N 的 训 练 损 失 函 数 由 交 叉 熵 改 为 M S E ( M e a n S q u a r e d E r r o r ) 。
for epoch in range(nb_epochs):
for index in range(nb_batches):
## 1) 训练判别器
# 1.1采样隐变量并生成假样本
noise = np.random.uniform(-1, 1, (batch_size, latent_size))
generated_images = generator.predict(noise, verbose=0)
# 1.2 从训练中采样真实样本
image_batch = X_train[index * batch_size:(index + 1) * batch_size]
label_batch = y_train[index * batch_size:(index + 1) * batch_size]
# 利用真假数据进行训练
X = np.concatenate((image_batch, generated_images))
# 设定真假数据的损失,a == 0, b == 1
y = np.array([1] * len(image_batch) + [0] * batch_size)
disc.train_on_batch(X, y)
## 2)训练生成器
# 采样隐变量
noise = np.random.uniform(-1, 1, (batch_size, latent_size))
target = np.ones(batch_size) # 设定生成样本的损失 c == b == 1
combined.train_on_batch(noise, target)图 2 是 训 练 过 程 中 , 由 生 成 器 采 样 的 几 张 示 例 图 片 。 完 整 的 示 例 可 以 参 见 r e p o 。

图 2 . L S G A N 随 机 采 样 生 成 的 图 片 ( E p o c h : 4 4 3 )
由 于 仅 作 为 示 例 以 及 时 间 和 计 算 资 源 的 限 制 , 从 模 型 结 构 到 优 化 器 的 参 数 都 没 有 经 过 任 何 调 优 。 因 此 , 这 里 生 成 的 图 片 的 质 量 不 应 该 做 为 算 法 优 劣 的 依 据 ( 下 同 ) 。
3. Wasserstein GAN(WGAN)
W G A N 采 用 线 性 的 损 失 函 数 , 为 此 我 们 定 义 :
def dummy_loss(loss_to_backprop, y_pred):
return K.mean(loss_to_backprop * y_pred) # delta == loss_to_backprop
disc.compile(optimizer=Adam(lr=lr),loss=dummy_loss)
combined.compile(optimizer=Adam(lr=lr), loss=dummy_loss)为 应 用 这 个 损 失 函 数 , 代 码 更 改 如 下 ( 第 1 2 和 1 8 行 , c h a n g e 2 、 3 ) 。
for epoch in range(nb_epochs):
for index in range(nb_batches):
## 1) 训练判别器
# 1.1采样隐变量并生成假样本
noise = np.random.uniform(-1, 1, (batch_size, latent_size))
generated_images = generator.predict(noise, verbose=0)
# 1.2 从训练中采样真实样本
image_batch = X_train[index * batch_size:(index + 1) * batch_size]
label_batch = y_train[index * batch_size:(index + 1) * batch_size]
# 利用真假数据进行训练
X = np.concatenate((image_batch, generated_images))
y = np.array([-1] * len(image_batch) + [1] * batch_size) ## change 2
disc.train_on_batch(X, y)
## 2)训练生成器
# 采样隐变量
noise = np.random.uniform(-1, 1, (batch_size, latent_size))
target = -np.ones(batch_size) ## change 3
combined.train_on_batch(noise, target) W G A N 有 如 下 突 出 优 点 [ 6 ] :
* 训 练 稳 定 , 不 需 要 平 稳 生 成 器 和 判 别 器 。
* l o s s 值 与 生 成 样 本 质 量 相 关 , 可 以 用 来 监 督 训 练 进 程 , 不 需 要 人 工 判 断 干 预 。
完 整 的 示 例 可 以 参 见 r e p o 。 读 者 可 以 自 行 验 证 , D _ l o s s 及 生 成 图 像 的 质 量 变 化 。
4. GLSGAN
[ 7 ] 提 出 了 L o s s S e n s i t i v e G A N , 并 随 后 发 现 , 可 以 和 W G A N 在 统 一 的 框 架 下 研 究 , 即 g e n e r a l i z e d L S G A N ( 图 3 ) 。
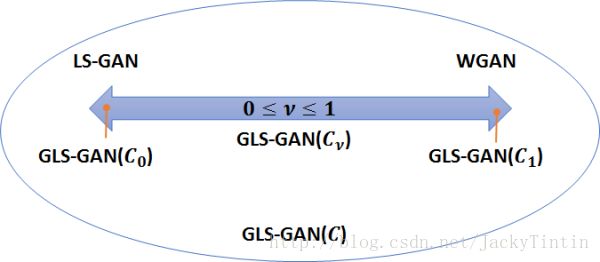
图 3 . 【 s r c 】
G L S G A N 使 用 L e a k y R e L U 作 用 激 活 , 其 中 s∈(−∞,1] 。
def build_discriminator():
model = Sequential()
model.add(Flatten(input_shape=(1, 28, 28)))
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(1), activation='linear')
model.add(LeakyReLU(slope)) ##
return model下 面 是 不 同 s 下 , 训 练 的 模 型 生 成 的 示 例 图 片 。

