一致性Hash算法介绍(分布式环境算法)
应用场景
2. 分布式缓存负载算法规则,缓存数据库扩容降低对之前原有缓存命中率的影响,对原有缓存服务器在负载都达到均衡。
... ...
名称解释
节点:可以是一台服务器
一致性哈希算法
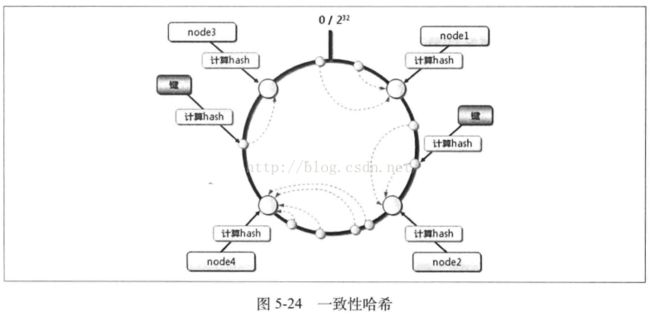
一致性哈希(Consistent Hashing),是MIT的Karger及其合作者在1997年发表的学术论文中提出的,很多做分布式系统的读者是在Amazon的dynamo论文中了解到一致性哈希的。图5-24展示了一致性哈希的含义。
一致性Hash算法那通过一个叫作一致性Hash环的数据结构实现KEY(键)到服务器(node节点)的Hash映射,如图5.24所示。
具体算法过程为:先构造一个长度为0~
2
32的整数环(这个环被称作一致性Hash环),根据节点名称的Hash值(其分布范围同样为0~2
32)将节点放置在这个Hash 环上。然后根据KEY值计算得到其Hash值(其分布范围也同样为0~2
32
),然后在Hash环上顺时针查找距离这个KEY的Hash值最近的节点,完成KEY到节点的Hash映射查找。
一致性哈希所带来的最大变化是
把节点对应的哈希值变为了一个范围,而不再是离散的。如果有节点加入,那么这个新节点会从原有的某个节点上分管一部分范围的哈希值;如果有节点退出,那么这个节点原来管理的哈希值会给它的下一个节点来管理。假设哈希值范围是从0到100,共有四个节点,那么它们管理的范围分别是[0,25)、[25,50)、[50,75)、[75,100]。如果第二个节点退出,那么剩下节点管理的范围就变为[0,25)、[25,75)、[75,100],可以看到,第一个和第四个节点管理的数据没影响,而第三个节点原来所管理的数据也没有影响,只需要把第二个节点负责的数据接管过来就行了。如果是增加一个节点,例如在第二个和第三个节点之间增加一个,则这五个节点所管理的范围变为[0,25)、[25,50)、[50,63)、 [63,75)、[75,100],可以看到,第一个、第二个、第四个节点没有受影响,第三个节点有部分数据也没受影响,另一部分数据要给新增的节点来管理。3台服务器扩容至4台服务器,可以继续命中原有缓存数据的概率是75%,远高于余数Hash的25%。100台服务器扩容增加1台服务器,继续命中的概率是99%。
具体应用中,这个长度为2
32 的一致性Hash环通常使用
二叉查找树实现,Hash查找过程实际上是在二叉査找树中查找不小于査找数的最小数值。当然这个二叉树的最右边叶子节点和最左边的叶子节点相连接,构成环。
从增加节点和减少节点的例子中觉察到了问题:新增一个节点时,除了新增的节点外,只有一个节点受影响,这个新增节点和受影响的节点的负载是明显比其他节点低的;减少一个节点时,除了减去的节点外,只有一个节点受影响,
它要承担自己原来的和减去的节点的工作,压力明显比其他节点要高。如果4台机器的性能是一样的,么这种结果显然不是我们需要的。这似乎要增加一倍节点或减去一半节点才能保持各个节点的负载均衡。如果真是这样,一致性哈希的优势就不明显了。
虛拟节点对一致性哈希的改进(解决负载不均衡问题)
计算机领域有句话:
计算机的任何问题都可以通过增加一个虚拟层来解决。计算机硬件、计算机网络、计算机软件都莫不如此。计算机网络的7层协议,每一层都可以看
作是下一层的虚拟层;计算机操作系统可以看作是计算机硬件的虚拟层;Java虚拟机可以看作是操作系统的虚拟层;分层的计算机软件架构事实上也是利用虚拟层的概念。
解决上述一致性Hash算法带来的负载不均衡问题,也可以通过使用虚拟层的手段:
将每个节点虚拟为一组虚拟节点,将虚拟节点的Hash值放置在Hash环上,KEY在环上先找到虚拟节点,再得到物理节点的信息。
这样新加入物理节点时,是将一组虚拟节点加入环中,如果虚拟节点的数目足够多,这组虚拟节点将会影响同样多数目的已经在环上存在的虚拟节点,这些已经存在的虚拟节点又对应不同的物理节点。
最终的结果是:新加入一个物理节点,将会较为均匀地影响原来集群中已经存在的所有节点,也就是说分摊原有节点在集群中所有节点的一小部分负载,其总的影响范围和上面讨论过的相同。
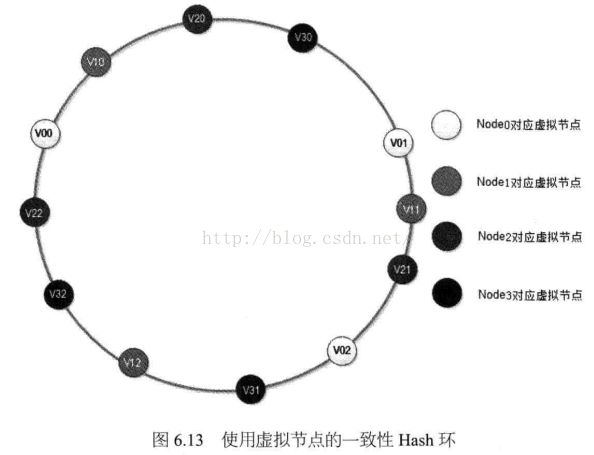
如图6.13所示。
在图6.13中,新加入节点NODE3对应的一组虚拟节点为V30,V31,V32,加入到 —致性Hash环上后,影响V01, V12, V22三个虚拟节点,而这三个虚拟节点分别对应 NODE0 NODE1, N0DE2三个物理节点。最终集群中加入一个节点,但是同时影响到集群中已存在的三个物理节点,在理想情况下,每个物理节点受影响的数据量 为其节点缓存数据最的1/4(X/(N+X)),N为原
