Spark 之 Streaming 学习笔记
目录
概述
关于 Spark Streaming
为什么学习 Spark Streaming
Spark Streaming 和 Storm 对比
核心概念
什么是DStream
DStream 相关操作
Transformations on Dstream
特殊的 Transformations
Output Operations on Dstream
StreamingContext
InputDStreams 和 Receivers
Spark Streaming 示例
概述
关于 Spark Streaming
Spark Streaming 类似于 Apache Storm,用于流式数据的处理。官方文档介绍,Spark Streaming 有高吞吐量和容错能力强等特点。Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。另外 Spark Streaming 也能和 MLlib(机器学习)以及 Graphx 完美融合。

Spark 的各个子框架,都是基于核心 Spark 的,Spark Streaming 在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过 Spark Engine 处理这些批数据,最终得到处理后的一批批结果数据。对应的批数据,在 Spark 内核对应一个 RDD实例,因此,对应流数据的 DStream 可以看成是一组 RDDs,即 RDD 的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine 从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。
总结:Spark Streaming 的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据
为什么学习 Spark Streaming
- 易用
- 容错
- 易整合到 spark 体系
Spark Streaming 和 Storm 对比
| Spark Streaming | Storm |
| 开发语言:scala,java | 开发语言:clojure,java 等 |
| 源码:scala | 源码:clojure |
| 编程模型:DStream | 编程模型:Spout/Bolt |
| 延迟:一定的延时,伪实时 | 延迟:亚秒级 |
总结:
1、延迟和吞吐量
Storm:
低延迟的,一次处理一条数据,真正意义上的实时处理。吞吐量小一点。
SparkStreaming:
微批处理,稍微有一些延迟性,一次处理的是一批数据,其实不是真正意义上的实时处理,准实时处理。吞吐量要大一点。
2、容错性
SparkStreaming:
容错性做得非常好。Driver,Executor,Receiver,Task,Block 数据丢失怎么办?(RDD)
Storm:
storm 的容错是基于 ack 组件完成。开销要比 SparkSreaming 大
核心概念
1、离散流(discretized stream)或 DStream:这是 Spark Streaming 对内部持续的实时数据流的抽象描述,即我们处理的一个实时数据流,在 Spark Streaming 中对应于一个 DStream 实例。
2、批数据(batch data):这是化整为零的第一步,将实时流数据以时间片为单位进行分批,将流处理转化为时间片数据的批处理。随着持续时间的推移,这些处理结果就形成了对应的结果数据流了。
3、时间片或批处理时间间隔(batch interval):这是人为地对流数据进行定量的标准,以时间片作为我们拆分流数据的依据。一个时间片的数据对应一个 RDD 实例。
4、窗口长度(window length):一个窗口覆盖的流数据的时间长度。必须是批处理时间间隔的倍数
5、滑动时间间隔:前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数
6、Input DStream:一个 InputDStream 是一个特殊的 DStream,将 Spark Streaming 连接到一个外部数据源来读取数据。
什么是DStream
Discretized Stream 是 Spark Streaming 的基础抽象,代表持续性的数据流和经过各种 Spark 原语操作后的结果数据流。在内部实现上,DStream 是一系列连续的 RDD 来表示。DStream 是连续数据的离散化表示,DStream 中每个离散片段都是一个 RDD,DStream 可以变换成另一个 DStream。
每个 RDD 含有一段时间间隔内的数据
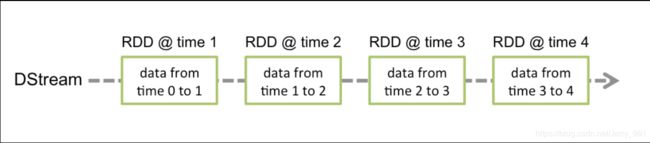
对数据的操作也是按照 RDD 为单位来进行的(计算过程由 Spark Engine 来完成)
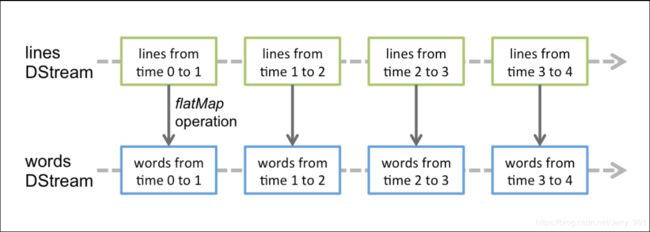
DStream 相关操作
DStream 上的原语与 RDD 的类似,分为 Transformations(转换)和 Output Operations(输出,和 RDD 的 action 操作类似)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种 window()相关的原语。
Transformations on Dstream

