Elasticsearch数据添加,查询
1 本文摘要
本文为《构建FAQ问题系统》的第二部分,主要讲解如何利用Kibaba在ES中建立索引,并向索引中添加数据,以及如何批量添加数据。并根据关键字进行相关查询和检索。
环境要求:
ubuntu16,Elasticsearch7.1.0,Kibana7.1.0,Elasticsearch-head
2 ES相关操作
文本中所以命令都是基于Kibana的Dev Tools来开发的,比使用命令行开发更方便和快捷。
2.1 ES新建,删除索引
①新建索引,最简单的方式:
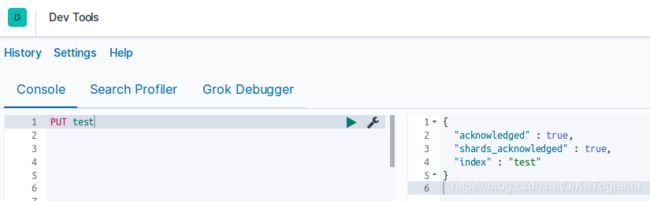 左侧为Dev Tools中输入的命令,右侧为ES返回的Json信息。新建索引的时候,索引名称不能包含大些字母,并且不能重复创建。
左侧为Dev Tools中输入的命令,右侧为ES返回的Json信息。新建索引的时候,索引名称不能包含大些字母,并且不能重复创建。
②指定参数创建索引
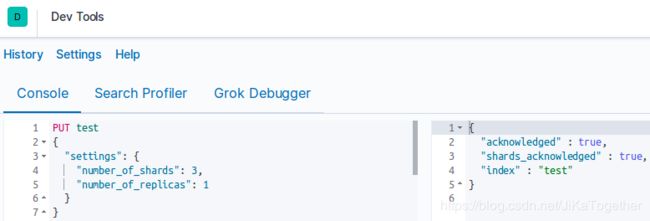 number_of_shards和number_of_replicas分别为分片数和副本数
number_of_shards和number_of_replicas分别为分片数和副本数
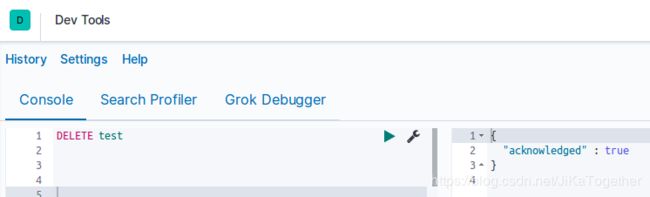
③删除索引
2.2 向索引中添加数据
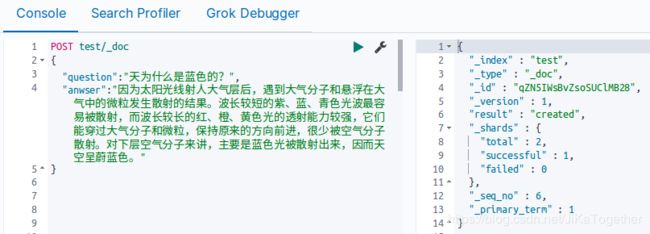
向test索引中添加一条数据,由于本文目的是构建FAQ问答系统,所以只存在qustion和anwser两个属性。
 批量添加数据:
批量添加数据:
首先按照以下格式要求,构建 test.json文件
{"index": {"_index": "test"}
{"question": "通过源码安装进行到第四步的时候空白", "anwser":"anwser1"}
{"index": {"_index": "test"}
{"question": "为什么windows一键安装包apache无法启动?", "anwser":"anwser2"}
{"index": {"_index": "test"}
{"question": "windows一键安装包默认的用户名和密码是什么?", "anwser":"anwser3"}
{"index": {"_index": "test"}}
{"question": "windows一键安装包无法开机自动启动", "anwser":"anwser4"}
{"index": {"_index": "test"}}
{"qustion": "安装的时候提示没有pdo扩展", "anwser":"anwser5"}
打开终端,进入test.json 所在文件夹,执行以下命令:
curl -XPOST "http://localhost:9200/_bulk?pretty" -H "Content-Type: application/json;charset=UTF-8" --data-binary @test.json
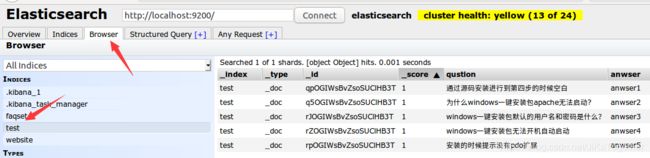
可以在elasticsearch-head插件页面点击Browser和索引名test就可以看到批量添加的内容:
2.3 查询与检索
在进行ES查询之前这里先介绍IK分词器插件,由于ES本身分词不支持中文的,本文主要介绍在中文领域内的相关应用,所有需要安装IK分词插件。在下面
