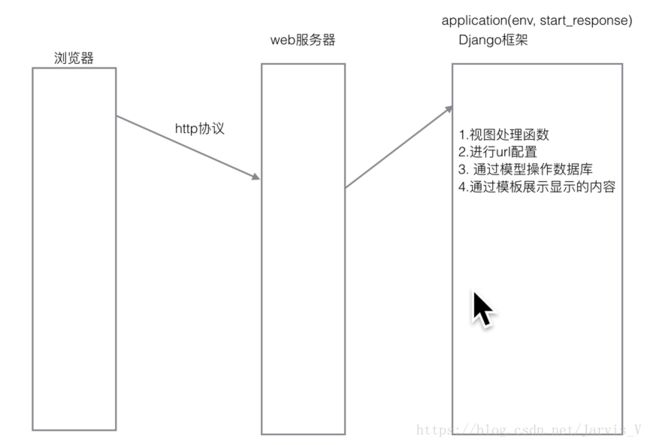
Django中的ORM模型
一、Djang的ORM框架
(一)ORM
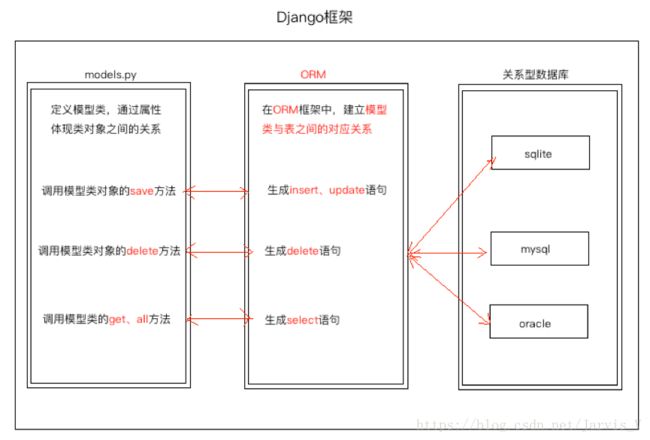
1、O(objects):类和对象。
2、R(Relation):关系,关系数据库中的表格。
3、M(Mapping):映射。
(二)ORM框架功能
1、建立模型类和表之间的对应关系,允许我们通过面向对象的方式来操作数据库。
2、根据设计的模型类生成数据库中的表格。
3、通过配置就可以进行数据库的切换
二、Django的数据库
(一)mysql数据库配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'HOST': '127.0.0.1', # 数据库主机
'PORT': 3306, # 数据库端口
'USER': 'root', # 数据库用户名
'PASSWORD': 'mysql', # 数据库用户密码
'NAME': 'django_demo' # 数据库名字
}
}
注意:Django不会给我们创建mysql数据库,这个数据库我们得先创建好。(注意指定charset=utf-8)
(二)切换数据库后不能启动服务器问题
1、需要安装mysql的包,
2、python2中:在虚拟环境下,pip install mysql-python
3、python3中,在虚拟环境下:pip install pymysql
注意:需要在项目的__init__.py中添加如下内容:
1⃣import pymysql
2⃣pymysql.install_as_MySQLdb()
三、重定向
(一)重定向定义
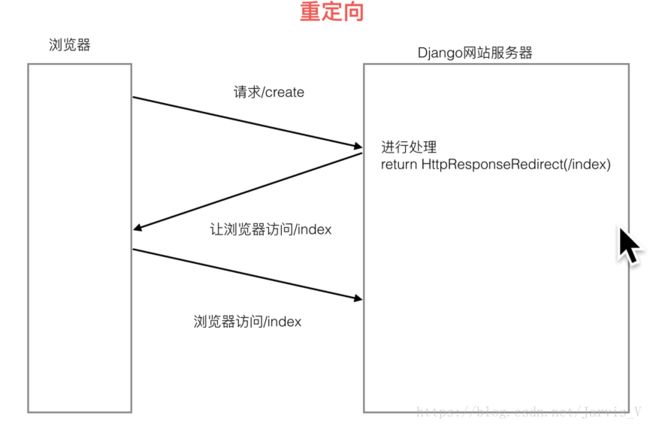
页面重定向:服务器不返回页面,而是告诉浏览器再去请求其他的url地址
(二)重定向例子
from django.shortcuts import render,redirect
from django.http import HttpResponseRedirect
def create(request):
b = BookInfo()
b.btitle = "流星蝴蝶剑"
b.bpub_date = date(1991,1,1)
b.save()
return HttpResponseRedirect("/") # 重定向
def delete(request, id):
book = BookInfo.objects.get(id=id)
book.delete()
return redirect('/') # 重定向
三、字段属性和选项
(一)模型类属性命名规则
1、不能用python保留字。
2、不允许使用连续的下划线,这是由django的查询方式决定的
3、定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下:属性名=models.字段类型(选项)
(二)字段类型
使用时需要引入:from django.db import models
| 类型 |
描述 |
| AutoField |
自动增长,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性。 |
| BooleanField |
布尔字段,值为True或False。 |
| NullBooleanField |
支持Null、True、False三种值。 |
| CharField(max_length=最大长度) |
字符串。参数max_length表示最大字符个数,必须写。 |
| TextField |
大文本字段,一般超过4000个字符时使用。 |
| IntegerField |
整数 |
| DecimalField(max_digits=None, decimal_places=None) |
十进制浮点数。参数max_digits表示总位。参数decimal_places表示小数位数。 |
| FloatField |
浮点数。参数同上 |
| DateField:([auto_now=False, auto_now_add=False]) |
1、参数auto_now表示每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false。 2、参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false。 3、参数auto_now_add和auto_now是相互排斥的,组合将会发生错误。 |
