使用C调用Python,混合编程笔记
使用C调用Python,混合编程笔记
目的
1.由于微博网页结构再次更新导致之前的微博爬虫版本已经不能使用,所以对Python爬虫进行了一次更新
2.学习下如何使用Python与C进行交互,即如何将Python嵌入C++程序中
3.记录下进行此项工程时遇到的几个坑,以及如何结果/规避
前段时间实习工作的时候有听过Electron架构,本来是想学习一波的,但是由于对nodejs了解实在太少,想进行下去难度还是挺大的,不过如果是Python和C结合的话应该没啥问题,于是就开始这个小项目啦
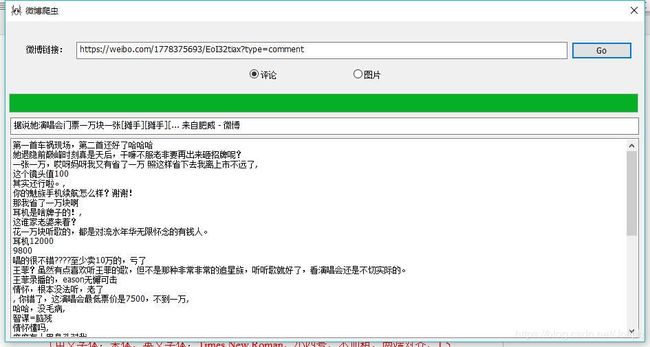
完整代码地址:
https://github.com/joliph/WeiboSpiderGUI
TIPS:
1.Python文件的main函数会在导入时执行,最好别有main函数/稳定执行的代码,避免不必要的时间浪费
2.学习Python/C API最好的地方当然是他们的官方文档啦,选择合适的Python版本,查看API介绍即可,附上网址:Python/C API Reference Manual
使用C++调用Python模块的流程:
- 设置好工程选项
First : 确保编译的EXE版本需要和安装的Python版本对应,即若你安装的是X64的Python则只能生产X64的EXE
Second : Python与C交互主要用到的是Python/C的相关API,这个API基本都存在于…/Python27/include类似这样的文件目录下,一定要把这个目录添加到附加包含目录中去
Third : 需要包含 python27.lib/python36.lib 文件,代码中要手动添加,然后再将此文件复制到工程目录下,同时再复制一个副本改名为python27_d.lib/python36_d.lib 以便debug模式使用 - 初始化Python虚拟机环境
Py_SetPythonHome("C:\\Python27"); //这里设置Python.exe所在的目录
Py_Initialize(); //初始化Python虚拟机
PyModule = PyImport_ImportModule((const char *)"PythonSpider"); //导入你写的Python模块
/*异常处理根据实际情况编写*/
- 从模块中导入你所需调用的函数
PyObject* PyCatchWeiboContent = PyObject_GetAttrString(PyModule, "CatchWeiboContent");
- 将C类型的对象转换为Python类型的对象准备传给Python作为参数
PyObject* PyParam = Py_BuildValue("(s)", "123456789advvv");
- 带参调用获取的函数并取得返回值
PyObject* PyContent = PyObject_CallObject(PyCatchWeiboContent, PyParam);
- 根据实际情况将PyObject对象转为C类型
PyArg_Parse()/PyArg_ParseTuple()...
几个较难解决的问题
- 返回列表类型的PyObject对象如何处理
参考链接: List Objects
//使用PyList_Size()获取返回的列表大小
CommentsListLen = PyList_Size(PyList);
//使用PyList_GetItem()获取列表元素
PyObject* TempItem = PyList_GetItem(PyList, index);
//按照常规方式进行类型转换
- 编码问题
先参考链接了解下编码的基础知识:https://blog.csdn.net/Deft_MKJing/article/details/79460485
Python3的话默认为utf-8编码,与C的编码方式不一导致乱码问题
不太好解决,所以这里吧Python3切换为Python2版本然后开头确定编码格式为GB18030,
同时确保.py文件本身的编码也是如此。就可解决中文乱码问题
- PyImport_ImportModule返回NULL
import requests
用python单独导入时并没有出错,但是使用C导入此python模块时出错了,报的错误信息是:
ImportError: cannot import name _remove_dead_weakref
解决方式....并没有好的解决方式 2.7.14~2.7.12都会出现此问题,换成2.7.10就没问题了