【Learning Notes】Sequence Transducer
Sequence Transducer [1,2],是 CTC 的一个扩展,也是由 Alex Graves 提出。相比于 CTC,Transducer 1)可以同时建模输入和输出的条件依赖(CTC 不依赖于输出);2)对输入输出的长度没有限制(CTC 的输入长度不能小于输出)。这使得 Transducer 建模能力更加强大,理论上也可以解决更广泛的任务。
另一方面,Transducer 和 CTC 都假设输出输入的单调对应的(但不需要知道具体的对齐)。典型的问题场景是语音识别,语音序列和对应文本序列在时间上是严格一致。典型的反例是机器翻译,不同语言的语序可能会非常不同。
这里假设读者已经熟悉 CTC。关于 CTC,可以参见另一篇介绍及列出的参考文献。
1. 模型概览
这具体介绍 Transducer 之前,首先来看一下基于 Transducer 的模型是个什么样子。[1] 中的公式写的很明白,但不够直观,这里接合 [3] 时行明说。
典型的模型(RNN-T)如图1所示,包括 Predict Network(在解码时,也称为 Decoder)、Encoder(即 [1] 中的 Transcription Network)和 Joint Network([1] 中的 Output Density Function)。
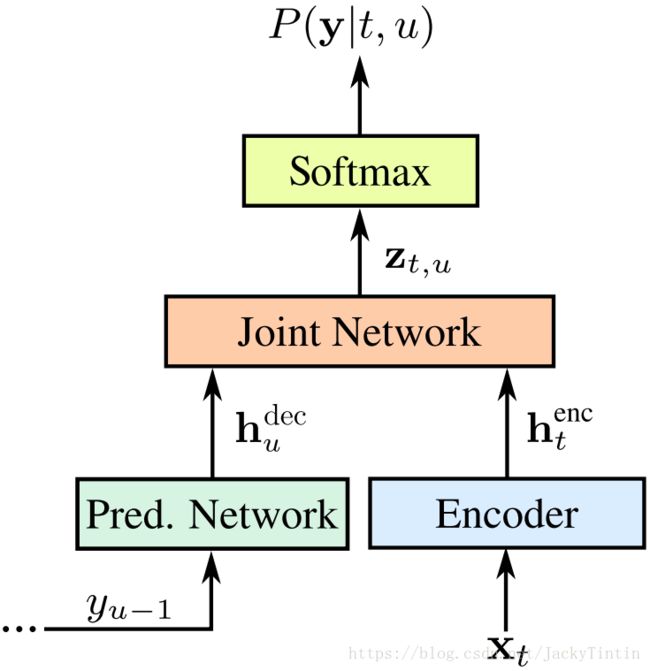
图1. RNN-Tansducer 模型[3]。
更具体的一个模型见图2。Predict 和 Encoder 都是若干层 LSTM,Joint Network 是 MLP(输入为 Predict Network 和 Encoder 输出的拼接,具体说明见下文)。

图 2. 一个具体的 RNN-Transducer 模型 [3]。
显然,只保留 Encoder,其输入接上 Softmax,就可以使用 CTC 进行训练了。 因此,Transducer 是一个更复杂的模型,或者说训练准则。
2. 输入输出对齐
为解决变长映入,CTC 1)引入了 blank;2)允许输出的 token 重复。这点上 CTC 非常类似 HMM,甚至可以说是一种特殊的 HMM 结构。也因此,CTC 既不能建模输出之间的条件依赖,也不适用于输入长度小于输出长度的问题。
Transducer 采用了不同变长对齐处理方式:1)引入特殊 token Φ Φ (NULL,即空输出),类似 CTC的 blank;2)输出中的每个 token 只会出现一次。这样,输入输出的对齐反映在适当的位置出现 Φ Φ 。概念上,Transducer 的一个对齐如图3所示。
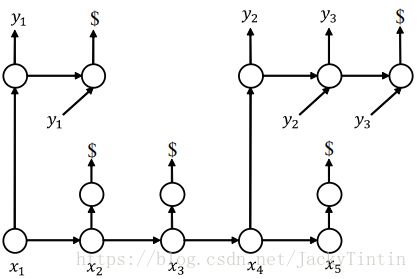
图3. Transducer 一个对齐示例[4]
3. 优化准则
对于一个具体的对齐,我们很容易可以计算其似然。在最大似然准则下,我们需要计算所有合法对齐的似然之和。显然,符合上述对齐准则的组合有指数多个。
CTC 中,由于输出概率独立,我们可以预计算出各个输入对应的输出概率分布,然后利用动态规划(前向后向算法)高效的计算似然及梯度,计算复杂度为 O(T⋅U) O ( T ⋅ U ) 。
那么,Transducer 也存在高效的方法吗?
答案是肯定的,但需要限定模型的结构。结果就是第二节介绍的 Joint 模型。
对于长度为 T 的输入序列,通过 Encoder 计算得到长度为 T 的编码序列:
计算复杂度为 O(T) O ( T ) 。
对于长度为 U 的输出序列,通过 Decoder(Predict Network) 计算得到长度为 U 的解码序列:
计算复杂度为 O(U) O ( U ) 。
同时依赖于输入和输出的概率分布计算:
计算复杂度为 O(T⋅U) O ( T ⋅ U ) 。
一般 joint network 可以用一个简单 MLP 实现:
但显然,我们可以自由选择其他更复杂的模型。
在预计算 zt,u z t , u 的基础上,接合 Transducer 变长对齐的规则,可以利用动态规划,计算似然和梯度了,复杂度为 O(T⋅U) O ( T ⋅ U ) 。具体公式推导和算法实现和 CTC 非常类似(warp-transducer 就是基于 warp-ctc 实现的!),在此不再赘述。推导可以参考[1],基于 pytorch 的 Transducer Loss 参考实现。
之前关于 CTC 的文章也可以做为参考。
更通用、更复杂的 Transducer 有也许多,其中两个可以参见 [4,5]。
4. 解码
原理上,Transducer 的解码和 CTC 的解码并没本质的不同,但是由于存在输出的依赖关系,工程上会复杂一些。可以参见 gready decode 和 beam search 。
在语音识别任务中,Transducer 并不能像 CTC 一样与传统的 WFST 接合,在 first pass 解码中,不能利用长语言模型的好处。但另一方面,Transducer 的 predict network 本身就是一个神经语言模型,一定程度也缓解了这种劣势 [6]。
5. 相关代码
- warp-transducer (CPU/GPU)及 MXNet 绑定。
- C++ 实现及 tensorflow 绑定。
- C 实现及 pytorch 绑定,以及基于 python 的参考实现。
- 基于 RNN Transducer 的 音素识别(TIMIT) 示例。
References
- Graves. Sequence Transduction with Recurrent Neural Networks.
- Graves et al. Speech Recognition with Deep Recurrent Neural Networks.
- Rao et al. Exploring Architectures, Data and Units For Streaming End-to-End Speech Recognition with RNN-Transducer.
- Wang et al. Sequence Modeling via Segmentations.
- Jaitly et al. An Online Sequence-to-Sequence Model Using Partial Conditioning.
- Battenberg et al. Exploring Neural Transducers for End-to-End Speech Recognition.