| TimeField |
时间,参数同DateField。 |
| DateTimeField |
日期时间,参数同DateField。 |
| FileField |
上传文件字段。 |
| ImageField |
继承于FileField,对上传的内容进行校验,确保是有效的图片。 |
(三)选项(实现字段的约束)
| 选项名 |
描述 |
| default |
设置默认值 |
| primary_key |
True:主键字段,默认值为false |
| unique |
True:字段中为唯一值,默认为false |
| db_index |
True:表中为此字段创建索引,默认为false |
| db_column |
字段的名称,如果未制定,则用属性的名称 |
| null |
True:表示允许为空,默认值为false |
| blank |
True:该字段允许为空白,默认为false |
1、null和blank对比:null是数据库范畴的概念,blank是后台管理页面表单验证范畴的。
2、当修改模型类之后,如果添加的选项不影响表的结构,则不需要重新做迁移,商品的选项中default和blank不影响表结构。
3、一般不需要记,参考文档:http://python.usyiyi.cn/translate/django_182/index.html
四、查询(重点)
(一)mysql日志文件
1、ubunto中:
1⃣打开mysql配置文件,去除68,69行的注释,然后保存。
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
2⃣重启mysql服务,就会产生mysql日志文件。
sudo service mysql restart
3⃣/var/log/mysql/mysql.log 是mysql日志文件所在的位置
4⃣sudo tail -f /var/log/mysql/mysql.log(不能用vi打开)
2、mac中:
1⃣mysql> set global general_log=on;
2⃣mysql> show variables like ‘general_log_file’;
3⃣sudo tail -f /usr/local/mysql/data/MacBook-Air.log 查看的绝对路径
4⃣注意:在vi中不能动态查看日志的内容。
(二)查询函数
通过模型类.objects属性可以调用如下函数,实现对模型类对应的数据表的查询。
| 函数名 |
功能 |
返回值 |
说明 |
| get |
返回表中满足条件的一条且只能有一条数据。 |
返回值是一个模型类对象 |
1、如果查到多条数据,则抛异常MultipleObjectsReturned。 2、查询不到数据,则抛异常:DoesNotExist。 |
| all |
返回模型类对应表格中的所有数据。 |
返回值是QuerySet类型 |
查询集 |
| filter |
返回满足条件的数据。 |
返回值是QuerySet类型 |
参数写查询条件。 |
| exclude |
返回不满足条件的数据 |
返回值是QuerySet类型 |
参数写查询条件。 |
| order_by |
对查询结果进行排序。 |
返回值是QuerySet类型 |
参数中写根据哪些字段进行排序。 |
<练习>
1、查询图书id为3的信息
2、查询图书所有的信息
3、模型类属性名__条件名=值
4、查询图书评论量为34的图书信息。
5、查询编号为1的图书
6、判等查询(exact)
例:查询编号为1的图书。
7、模糊查询(contains,endswith,startswich)
例1:查询书包含"传"的图书
例2:查询书名以“部”结尾的图书。
8、空查询(isnull)
例:查询书名不为空的图书
9、范围查询(in)
例:查询id为1,3,5的图书
10、比较查询(gt,lt,gte,lte)
例:查询d大于3的图书
11、日期查询(year,day等)
例:查询1980年发表的书
12、exclude方法和filter方法相:
例:查询id不为3的图书
13、order_by:进行结果集排序:order_by里装的是字符串
例:把id大于3的图书信息按阅读量从大到小排序显示。
(三)F对象(作用于类属性(字段)之间的比较) 如果只是字段,需要是字符串形式
使用之前必须先导入:from django.db.models import F
例:查询图书阅读量大于2倍评论量的图书信息
(四)Q对象(作用于查询时条件的之间的逻辑关系,&,|,~)
