Mondrian:建模多值维度属性
聚合类型:平均
一位名叫布鲁诺的生动读者最近在阅读了我关于桥牌表的文章之后联系了我:他正在寻找一个具有挑战性的场景的解决方案 任务是为学生创建一个模型,为他们参加的课程取得成绩。学生可以有一个或多个爱好,其中一个分析问题是:有爱好X的学生参加Y课程的平均成绩是多少?这引起了我的兴趣,我很想知道如何用Mondrian实现这一点。
在我们的示例中,我们使用以下数据:
- 学生鲍勃参加了数学课程并获得了7分(成绩)。他还参加了物理课程并获得了3分(成绩)。鲍勃的爱好是游戏和阅读。
- 学生Lilian参加了数学课程并获得了8分(成绩)。她的爱好是游戏,慢跑和写作。
虽然我有一些想法,但只有与Nelson Sousa的谈话才能找到一个可行的解决方案:他建议创建两个单独的事实表,一个存储每个学生每个课程的成绩(当然你也会有一个约会,但我们为了简单而忽略它清酒)。另一个事实表只存储学生和爱好关系。后者不一定必须在事实表本身中有一个度量,但是,为了完整起见我添加了一个(值的常量1)。最后,有一个学生维度作为两个事实表之间的链接:
multivalued.dim_student:
student_tk |
student_name |
|---|---|
| 1 | 短发 |
| 2 | 莉莲 |
multivalued.fact_grades:
student_tk |
course_name |
grade |
|---|---|---|
| 1 | 数学 | 7 |
| 1 | 数学 | 4 |
| 1 | 物理 | 3 |
| 2 | 数学 | 8 |
multivalued.fact_student_hobbies:
student_tk |
hobby_name |
cnt |
|---|---|---|
| 1 | 赌博 | 1 |
| 1 | 读 | 1 |
| 2 | 赌博 | 1 |
| 2 | 跑步 | 1 |
| 2 | 写作 | 1 |
创建标准多维数据集以回答简单的问题
这里重要的一点是,我们希望使用平均类型的聚合函数(因为成绩不能求和):
立方体定义:
我们为每个事实表创建了一个多维数据集来回答具体问题:
问:学生的平均成绩是多少?
SELECT
[Student.Student Name].Children ON ROWS
, [Measures].[Grade] ON COLUMNS
FROM [Grades]结果:
| 学生姓名 | 平均等级 |
|---|---|
| 短发 | 4.667 |
| 莉莲 | 8 |
问:课程的平均成绩是多少?
SELECT
[Course Name].Children ON ROWS
, [Measures].[Grade] ON COLUMNS
FROM [Grades]结果:
| 课程名 | 平均等级 |
|---|---|
| 数学 | 6.333 |
| 物理 | 3 |
问:有多少学生将游戏作为业余爱好?
SELECT
NON EMPTY [Student.Student Name].Members ON ROWS
, [Measures].[Count Hobbies] ON COLUMNS
FROM [Hobbies]
WHERE
[Hobby Name].[Gaming]结果:
| 学生姓名 | 伯爵爱好 |
|---|---|
| 所有学生。学生姓名 | 2 |
| 短发 | 1 |
| 莉莲 | 1 |
创建虚拟多维数据集以回答复杂问题
然后我们可以创建一个虚拟多维数据集来回答跨越两个事实表的问题。我们将这个立方体称为Grades and Hobbies。
我建议阅读虚拟多维数据集上的官方 Mondrian Docu,了解如何构建虚拟多维数据集。
虚拟多维数据集:如何加入基础多维数据集
为此目的使用全局(符合)维度。在我们的例子中,Student维度链接两个事实表,并定义为全局维度。
重要说明:请注意,对于公共维度,我们不定义
cubeName属性值。
问:这实际上是否也需要定义,CubeUsage因为在这种情况下VirtualCubeDimension元素没有为cubeName?指定值?否则,Mondrian如何知道这个全局维度存在于两个基础多维数据集中,并且因此可以使用它来加入基础多维数据集?