特殊的 Transformations
- UpdateStateByKey Operation
- Transform Operation
- Window Operations
(具体用法和细节参考官网或者搜相关博客,此处省略待后续整理)
Output Operations on Dstream
Output Operations 可以将 DStream 的数据输出到外部的数据库或文件系统,当某个 Output Operations 原语被调用时(与 RDD 的 Action 相同),Streaming 程序才会开始真正的计算过程。

StreamingContext
在 Spark Streaming 当中,StreamingContext 是整个程序的入口,其创建方式有多种,最常用的是通过 SparkConf 来创建:
package com.mazh.spark.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingContextTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("SCTest").setMaster("local[4]")
val streamingContext = new StreamingContext(sparkConf, Seconds(2))
}
}
源码中:
/**
* Create a StreamingContext by providing the configuration necessary for a new
* SparkContext.
* @param conf a org.apache.spark.SparkConf object specifying Spark parameters
* @param batchDuration the time interval at which streaming data will be divided
* into batches
*/
def this(conf: SparkConf, batchDuration: Duration) = {
this(StreamingContext.createNewSparkContext(conf), null, batchDuration)
}也就是说 StreamingContext 是对 SparkContext 的封装,StreamingContext 还有其它几个构造方法,感兴趣的可以了解,创建 StreamingContext 时会指定 batchDuration,它用于设定批处理时间间隔,需要根据应用程序和集群资源情况去设定。
当创建完成 StreamingContext 之后,再按下列步骤进行:
1、通过输入源创建 InputDStream
2、对 DStream 进行 transformation 和 output 操作,这样操作构成了后期流式计算的逻辑
3、 通过 streamingContext.start()方法启动接收和处理数据的流程
4、使用 streamingContext.awaitTermination()方法等待程序结束(手动停止或出错停止)
5、也可以调用 streamingContext.stop()方法结束程序的运行关于 StreamingContext 有几个值得注意的地方:
1、StreamingContext 启动后,增加新的操作将不起作用。也就是说在 StreamingContext 启动之前,要定义好所有的计算逻辑
2、StreamingContext 停止后,不能重新启动。也就是说要重新计算的话,需要重新运行整个程序。
3、在单个 JVM 中,一段时间内不能出现两个 active 状态的 StreamingContext
4、当在调用 StreamingContext 的 stop 方法时,默认情况下 SparkContext 也将被 stop 掉,如果希望 StreamingContext 关闭时,能够保留 SparkContext,则需要在 stop 方法中传入参数 stopSparkContext=false
5、一个 SparkContext 可以用来创建多个 StreamingContext,只要前一个 StreamingContext已经停止了。InputDStreams 和 Receivers
InputDStream 指的是从数据流的源头接受的输入数据流,在将来学习的 StreamingWordCount 程序当中,val lines = ssc.textFileStream(args(0)) 就是一种 InputDStream。除文件流外,每个InputDStream 都关联一个 Receiver 对象,该 Receiver 对象接收数据源传来的数据并将其保存在内存中以便后期 Spark 处理。
Spark Streaming 提供两种原生支持的流数据源和自定义的数据源:
1、Basic Sources(基础流数据源)
直接通过 StreamingContext API 创建,例如文件系统(本地文件系统及分布式文件系统)、Socket 连接及 Akka 的 Actor。
2、Advanced Sources(高级流数据源)
如 Kafka, Flume, Kinesis, Twitter 等,需要借助外部工具类,在运行时需要外部依赖(下一节内容中介绍)
3、Custom Sources(自定义流数据源)
Spark Streaming 还支持用户,它需要用户定义 receiver注意:
1、在本地运行 Spark Streaming 时,master URL 不能使用”local”或”local[1] ”,因为当 Input DStream 与 Receiver(如 sockets, Kafka, Flume 等)关联时,Receiver 自身就需要一个线程来运行,此时便没有线程去处理接收到的数据。因此,在本地运行 SparkStreaming 程序时,要使用”local[n]”作为 master URL,n 要大于 receiver 的数量。
2、在集群上运行 Spark Streaming 时,分配给 Spark Streaming 程序的 CPU 核数也必须大于receiver 的数量,否则系统将只接受数据,无法处理数据。
Spark Streaming 示例
(待整理)