串行加法器 并行加法器 超前进位加法器
1.串行加法器
串行加法器即加法器执行位串行行操作,利用多个时钟周期完成一次加法运算,即输入操作数和输出结果方式为随时钟串行输入/输出。位并行加法器速度高,但是占用资源多。在许多实际应用中并不需要这样高的速度,而是希望减少硬件资源占用率,这时就可以使用位串行加法器。
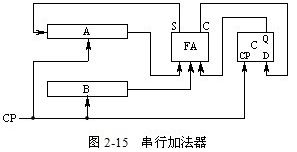
在串行加法器中,只有一个全加器,数据逐位串行送入加法器进行运算,如图所示。图中FA是全加器,A、B是两个具有右移功能的寄存器,C为进位触发器。由移位寄存器从低位到高位逐位串行提供操作数相加。如果操作数长n位,加法就要分n次进行,每次产生一位和,并串行地送回A寄存器。进位触发器用来寄存进位信号,以便参与下一次的运算。
2.串行进位的并行加法器
并行加法器由多个全加器组成,其全加器个数的多少取决于机器的字长,由于并行加法器可同时对数据的各位相加,读者可能会认为数据的各位能同时运算,其实并不是这样的。这是因为虽然操作数的各位是同时提供的,但低位运算所产生的进位会影响高位的运算结果。例如:11…11和00…01相加,最低位产生的进位将逐位影响至最高位,因此,串行进位的并行加法器需要一个最长运算时间,它主要是由进位信号的传递时间决定的,而每个全加器本身的求和延迟只是次要因素。很明显,提高并行加法器速度的关键是尽量加快进位产生和传递的速度。
并行加法器中的每一个全加器都有一个从低位送来的进位输入和一个传送给高位的进位输出。通常将传递进位信号的逻辑线路连接起来构成的进位网络称为进位链。每一位的进位表达式为:
Ci=AiBi+(Ai⊕Bi)Ci-1
其中,“AiBi”取决于本位参加运算的两个数,而与低位进位无关,因此称AiBi为进位产生函数(本次进位产生),用Gi表示,其含义是:若本位的两个输入均为1,必然要向高位产生进位。“(Ai⊕Bi)Ci-1”则不但与本位的两个数有关,还依赖于低位送来的进位,因此称Ai⊕Bi为进位传递函数(低位进位传递),用Pi表示,其含义是:当两个输入中有一个为1,低位传来的进位Ci-1将向更高位传送,所以进位表达式又可以写成:
Ci=Gi+PiCi-1
把n个全加器串接起来,就可进行两个n位数的相加。这种加法器称为串行进位的并行加法器,如图2-16所示。串行进位又称行波进位,每一级进位直接依赖于前一级的进位,即进位信号是逐级形成的。
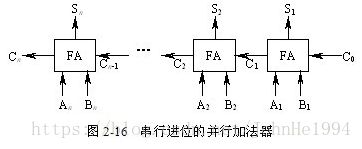
其中:C1=G1+P1C0
C2=G2+P2C1
…
Cn=Gn+PnCn-1
串行进位的并行加法器的总延迟时间与字长成正比,字长越长,总延迟时间就越长。假设将一级与门、或门的延迟时间定为ty,从上述公式中可以看出,每一级全加器的进位延迟时间为2ty。在字长为n位的情况下,若不考虑Gi、Pi的形成时间,从C0→Cn的最长延迟时间为2nty(设C0为加法器最低位的进位输入,Cn为加法器最高位的进位输出)。
显然,串行进位方式的进位延迟时间太长了,要提高加法运算的速度,就要尽可能地减少进位延迟时间,也就是要改进进位方式,这就产生了并行进位方式和分组并行进位方式。
3.超前进位加法器
可以想象最简单的加法计算就是每一位都进行一次全加器计算,然后产生一个进行c,下一个全加器在取得进位以后再进行他的位的计算,循环下去直到最后一位。这样的问题是进行一次32位的加法计算就需要至少串行的经过32个全加器,如果CPU的频率是3Ghz,那么一个时钟周期,大约333皮秒内,是无法完成一次简单的加法运算的。
那么超前进位加法器是如何做到高速计算的,可以想象肯定是把计算平行化了,而且是用数量来换了速度。但是具体是怎么做的呢。我们来一起分析下。
首先考虑所有的加法情况
| Row | x | y | cin | cout | s |
| 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 0 | 1 |
| 2 | 0 | 1 | 0 | 0 | 1 |
| 3 | 0 | 1 | 1 | 1 | 0 |
| 4 | 1 | 0 | 0 | 0 | 1 |
| 5 | 1 | 0 | 1 | 1 | 0 |
| 6 | 1 | 1 | 0 | 1 | 0 |
| 7 | 1 | 1 | 1 | 1 | 1 |
ci+1 = xiyi + xici + yici
这里c表示的是进位,举个列子来说就是第一位的进位c1他是由第零位的x0*y0+x0*c0+y0*c0, 这里很明显c0是始终为0的。那么c1=x0*y0
然后这个提取公因子公式就变成了
ci+1 = xiyi + ci(xi + yi)
然后是不是发现,这样一来只有ci是不确定的。其他的xi和yi都是直接输入。
但是ci其实呢通过循环inline的一个替换,其实会变成类似Ci+1 = Xiyi + (Xi + yi)(Xi-1yi-1 + Ci-1(Xi-1 + yi-1))
然后可以一直这样替换下去,直到c0这一层。或者是最右端的输入。
一般的通常会把这几个变量成为g,p变量
gi = xiyi
pi = xi + yi
这样理论上可以实现任何位数都在有限次内完成,但是这样的代价是位数越多需要的电路也就越多。
以四位超前加法器为例:
第一步,所有的4个全加器对每一位计算出自身的和Si, gi和pi
然后第二步,超前进位器计算出c1,c2,c3,c4,当然这里的c1,c2,c3,c4计算需要的逻辑门数量是逐步递增的。
然后c1,c2,c3对S1,S2,S3进行进位,C4会传递给更上面的位。
但是由于成本的问题一般都会把32位或者64位的切割成多个16位的超前进位来进行计算,能保证在一个时钟周期内完成基本就可以了。
取得一个成本和性能上得平衡。
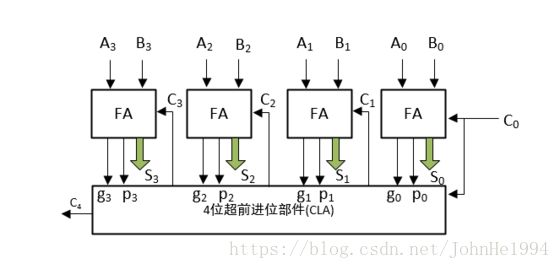
四位超前进位加法器
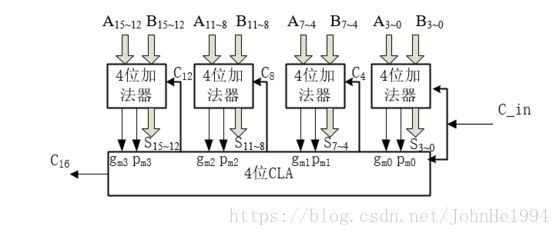
十六位超前进位加法器
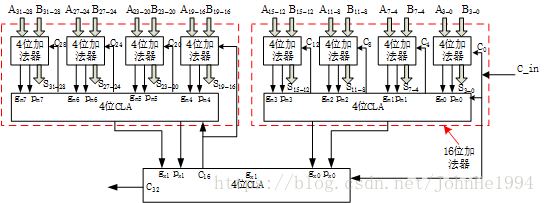
三十二位超前进位加法器