使用之前必须先导入:from django.db.models import Q
例1:查询id大于3或者阅读量大于30的图书的信息。
例2:查询id不等于3图书的信息。
BookInfo.objects.filter(~Q(id=3))
(五)聚合函数(对查询集进行聚合操作)
1、aggregate:调用这个函数来使用聚合,返回的是一个字典。
2、导入聚合类:from django.db.models import Sum,Count,Max,Min,Avg
例:查询所有图书阅读量的总和。
3、count:返回的是一个数字。
例:统计id大于3的所有图书的数目
BookInfo.objects.filter(id__gt=3).aggregate(Count('id'))
BookInfo.objects.filter(id__gt=3).count()

五、查询集
(一)查询集特性
1、惰性查询:只有在实际使用查询集中的数据的时候才会发生数据库真正的查询。
2、缓存:当使用的是同一个查询集时,第一次的时候会发生实际数据库的查询,然后把结果缓存起来,之后再使用这个查询集时,使用的是缓存中的结果。
(二)限制查询集
1、可以对一个查询集进行取下标或者切片操作来限制查询集的结果。
2、对一个查询集进行切片操作会产生一个新的查询集,下标不允许为负数。
3、查询集的两种方式。
| 方式 |
说明 |
| b[0] |
如果b[0]不存在,会抛出IndexError异常 |
| b[0:1].get() |
如果b[0:1].get()不存在,会抛出DoesNotExist异常 |
4、exists判断一个查询集中是否有数据。True,False
(三)模型类关系
1、一对多关系:(图书类->英雄类)
models.ForeignKey() 定义在多的类中
2、多对多关系:(新闻类->新闻类型剋)
models.ManyToManyField() 定义在哪个类中都可以
3、一对一关系:(员工基本信息类-员工详情信息类)
models.OneToOneField定义在哪个类中都可以
六、关联查询(一对多)
(一)查询和对象关联的数据
1、在一对多关系中,一对应的类我们把它叫做一类,多对应的那个类我们把它叫做多类,我们把多类中定义的建立关联的类属性叫做关联属性。
例1:查询id为1图书的英雄信息。
例2:查询id为1的英雄图书信息。

(二)通过模型类实现关联查询

1、通过多类条件查询一类的数据:
一类名.objects.filter(多类名小写__多类属性名__条件名)
2、通过一类的条件查询多类的数据:
多类名.objects.filter(关联属性__一类属性名__条件名)
例:查询图书信息,要求图书关联的英雄的描述包含'八'。
BookInfo.objects.filter(heroinfo__hcomment__contains="八")
例:查询图书信息,要求图书中的英雄的id大于3
BookInfo.objects.filter(heroinfo__id__gt=3)
例:查询书名为“天龙八部”的所有英雄。
HeroInfo.objects.filter(hbook__btitle="天龙八部")
(三)自关联
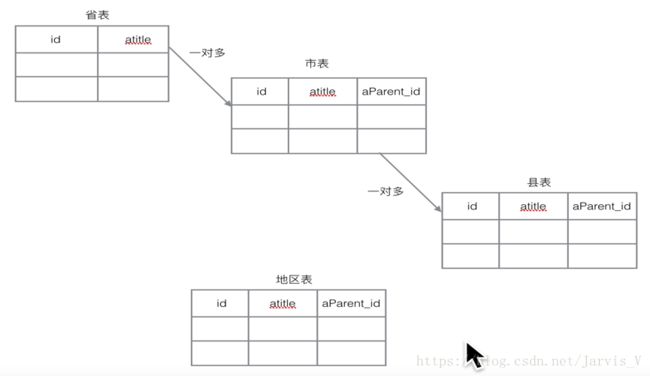
1、自关联是一种特殊的一对多关系。
例:显示广州市的上级地区和下级地区。
七、管理器(重点)
(一)objects是什么?
1、objects是Django帮我自动生成的管理器对象,通过这个管理器可以实现对数据的查询。
2、objects是models.Manger类的一个对象。自定义管理器之后Django不再帮我们生成默认的objects管理器。
(二)如何自定义管理器类?
1、自定义一个管理器类,这个类需要继承models.Manager类。
2、再进行定义一个管理器类的对象。
(三)自定义管理器类的应用场景
1、改变查询集的结果集:
比如说:用all方法查询的是全部数据,我们可以通过重写all 方法来实现,返回的结果集是没有逻辑删除的。
2、添加额外的方法:
可以封装一些增删改的方法。
(四)self.model()用法
如果直接在自定义管理器中要使用类:b = BookInfo(),用b对象去实现增删改查,那么如果将模型类的名字修改后,就无法再在自定义管理器类中使用b对象,那么我们就需要用self.model()来创建出来一个b,无论你的模型类怎么改,都不影响。

八、元选项
1、Django默认生成的表名:应用名小写_模型类名小写。
2、如果想修改表名:需要在模型类中定义一个猿类Meta,在里面定义一个类属性db_table就可以指定表名。