bm25 算法
推荐阅读:
http://www.minerazzi.com/tutorials/okapi-bm25-model.pdf
http://www.minerazzi.com/tutorials/probabilistic-model-tutorial.pdf
http://www.staff.city.ac.uk/~sb317/papers/foundations_bm25_review.pdf
http://www.tao-sou.com/744.html
https://nlp.stanford.edu/IR-book/html/htmledition/okapi-bm25-a-non-binary-model-1.html
bm25算法全名是Best Match 25,在BM系列中还有其他公式,它一般用作计算当前查询的输入文本与文档的相关度。BM25的一般公式如下:

这篇文章的公式都是取自于推荐阅读里面的论文,本文只是简单翻译一下,公式的符号比较多,看下去的朋友需要耐心。各个符号的定义如下:

一、F4
F4是一个全局相关度权重,为什么叫F4呢,因为它也是属于一个系列的,称为RSJ模型,这个模型主要基于两个问题,一是词项是否出现在文档中,二是词项与文档是否相关,基于这两个问题,得出下面的表

各个符号的定义
r 包含词项的相关文档的个数
n-r 包含词项的非相关文档的个数
n 包含词项的总文档的个数
R-r 不包含词项的相关文档的个数
N-n-R+r 不包含词项的不相关文档的个数
N-n 不包含词项的文档个数
R 相关文档的个数
N-R 不相关文档的个数
N 总文档的个数
对于其他RSJ模型有兴趣可以看看第二个链接,总而言之,F4就是在这堆比例里面诞生的,它主要衡量了词项的相关文档和非相关文档的几率。 然而,如果要预测模型的话,只要这四个组成部分任意一个为0,那么计算值就失去意义。因此一般考虑加上平滑系数k,变身之后的公式为
然而,如果要预测模型的话,只要这四个组成部分任意一个为0,那么计算值就失去意义。因此一般考虑加上平滑系数k,变身之后的公式为![]() 这里的话k一般取值为0.5。
这里的话k一般取值为0.5。
二、L(i,j)
L(i,j)表示基于文档的相关度权重。在计算这一部分的时候,文档的长度对于词频,往往起到一定的影响作用。一篇文章越长,词频越大,然而并不代表它的相关度会更大。因此必须对词频进行一个归一化的处理。这里词频作为分子还是f(i,j),分母定义为B。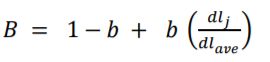 dl代表文档长度,dl(ave)代表所有文档的平均长度,b为惩罚系数,代表长度对文档的惩罚力度,b越大,长度对文档的惩罚越大。
dl代表文档长度,dl(ave)代表所有文档的平均长度,b为惩罚系数,代表长度对文档的惩罚力度,b越大,长度对文档的惩罚越大。
接下来对于所有的词频f(i,j)进行归一化, 带入开篇的第一个公式的L(i,j)里面,好奇的朋友们拿起笔计算一下。最后处理得到下面公式,这里的k1就是第一个公式里面的k。
带入开篇的第一个公式的L(i,j)里面,好奇的朋友们拿起笔计算一下。最后处理得到下面公式,这里的k1就是第一个公式里面的k。
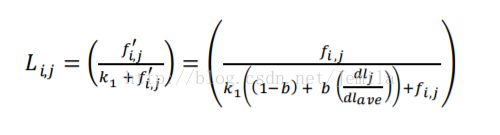
三、公式的变种
按照开篇第一个公式,将上面的L(i,j)和F4带入就可以,基本讲解就已经介绍完了。
但是在其他博客中会发现公式是不一样的,这里会有一些变种,常见的有两种。
第一种是对L(i,j)变种
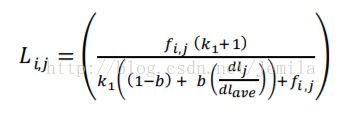 在公式上面出现了k(1)+1,加上它的原因是会使得和F4相乘之后更加兼容,如果此时f(i,j)=1,b=0,那么L(i,j)就会退化为1,而整个公式w(i,j)=F4。但是对于整体来说,k(1)+1是个常数,所以相关度的得分大小排名并不会出现变化。
在公式上面出现了k(1)+1,加上它的原因是会使得和F4相乘之后更加兼容,如果此时f(i,j)=1,b=0,那么L(i,j)就会退化为1,而整个公式w(i,j)=F4。但是对于整体来说,k(1)+1是个常数,所以相关度的得分大小排名并不会出现变化。
第二种是计算基于输入文本的相关度权重
还记得上面的F4和L(i,j)的意义么,一个是全局权重,一个是基于文档的相关度权重。此时如果一个输入文本很长的话,需要对其进行类似L(i,j)的处理,即右乘 k2在有的网页叫做k3,这里的qfi是词项在查询的输入文本里面的词频。当F4的k=0.5,整个公式就变成了
k2在有的网页叫做k3,这里的qfi是词项在查询的输入文本里面的词频。当F4的k=0.5,整个公式就变成了 当然,对于一般短文本的输入,词频只有一个,所以可以考虑省略。
当然,对于一般短文本的输入,词频只有一个,所以可以考虑省略。
四、其他
对于参数的大小,常用的是b=0.5,k1=2,范围是0.5 最后,整篇其实把词频都看作是f(i,j),但是词频还有另外一个名字tf,而不知道大家有没有去看第二个链接,F0其实就是IDF,所以BM25就是TF-IDF的变形。