答:CubeUsage是可选的,不是必需的。如果你在引用一个全球性虚拟多维数据集,蒙德里安将检查所定义的基础多维数据虚拟措施,看看这个全球层面是在引用的基础多维数据集。
完整虚拟多维数据集定义:
让我们创建一个有爱好数量和平均成绩的学生列表:
SELECT
[Student.Student Name].Children ON ROWS
, {[Measures].[Grade], [Measures].[Count Hobbies]} ON COLUMNS
FROM [Grades and Hobbies]| 学生姓名 | 年级 | 伯爵爱好 |
|---|---|---|
| 短发 | 4.667 | 2 |
| 莉莲 | 8 | 3 |
以下结果显示了一个非常有趣的结果:爱好的数量仅在所有级别上可用,但是各个级别都可用:
SELECT
[Student.Student Name].Members * [Course Name].Members ON ROWS
, {[Measures].AllMembers} ON COLUMNS
FROM [Grades and Hobbies]| 学生姓名 | 课程名 | 伯爵爱好 | 年级 |
|---|---|---|---|
| 所有学生。学生姓名 | 所有课程名称 | 五 | 5.5 |
| 数学 | 6.333 | ||
| 物理 | 3 | ||
| 短发 | 所有课程名称 | 2 | 4.667 |
| 数学 | 5.5 | ||
| 物理 | 3 | ||
| 莉莲 | 所有课程名称 | 3 | 8 |
| 数学 | 8 | ||
| 物理 |
这是有道理的,因为爱好的数量只能在一个All Courses级别上提供,因为我们当然不存储它们!
让我们得到一个以游戏为业余爱好的学生名单:
SELECT
FILTER(
[Student.Student Name].Children
, (
[Hobby Name].[Gaming]
, [Measures].[Count Hobbies]
) > 0
) ON ROWS
, {} ON COLUMNS
FROM [Grades and Hobbies]结果:
| 学生姓名 |
|---|
| 短发 |
| 莉莲 |
问:Hobby的平均成绩是多少?
SELECT
[Course Name].Members ON ROWS
, {[Measures].[Grade]} ON COLUMNS
FROM [Grades and Hobbies]| 课程名 | 年级 |
|---|---|
| 数学 | 6.333 |
| 物理 | 3 |
学习练习
让我们回过头来了解一些基础知识:注意WHERE以下查询中的slicer():
WITH SET STUDENTS AS
FILTER(
[Student.Student Name].Children
, (
[Hobby Name].[Reading]
, [Measures].[Count Hobbies]
) > 0
)
SELECT
STUDENTS ON ROWS
, {[Measures].[Grade]} ON COLUMNS
FROM [Grades and Hobbies]
WHERE [Course Name].[Course Name].[Math]有趣的是,我们没有得到任何记录!但是,如果我们将限制从切片器移动到其中一个轴,那么一切都很好:
WITH SET STUDENTS AS
FILTER(
[Student.Student Name].Children
, (
[Hobby Name].[Reading]
, [Measures].[Count Hobbies]
) > 0
)
SELECT
STUDENTS * [Course Name].[Course Name].[Math] ON ROWS
, {[Measures].[Grade]} ON COLUMNS
FROM [Grades and Hobbies]结果:
| 学生姓名 | 课程名 | 年级 |
|---|---|---|
| 短发 | 数学 | 5.5 |
这样做的原因是切片器也直接影响计算成员和集合,而如果我们将约束移动到轴之一上,则计算成员和集合将在没有此约束的情况下进行评估。
或者,您也可以将All成员添加到过滤器以覆盖切片器中的约束:
WITH SET STUDENTS AS
FILTER(
[Student.Student Name].Children
, (
[Hobby Name].[Reading]
, [Course Name].[All Course Names]
, [Measures].[Count Hobbies]
) > 0
)
SELECT
STUDENTS ON ROWS
, {[Measures].[Grade]} ON COLUMNS
FROM [Grades and Hobbies]
WHERE [Course Name].[Course Name].[Math]这将产生完全相同的结果。
接下来让我们看一下原始问题:
问:参加数学课程并将游戏作为业余爱好的学生的平均成绩是多少?