https://github.com/medcl/elasticsearch-analysis-ik/releases 地址中下载ES对应版本的IK zip包,本文这里选择的是:
![]()
将下载的zip包解压并进行重命名,并移动到elasticsearch-7.1.0/plugins
unzip elasticsearch-analysis-ik-7.1.0.zip -d analysis-ik
mv analysis-ik ******/elasticsearch-7.1.0/plugins
重启ES,在Kibana Dev Tools中输入相关命令进行分词,分词结果如下:
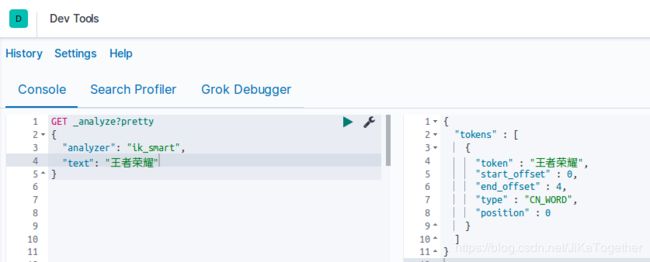
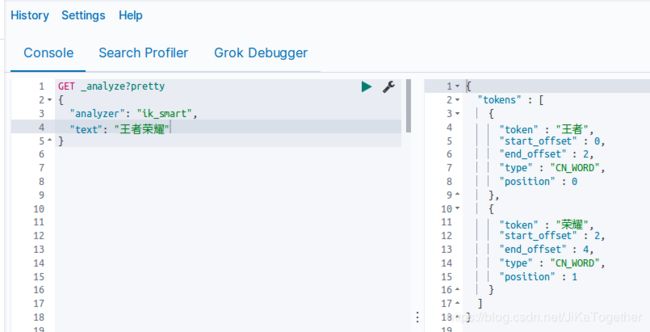 由上图可以得到,IK 分词器将王者荣耀分成“王者”和“荣耀”两个词语,但是在我们的理解中,“王者荣耀”是一款游戏名,应该分为一个词语,IK分词器也类似于结巴分词,可以添加自定义的词典。在elasticsearch-7.1.0/config/analysis-ik/custom 中新建new_word.dic文件,然后在文件中添加“王者荣耀”作为一行,再重启ES,重新进行分词:
由上图可以得到,IK 分词器将王者荣耀分成“王者”和“荣耀”两个词语,但是在我们的理解中,“王者荣耀”是一款游戏名,应该分为一个词语,IK分词器也类似于结巴分词,可以添加自定义的词典。在elasticsearch-7.1.0/config/analysis-ik/custom 中新建new_word.dic文件,然后在文件中添加“王者荣耀”作为一行,再重启ES,重新进行分词:
 同理,IK分词器还能够设置停用词,在elasticsearch-7.1.0/config/analysis-ik/stopword.dic 中添加停用词。IK分词器的其他用法还请自己查询;
同理,IK分词器还能够设置停用词,在elasticsearch-7.1.0/config/analysis-ik/stopword.dic 中添加停用词。IK分词器的其他用法还请自己查询;
查询:
回到建立索引的时候来,在前面的介绍中只是介绍了比较简单的创建方法,在FAQ问答的过程中都需要利用中文的分词,因此在建立索引的时候要制定分词的工具,类型等,如下所示:
PUT test
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 5
},
"mappings": {
"properties": {
"question":{
"type":"text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"anwser":{
"type":"text"
}
}
}
}
创建索引后再批量的添加FAQ数据,具体操作在上面介绍过,然后在进行查询:
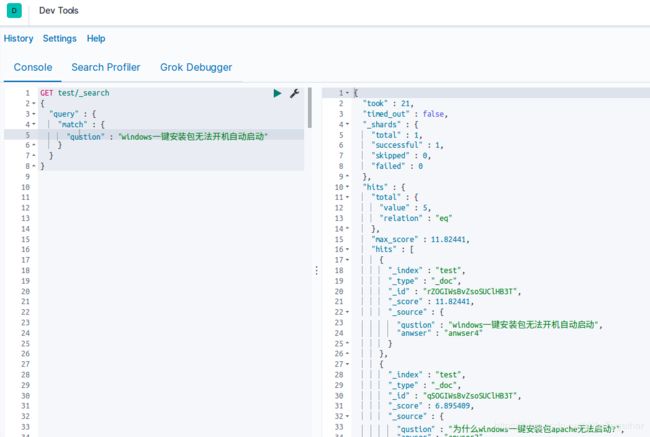 输入需要想查询的问题“windows一键安装包无法开机自动启动”,默认会返回10个得分最高的数据,相关更为复杂的查询方法match,term,bool的相关用法还请自行学习。在ES返回十个相似的句子后,后面会利用语义匹配的相关技术来做精确匹配,返回正确的结果。
输入需要想查询的问题“windows一键安装包无法开机自动启动”,默认会返回10个得分最高的数据,相关更为复杂的查询方法match,term,bool的相关用法还请自行学习。在ES返回十个相似的句子后,后面会利用语义匹配的相关技术来做精确匹配,返回正确的结果。
因此,ES在FAQ问答过程中只是起到召回的相关作用,语义匹配的相关算法后期再进行具体的分析。