图 4 . S l o p e : 1 ( W G A N ) , E p o c h : 1 7 0

图 5 . S l o p e : 0 ( L o s s S e n s i t i v e G A N ) , E p o c h : 1 8 9

图 6 . S l o p e : - 1 ( L 1 L o s s ) , E p o c h : 3 9 9
非线性损失
G L S G A N 并 不 限 定 损 失 函 数 为 ( 分 段 ) 线 性 。 这 里 使 用 E x p o n e n t i a l L i n e a r U n i t ( E L U ) 。

图 7 . E x p o n e n t i a l L i n e a r U n i t v s . R e L U 【 s r c 】
def build_discriminator():
# Other Code goes here...
model.add(ELU) # Exponential Linear Unit
return model
图 8 . E L U , E p o c h : 3 6 7
一 个 完 整 的 示 例 见 r e p o 。 基 于 t o r c h 的 o f f i c i a l r e p o 。
5. 讨论
损失函数
损 失 函 数 唯 一 重 要 的 地 方 在 于 , 不 断 驱 动 两 个 网 络 的 竞 争 。 直 观 上 , 判 别 网 络 将 真 实 样 本 和 生 成 样 本 , 向 坐 标 轴 上 的 两 个 不 同 的 区 域 移 动 。
* 对 于 b a s i c G A N , 这 两 个 区 域 分 别 分 别 是 0 ( 生 成 ) 和 1 ( 真 实 ) , 使 用 的 损 失 函 数 是 对 数 函 数 ( f(x)=−log(x) ) ( 即 交 叉 熵 ) [ 1 ] 。
* 对 于 L e a s t S q u a r e d G A N , 这 两 个 区 域 分 别 是 a 和 b ( a < b ) , 使 用 的 损 失 函 数 是 二 次 函 数 ( f(x)=x2 ) [ 4 ] 。
* 对 于 W G A N , 这 两 个 区 域 分 别 +∞ ( 真 实 样 本 ) 和 −∞ ( 生 成 样 本 ) , 使 用 的 是 线 性 损 失 函 数 ( f(x)=x ) [ 6 ] 。
* 对 于 L o s s - S e n s i t i v e G A N , 这 两 个 区 域 分 别 是 +∞ ( 真 实 样 本 ) 和 (−∞,0] [ 7 ] , 使 用 的 是 R e L u 损 失 函 数 。
* 对 于 G e n e r a l i z e d L S G A N ( 0<γ<1 ) , 这 两 个 区 域 分 别 是 +∞ ( 真 实 样 本 ) 和 (−∞,0] [ 7 ] , 使 用 的 是 L e a k y R e L u 损 失 函 数 。
* 对 于 G e n e r a l i z e d L S G A N ( γ<0 ) , 这 两 个 区 域 分 别 是 +∞ ( 真 实 样 本 ) 和 0 [ 7 ] , 使 用 的 是 分 段 线 性 的 损 失 函 数 。
从 损 失 函 数 的 角 度 , B a s i c G A N 几 乎 选 择 了 一 个 最 差 的 方 案 — — 经 过 s i g m o i d 激 活 后 , 损 失 函 数 在 0 - 1 两 端 都 存 在 饱 和 区 。
关于GLSGAN
当 γ<0 时 , 从 形 式 上 , G L S G A N 其 实 已 经 不 能 叫 做 L o s s S e n s i t i v e 了 。 因 为 此 时 G L S G A N 的 行 为 更 向 是 L e a s t S q u a r e s G A N — — 将 生 成 样 本 向 某 个 点 推 ( 零 点 ) 。 不 过 G L S G A N 对 于 真 实 样 本 更 激 进 , 它 会 不 断 将 真 实 样 本 向 +∞ 推 。 另 一 个 不 同 是 , G L S G A N 使 用 线 性 的 函 数 , 而 L S G A N 使 用 二 次 函 数 。
T O D O 此 处 有 一 个 疑 问 待 解 决 : 文 章 中 说 L e a s t S q u a r e s G A N 也 存 在 梯 度 消 失 的 问 题 。 从 形 式 上 看 , 虽 然 一 次 函 数 在 极 值 附 近 梯 度 接 近 0 , 但 由 于 正 负 样 本 的 损 失 函 数 的 极 值 点 不 同 , 因 此 , 直 觉 上 , 在 对 抗 训 练 过 程 中 应 该 不 会 出 现 梯 度 消 失 的 现 象 。 看 到 需 要 进 一 步 提 高 理 论 修 养 。