此查询返回所有对游戏感兴趣并参加数学课程的学生:
WITH
SET STUDENTS AS
FILTER(
[Student.Student Name].Children
, (
[Hobby Name].[Gaming]
, [Measures].[Count Hobbies]
) > 0
)
SELECT
STUDENTS * [Course Name].[Course Name].[Math] ON ROWS
, {[Measures].[Grade]} ON COLUMNS
FROM [Grades and Hobbies]| 学生姓名 | 课程名 | 年级 |
|---|---|---|
| 短发 | 数学 | 5.5 |
| 莉莲 | 数学 | 8 |
我们现在尝试回答原始问题:
WITH
SET STUDENTS AS
FILTER(
[Student.Student Name].Children
, (
[Hobby Name].[Gaming]
, [Course Name].[All Course Names]
, [Measures].[Count Hobbies]
) > 0
)
SELECT
STUDENTS ON ROWS
, {[Measures].[Grade]} ON COLUMNS
FROM [Grades and Hobbies]
WHERE [Course Name].[Course Name].[Math]这里的诀窍是在获得课程成绩之前获得具有特定爱好的学生列表。另外,请注意我们将Math课程的约束移动到切片器(WHERE子句)中。由于这也影响了计算集,我们也必须明确地添加[Course Name].[All Course Names]它。
结果:
| 学生姓名 | 年级 |
|---|---|
| 短发 | 5.5 |
| 莉莲 | 8 |
聚合类型:SUM
在这个主题的变化中,我们想象我们是一个销售各种商品的公司。该客户有不同的利益,我们希望看到多少收入,我们产生的用户兴趣。我们不想权衡利益 - 我们将所有收入分配给每一个利益。目的是找出哪些利息产生了大部分收入(好吧,我们不会在这里做到这一点,但你会得到这个想法)。
multivalued.dim_client:
client_tk | client_name
-----------+-------------
1 | Joe
2 | Susan
3 | Timmultivalued.fact_client_interests:
client_tk | interest_name | cnt
-----------+---------------+-----
1 | Fishing | 1
1 | Photography | 1
1 | Cooking | 1
2 | Cooking | 1
2 | Biology | 1
3 | Geography | 1
3 | Photography | 1
3 | Cooking | 1multivalued.dim_product:
product_tk | product_name | unit_price
------------+--------------+------------
1 | AAA | 2.00
2 | BBB | 3.00
3 | CCC | 1.40multivalued.dim_date:
date_tk | the_date
----------+------------
20170324 | 2017-03-24multivalued.fact_sales:
date_tk | client_tk | product_tk | no_of_units | amount_spent
----------+-----------+------------+-------------+--------------
20170324 | 1 | 1 | 2 | 4
20170324 | 2 | 1 | 3 | 6
20170324 | 1 | 2 | 4 | 12
20170324 | 2 | 2 | 2 | 6
20170324 | 3 | 2 | 3 | 9
20170324 | 2 | 3 | 2 | 2.8
20170324 | 3 | 3 | 1 | 1.4多维数据集定义:在这种情况下,客户端是我们的全局维度,它链接两个多维数据集(销售和兴趣)。设置很简单,所以我不会详细说明:
我们为每个事实表创建了一个多维数据集来回答具体问题:
问:我们产品的收入是多少?
SELECT
[Product.Product Name].Children ON ROWS
, {[Measures].[Number of Units], [Measures].[Revenue]} ON COLUMNS
FROM [Sales]| 产品名称 | 单位数 | 收入 |
|---|---|---|
| AAA | 五 | 10.00 |
| BBB | 9 | 27.00 |
| CCC | 3 | 4.20 |
问:我们为每位用户带来多少收入?
select
[Client.Client Name].Children ON ROWS
, {[Measures].[Number of Units], [Measures].[Revenue]} ON COLUMNS
FROM [Sales]| 客户名称 | 单位数 | 收入 |
|---|---|---|
| 乔 | 6 | 16.00 |
| 苏珊 | 7 | 14.80 |
| 蒂姆 | 4 | 10.40 |
问:有多少客户对烹饪感兴趣?