有物理节点数,X为新加入物理节点数),也就是集群中已经被缓存的数据有75%可以被继续命中,和未使用虚拟节点的一致性Hash算法结果相同,只是解决的负载均衡的问题。
显然每个物理节点对应的虚拟节点越多,
各个物理节点之间的负载越均衡,新加入物理服务器对原有的物理服务器的影响越保持一致(这就是一致性Hash这个名称的由来)。那么在实践中,一台物理服务器虚拟为多少个虚拟服务器节点合适呢?太多会影响性能,太少又会导致负载不均衡,一般说来,经验值是
150,当然根据集群规模和负载均
衡的精度需求,这个值应该根据具体情况具体对待。
代码实现(Java):
https://github.com/JeromeSuz/demo_code_repo/blob/master/src/main/java/arithmetic/ConsistencyHash.java
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
|
import
java.io.UnsupportedEncodingException;
import
java.security.MessageDigest;
import
java.security.NoSuchAlgorithmException;
import
java.util.*;
/**
* 模拟一致性Hash算法
* 这段代码网上找的,输出各个节点的负载是差不多的,但是我在想可以自己写一个达到完全的负载均衡
* 比如:VIRTUAL_NODE_COUNT = 150
* 维护0~(2^32)/150的数字,新加入节点就取(2^32)/150内一个没有使用过的数,
* 然后在这个数的基础上面加150次的(2^32)/150可以生成150个分布均衡的虚拟节点。
* 如果有新增或者减少节点需要维护。
*
* @author [email protected]
* @date 2016/9/1 9:26
*/
public
class
ConsistencyHash {
// 环的所有节点
private
TreeMap
null
;
// 真实服务器节点
private
List
new
ArrayList();
// 设置虚拟节点数目
// 太多会影响性能,太少又会导致负载不均衡,一般说来,经验值是150,
// 当然根据集群规模和负载均衡的精度需求,这个值应该根据具体情况具体对待。
private
int
VIRTUAL_NODE_COUNT =
150
;
/**
* 初始化一致环
*/
public
void
init() {
// 加入五台真实服务器
realNodes.add(
"192.168.0.0-服务器0"
);
realNodes.add(
"192.168.0.1-服务器1"
);
realNodes.add(
"192.168.0.2-服务器2"
);
realNodes.add(
"192.168.0.3-服务器3"
);
realNodes.add(
"192.168.0.4-服务器4"
);
// 构造每台真实服务器的虚拟节点
allNodes =
new
TreeMap<>();
for
(
int
i =
0
; i < realNodes.size(); i++) {
Object nodeInfo = realNodes.get(i);
for
(
int
j =
0
; j < VIRTUAL_NODE_COUNT; j++) {
allNodes.put(hash(computeMd5(
"NODE-"
+ i +
"-VIRTUAL-"
+ j),
0
), nodeInfo);
// allNodes.put(hash(nodeInfo.toString() + j), nodeInfo);
}
}
}
/**
* 计算MD5值
*/
public
byte
[] computeMd5(String k) {
MessageDigest md5;
try
{
md5 = MessageDigest.getInstance(
"MD5"
);
}
catch
(NoSuchAlgorithmException e) {
throw
new
RuntimeException(
"MD5 not supported"
, e);
}
md5.reset();
byte
[] keyBytes =
null
;
try
{
keyBytes = k.getBytes(
"UTF-8"
);
}
catch
(UnsupportedEncodingException e) {