Regularities
这 里 我 们 没 有 关 注 正 则 性 约 束 , 但 W G A N , G L S G A N 要 求 判 别 器 是 L i p s c h i t z ( 相 对 于 模 型 参 数 ) 。 直 观 上 , L i p s c h i t z 保 证 训 练 过 程 中 , 不 会 因 为 参 数 更 新 引 起 模 型 的 跳 跃 性 变 化 , 确 保 训 练 过 程 平 稳 。
6. 结语
- 形 式 上 , 各 种 方 法 仅 仅 是 损 失 函 数 不 太 一 样 , 但 损 失 函 数 的 选 择 并 不 t r i v i a l 。 b a s i c G A N 训 练 困 难 已 经 表 明 了 G A N 对 抗 的 训 练 方 式 对 损 失 函 数 的 非 常 的 敏 感 。 没 有 严 谨 的 理 论 支 撑 , 随 意 的 损 失 函 数 并 不 能 保 证 训 练 如 预 期 进 行 ( 收 敛 且 稳 定 ) 。
- 鲁 棒 的 G A N 训 练 方 法 对 于 G A N 在 广 阔 领 域 的 应 用 将 是 非 常 大 的 推 动 力 ( 如 最 近 的 压 缩 感 知 应 用 ) 。
- 对 不 同 损 失 函 数 ( 不 同 G A N ) 的 性 质 , 目 前 还 缺 少 系 统 性 的 比 较 研 究 , 期 待 更 新 的 研 究 结 果 。
References
- I a n G o o d f e l l o w e t a l . ( 2 0 1 4 ) . G e n e r a t i v e A d v e r s a r i a l N e t w o r k s .
- I a n G o o d f e l l o w . ( 2 0 1 6 ) . N I P S 2 0 1 6 T u t o r i a l : G e n e r a t i v e A d v e r s a r i a l N e t w o r k s .
- N o w o z i n e t a l . ( 2 0 1 6 ) . f - G A N : T r a i n i n g G e n e r a t i v e N e u r a l S a m p l e r s u s i n g V a r i a t i o n a l D i v e r g e n c e M i n i m i z a t i o n .
- M a o e t a l . ( 2 0 1 6 ) . L e a s t S q u a r e s G e n e r a t i v e A d v e r s a r i a l N e t w o r k s .
- A r j o v s k y e t a l . ( 2 0 1 6 ) . T o w a r d s P r i n c i p l e d M e t h o d s f o r T r a i n i n g G e n e r a t i v e A d v e r s a r i a l N e t w o r k s .
- A r j o v s k y e t a l . ( 2 0 1 7 ) . W a s s e r s t e i n G A N .
- Q i . ( 2 0 1 7 ) . L o s s - S e n s i t i v e G e n e r a t i v e A d v e r s a r i a l N e t w o r k s o n L i p s c h i t z D e n s i t i e s .
- A n I n c o m p l e t e M a p o f t h e G A N m o d e l s .
- L S - G A N : 把 G A N 建 立 在 L i p s c h i t z 密 度 上 .
- 广 义 L S - G A N ( G L S - G A N ) .
Further Reading
- A r o r a e t a l . ( 2 0 1 7 ) . G e n e r a l i z a t i o n a n d E q u i l i b r i u m i n G e n e r a t i v e A d v e r s a r i a l N e t s ( G A N s ) .
- A r o r a e t a l . ( 2 0 1 7 ) . D o G A N s a c t u a l l y l e a r n t h e d i s t r i b u t i o n ? A n e m p i r i c a l s t u d y .