SELECT
NON EMPTY [Client.Client Name].Members ON ROWS
, [Measures].[Count Interests] ON COLUMNS
FROM [Interests]
WHERE
[Interest Name].[Cooking]| 客户名称 | 数利益 |
|---|---|
| 所有Client.Client名称 | 3 |
| 乔 | 1 |
| 苏珊 | 1 |
| 蒂姆 | 1 |
我们还创建了一个虚拟立方体来回答涉及两个立方体的问题。
问:用户对摄影有多大兴趣?
让我们先获得相关客户的列表:
SELECT
FILTER(
[Client.Client Name].Children
, (
[Interest Name].[Interest Name].[Photography]
, [Measures].[Count Interests]
) > 0
) ON ROWS
, {} ON COLUMNS
FROM [Sales and Interests]然后构造最终查询:
WITH
SET CLIENTS AS
FILTER(
[Client.Client Name].Children
, (
[Interest Name].[Interest Name].[Photography]
, [Product.Product Name].[All Product.Product Names]
, [Measures].[Count Interests]
) > 0
)
SELECT
CLIENTS ON ROWS
, {[Measures].[Revenue]} ON COLUMNS
FROM [Sales and Interests]
WHERE [Product.Product Name].[Product Name].[AAA]| 客户名称 | 收入 |
|---|---|
| 乔 | 4.00 |
| 蒂姆 |
有效措施
在某些情况下,您可能希望显示数字,即使在当前选择中它们不可用。拿这个senario:
当我们选择Date,Client而且Product Name我们可以看到值Number of Units和Revenue,但不适用于Count Interests:
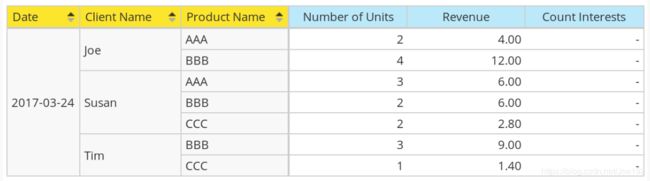
如果我们想要查看Count Interests数字,但必须选择Client Name和Interest作为维度,但在这种情况下Number of Units并且Revenue是空的:
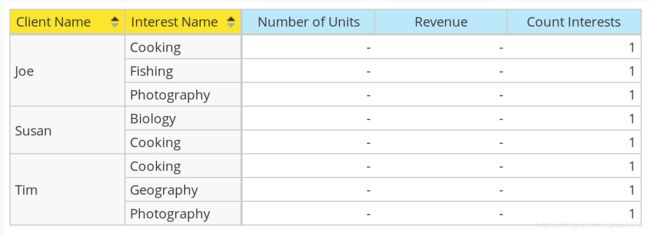
现在让我们假设我们想要显示最接近的Number of Units,Revenue在这种情况下,我们如何实现这一点。我们知道最接近的可用数字是总数Client Name,所以基本上这个数字会重复几次。如果这确实是可以接受的行为,那么与业务用户一起确认是值得的。
要实现此操作,请将原始虚拟度量设置为不可见,并使用函数在虚拟多维数据集中创建计算成员,这些函数应引用原始虚拟度量。它应该是这样的:ValidMeasure()
基于此新虚拟多维数据集的报告将如下所示:

在Joe的例子中,我们知道他对烹饪,钓鱼和摄影很感兴趣,总共购买了6个单位,总收入为16。
虚拟多维数据集:非规范化事实表
虚拟立方体依赖于全局维度,但是,如果您处理非规范化事实表,则可能使用退化维度。那么这是否意味着您无法为它们创建虚拟多维数据集?不完全的。你可以欺骗系统:
只需为每个简并表(例如vw_dim_location)创建一个视图,并在全局dim的表引用中使用它。