throw
new
RuntimeException(
"Unknown string :"
+ k, e);
}
md5.update(keyBytes);
return
md5.digest();
}
/**
* 根据2^32把节点分布到环上面
*
* @param digest
* @param nTime
* @return
*/
public
long
hash(
byte
[] digest,
int
nTime) {
long
rv = ((
long
) (digest[
3
+ nTime *
4
] &
0xFF
) <<
24
)
| ((
long
) (digest[
2
+ nTime *
4
] &
0xFF
) <<
16
)
| ((
long
) (digest[
1
+ nTime *
4
] &
0xFF
) <<
8
)
| (digest[
0
+ nTime *
4
] &
0xFF
);
return
rv & 0xffffffffL;
/* Truncate to 32-bits */
}
/**
* 根据key的hash值取得服务器节点信息
*
* @param hash
* @return
*/
public
Object getNodeInfo(
long
hash) {
Long key = hash;
SortedMap
if
(tailMap.isEmpty()) {
key = allNodes.firstKey();
}
else
{
key = tailMap.firstKey();
}
return
allNodes.get(key);
}
public
static
void
main(String[] args) {
ConsistencyHash consistencyHash =
new
ConsistencyHash();
consistencyHash.init();
// 循环50次,是为了取500个数来测试效果,当然也可以用其他任何的数据来测试
int
_0 =
0
;
int
_1 =
0
;
int
_2 =
0
;
int
_3 =
0
;
int
_4 =
0
;
Random ran =
new
Random();
for
(
int
i =
0
; i <
500
; i++) {
// 随便取一个数的md5
byte
[] ranNum = consistencyHash.computeMd5(String.valueOf(i));
// 分配到随即的hash环上面
long
key = consistencyHash.hash(ranNum,
2
);
// long key = consistencyHash.hash(ranNum, ran.nextInt(consistencyHash.VIRTUAL_NODE_COUNT));
// 获取他所属服务器的信息
// System.out.println(consistencyHash.getNodeInfo(key));
if
(consistencyHash.getNodeInfo(key).equals(
"192.168.0.0-服务器0"
)){
_0++;
}
else
if
(consistencyHash.getNodeInfo(key).equals(
"192.168.0.1-服务器1"
)){
_1++;
}
else
if
(consistencyHash.getNodeInfo(key).equals(
"192.168.0.2-服务器2"
)){
_2++;
}
else
if
(consistencyHash.getNodeInfo(key).equals(
"192.168.0.3-服务器3"
)){
_3++;
}
else
if
(consistencyHash.getNodeInfo(key).equals(
"192.168.0.4-服务器4"
)){
_4++;
}
else
{
System.out.println(
"error"
);
}
}
// 输出每台服务器负载情况
System.out.println(
"_0 = "
+ _0);
System.out.println(
"_1 = "
+ _1);
System.out.println(
"_2 = "
+ _2);
System.out.println(
"_3 = "
+ _3);
System.out.println(
"_4 = "
+ _4);
}
}
|
参考
1. 大型网站系统与Java中间件实践.pdf
2. 大型网站技术架构:核心原理与案例分析,李智慧.pdf