python3网络爬虫:爬取煎蛋网美女照片
1.1 前言
今天开学不久,课也不多,就想着来做个爬虫,看着好多老司机喜欢看美女图片,想做个爬去煎蛋网的小爬虫。哈哈,下面开车了,各位,上车记得滴卡
参考: http://blog.csdn.net/c406495762
1.2,预备知识
为了也能够学习到新知识,本次爬虫教程使用requests第三方库,这个库可不是Python3内置的urllib.request库,而是一个强大的基于urllib3的第三方库。
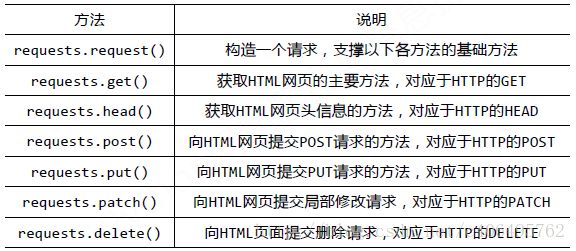
requests库的基础方法如下:
官方中文教程地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
因为官方给出的《快速上手》教程已经整理的很好了,并且本次教程使用的也是最简单的requests.get(),因此第三方库requests的使用方法,不再累述。详情请看官方中文教程,有urllib2基础的人,还是好上手的。
2.1 requests安装
在cmd中,使用如下指令安装第三方库requests:
pip3 install requests- 1
或者:
easy_install requests2.2 爬取单页目标连接
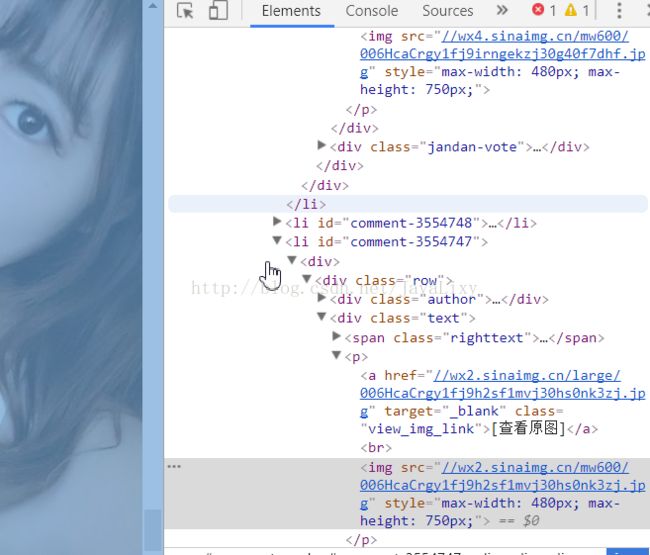
通过审查元素,我们不难发现,目标的地址存储在class属性为”view_img_link”的标签的href属性中。。因此,先获取目标的地址,也就是我们点击图片之后,进入的网页地址,然后根据下一个网页,找到图片的地址。
代码:
from bs4 import BeautifulSoup
import requests
if __name__ == '__main__':
url = 'http://jandan.net/ooxx'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
req = requests.get( url,headers = headers)
req.encoding = 'utf-8'
html = req.text
bf = BeautifulSoup(html, 'lxml')
targets_url = bf.find_all(class_='view_img_link')
list_url = []
for each in targets_url:
list_url.append(str(each.get('href')))
print(list_url)运行结果:地址不包括前面的http协议,后面再来将它补上

2.3 爬取多页目标连接
翻到第二页的时候,很容易就发现地址变为了:www.http://jandan.net/ooxx/page-2#comments。第三页、第四页、第五页依此类推。
。
代码:
from bs4 import BeautifulSoup
import requests
if __name__ == '__main__':
for num in range(75,80):
if num == 1:
url = 'http://jandan.net/ooxx'
else:
url = 'http://jandan.net/ooxx/page-%d#comments' % num
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
req = requests.get( url,headers = headers)
req.encoding = 'utf-8'
html = req.text
bf = BeautifulSoup(html, 'lxml')
targets_url = bf.find_all(class_='view_img_link')
list_url = []
for each in targets_url:
list_url.append(str(each.get('href')))
print(list_url)运行结果如上,只是增加了多页的地址
2.4 整体代码
已经获取到了每张图片的连接,我们就可以下载了。整合下代码,下载图片。
代码:from bs4 import BeautifulSoup
from urllib.request import urlretrieve
import requests
import os
import time
import re
if __name__ == '__main__':
list_url = []
for num in range(78,80):
if num == 1:
url = 'http://jandan.net/ooxx'
else:
url = 'http://jandan.net/ooxx/page-%d#comments' % num
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
req = requests.get(url = url,headers = headers)
req.encoding = 'utf-8'
html = req.text
bf = BeautifulSoup(html, 'lxml')
targets_url = bf.find_all(class_='view_img_link')
for each in targets_url:
list_url.append('http://'+each.get('href').replace('//',''))
print(list_url)
for target_url in list_url:
filename = ''+str(time.localtime())+'.jpg'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
img_req = requests.get(url = target_url,headers = headers)
img_req.encoding = 'utf-8'
img_html = img_req.text
img_bf = BeautifulSoup(img_html, 'lxml')
if 'images2' not in os.listdir():
os.makedirs('images')
urlretrieve(url = target_url,filename = 'images/'+ filename )
time.sleep(1)
print('下载完成!')运行结果:

list_url.append('http://'+each.get('href').replace('//',''))将原有的网址改编
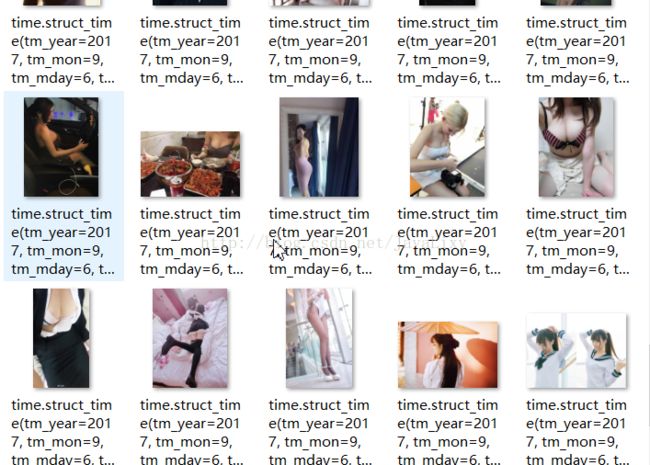
利用os库将图片保存在同个目录下的image文件
如下:
截止到2017/11/28号,煎蛋网的图片链接已加密,这个代码运行不了了,仅供参考学习